FastChat 是一个开源的 大模型训练与部署框架,由 LMFlow 团队开发,旨在帮助用户轻松训练、评估和部署类 ChatGPT 的对话模型。它支持多种开源大模型,并提供 Web UI、API 服务、模型评估 等功能,适用于研究人员和开发者快速搭建自己的对话系统。
🔗 FastChat GitHub: https://github.com/lm-sys/FastChat
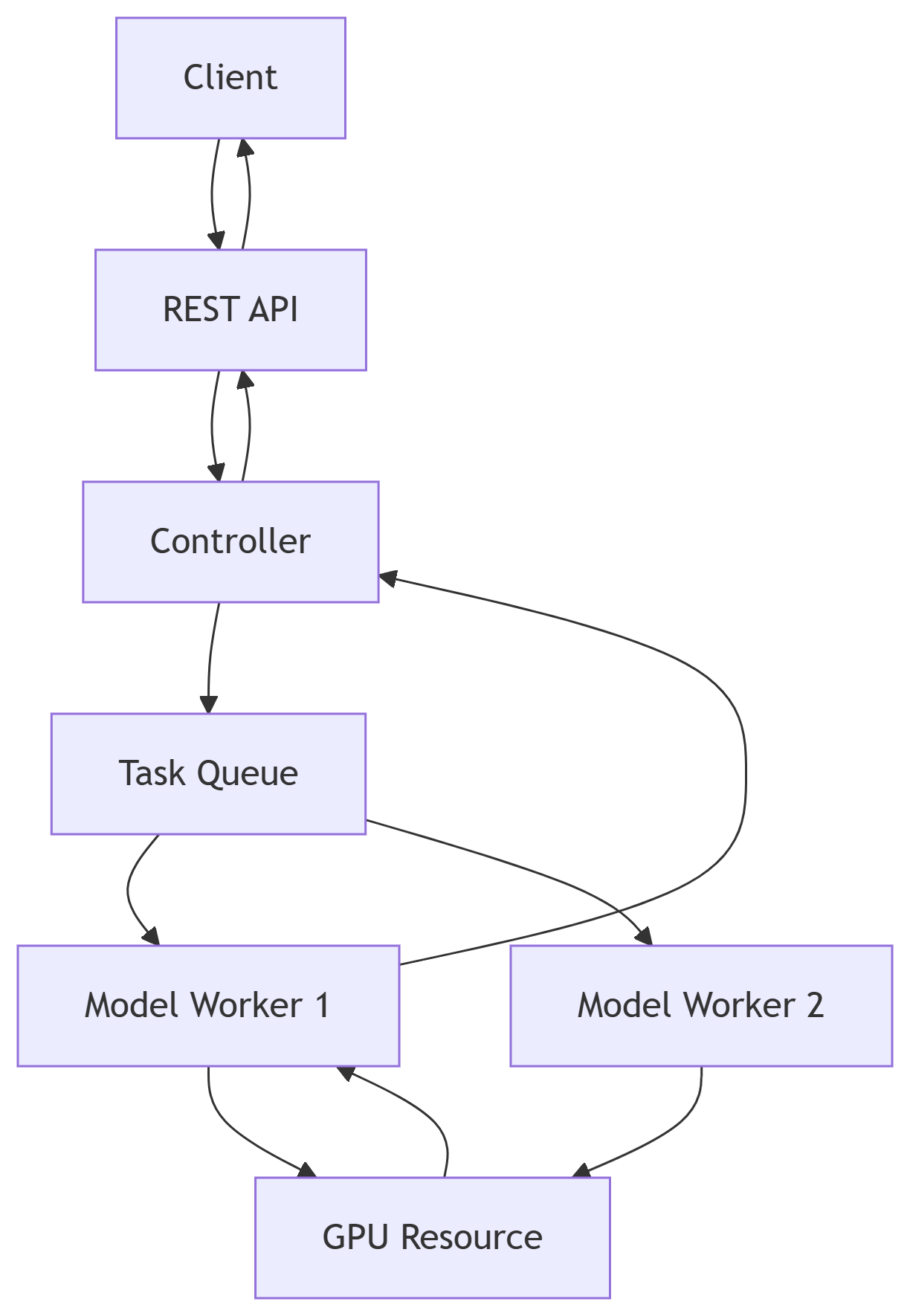
1. FastChat 架构 #
1.1 核心组件 #
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Client │ │ Controller │ │ Model Worker │
│ (Web/API/CLI) │◄──►│ (协调中心) │◄──►│ (模型推理节点) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
▲ ▲ ▲
│ │ │
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ REST API │ │ Task Queue │ │ GPU/CPU资源 │
│ (FastAPI/Flask) │ │ (Redis/Celery) │ │ (PyTorch/LLM) │
└─────────────────┘ └─────────────────┘ └─────────────────┘1.2 数据流 #
- 客户端请求 → REST API
- 用户通过Web/CLI发送请求(如
/generate)。
- 用户通过Web/CLI发送请求(如
- API → Controller
- 控制器分配任务到空闲的
Model Worker。
- 控制器分配任务到空闲的
- Controller → Task Queue
- 异步任务队列管理负载均衡。
- Model Worker → GPU/CPU
- 执行模型推理(如Vicuna、LLaMA等)。
- 结果返回
- 原路返回至客户端。
2.准备服务器 #
pip3 install "fschat[model_worker,webui]"3. 启动调度中心 #
3.1 启动命令 #
python -m fastchat.serve.controller
2025-07-17 12:15:07 | INFO | controller | args: Namespace(host='localhost', port=21001, dispatch_method='shortest_queue', ssl=False)
# 服务器进程已启动,进程ID为1857
2025-07-17 12:15:07 | ERROR | stderr | INFO: Started server process [1857]
# 正在等待应用初始化
2025-07-17 12:15:07 | ERROR | stderr | INFO: Waiting for application startup.
# 应用启动完成
2025-07-17 12:15:07 | ERROR | stderr | INFO: Application startup complete.
2025-07-17 12:15:07 | ERROR | stderr | INFO: Uvicorn running on http://localhost:21001 (Press CTRL+C to quit)python -m fastchat.serve.controller是启动 FastChat 控制器的命令,它是 FastChat 服务架构的核心调度组件。控制器参数:
host='localhost':控制器绑定到本地回环地址port=21001:控制器监听 21001 端口dispatch_method='shortest_queue':使用"最短队列"的任务分配策略ssl=False:未启用 SSL 加密
- 服务运行信息:
- 控制器正在
Uvicorn ASGI服务器上运行 - 可通过访问
http://localhost:21001与控制器交互 - 按 CTRL+C 可停止服务
- 控制器正在
3.2 控制器的核心功能 #
