1.RAG简介 #
RAG(Retrieval-Augmented Generation,检索式增强生成)是一种结合了“检索”与“生成”两种能力的自然语言处理(NLP)技术,常用于问答系统、智能助手等场景。
1.1 参考 #
- PyMuPDF
- python-docx
- openpyxl
- python-pptx
- beautifulsoup4
- lxml
- csv
- sentence_transformers
- numpy
- RAGFlow
- collections
- jsonl
- jieba
- rank_bm25
- huggingface
- 魔搭社区
- 问答数据集
- all-MiniLM-L6-v2
1.2 安装依赖 #
pip install PyMuPDF python-docx openpyxl python-pptx beautifulsoup4 lxml sentence