任务调度:
- 管理所有注册的模型工作节点(model_worker)
- 根据
dispatch_method分配用户请求:shortest_queue:选择待处理请求最少的工作节点- 其他可能策略:轮询(round-robin)等
状态维护:
- 跟踪所有工作节点的状态和负载
- 处理工作节点的注册和注销
API服务:
- 提供 RESTful API 接口供客户端调用
- 管理对话会话状态
3.3 典型工作流程 #
- 先启动控制器
- 启动一个或多个 model_worker
- 最后启动 Web 界面或 API 服务器
- 用户请求 → 控制器 → 分配给 worker → 返回结果
3.4 注意事项 #
- 控制器本身不加载模型,只负责调度
- 默认情况下只允许本地访问(host='localhost')
- 在生产环境中应考虑启用 SSL(ssl=True)
- 如需外部访问,需将 host 改为 '0.0.0.0'
4. 启动模型服务 #
4.1 启动命令 #
# 安装阿里云 ModelScope 的 Python SDK,用于从 ModelScope 下载模型
# 如果网络不稳定,可以尝试使用 -i https://pypi.tuna.tsinghua.edu.cn/simple 指定清华镜像源。
pip install modelscope
# 在本地创建一个目录 vicuna-7b-v1.5,用于存放下载的 vicuna-7b-v1.5 模型文件,vicuna-7b-v1.5 约 12GB
mkdir vicuna-7b-v1.5
# 指定的模型和下载到哪个本地的目录
modelscope download --model AI-ModelScope/vicuna-7b-v1.5 --local_dir ./vicuna-7b-v1.5
# 启动 FastChat 的 `model_worker`,加载vicuna-7b-v1.5 并提供推理服务。
python -m fastchat.serve.model_worker --model-path ./vicuna-7b-v1.54.2 运行流程 #
- FastChat 会读取
./vicuna-7b-v1.5下的模型文件。 - 加载模型到 GPU(如果可用),否则使用 CPU。
- 注册到
controller(需提前启动controller)。
4.3 常见问题* #
- CUDA 内存不足:
- 如果显存不足(< 16GB),可以尝试量化加载:
或使用 4bit 量化:python -m fastchat.serve.model_worker --model-path ./vicuna-7b-v1.5 --load-8bitpython -m fastchat.serve.model_worker --model-path ./vicuna-7b-v1.5 --load-4bit
- 如果显存不足(< 16GB),可以尝试量化加载:
- 未启动 controller:
- 需要先启动
controller,否则model_worker无法注册:python -m fastchat.serve.controller
- 需要先启动
4. 启动 OpenAI API 服务 #
python -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 80004.1. 命令参数说明 #
| 参数 | 作用 | 默认值 | 示例 |
|---|---|---|---|
--host |
绑定 IP 地址 | localhost |
0.0.0.0(允许外部访问) |
--port |
监听端口 | 8000 |
8000 或自定义端口 |
--controller-address |
控制器地址 | http://localhost:21001 |
若 controller 不在本地需修改 |
4.2. API 接口说明 #
FastChat 的 API 完全兼容 OpenAI API 格式,支持以下关键端点:
4.2.1 聊天补全(Chat Completions) #
- 路径:
POST /v1/chat/completions - 请求示例:
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model":"vicuna-7b-v1.5","messages": [{"role": "user", "content": "hello"}],"max_tokens": 100,"temperature": 0.7}' - 参数:
model: 模型名称(需与model_worker注册的名称一致)messages: 对话历史(格式:{"role": "user", "content": "..."})temperature: 控制生成随机性(0~1,越高越随机)
4.2.2 (2) 模型列表 #
- 路径:
GET /v1/models curl http://localhost:8000/v1/models- 返回示例:
{ "object": "list", "data": [{"id": "vicuna-7b-v1.5", "object": "model"}] }
4.3. 常见问题 #
Q1: 访问 http://localhost:8000 无响应
- 检查是否启动成功(日志是否显示
Uvicorn running on)。 - 确保
controller和model_worker已运行。
Q2: 返回 "model not found"
- 确认
model_worker注册的模型名称与 API 请求中的model参数一致。
Q3: 高并发下崩溃
- 增加
--worker-limits或使用多 GPU 部署多个model_worker。
4.4. 应用场景 #
- 本地开发调试:
import openai openai.api_base = "http://localhost:8000/v1" response = openai.ChatCompletion.create(model="vicuna-7b-v1.5", messages=[...]) - 集成到 LangChain:
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(api_base="http://localhost:8000/v1", model="vicuna-7b-v1.5")
5. 启动Web服务 #
python -m fastchat.serve.gradio_web_serverpython -m fastchat.serve.gradio_web_server 是 FastChat 提供的 基于 Gradio 的 Web 聊天界面,允许用户通过浏览器与本地部署的大模型(如 vicuna-7b-v1.5、Vicuna 等)交互。以下是完整解析:
5.1. 命令基本用法 #
python -m fastchat.serve.gradio_web_server [参数]常用参数
| 参数 | 作用 | 默认值 |
|------|------|--------|
| --host | 绑定 IP 地址 | localhost |
| --port | 监听端口 | 7860 |
| --controller-address | 控制器地址 | http://localhost:21001 |
| --concurrency-count | 并发请求数 | 10 |
| --share | 生成公网可访问链接 | False |
5.2. 功能特性 #
(1) 多模型切换
- 自动检测所有注册到
controller的模型,以下拉菜单形式供用户选择。
(2) 对话模式
- 单轮对话:直接输入问题获取回答。
- 多轮对话:自动维护聊天历史上下文。
- 参数调节:
Temperature:控制生成随机性(0~1)Max tokens:限制生成长度
(3) 高级选项
- 系统提示词:自定义模型行为(如 "你是一个有帮助的助手")。
- 重置对话:清空当前聊天上下文。
5.3. 访问方式 #
启动后可通过以下方式访问:
- 本地访问:浏览器打开
http://localhost:7860d - 局域网访问:若指定
--host 0.0.0.0,同一网络设备可通过http://[你的IP]:7860访问。 - 公网访问(需配置
--share或反向代理):
会生成一个临时的公网链接(如python -m fastchat.serve.gradio_web_server --sharehttps://xxxx.gradio.live)。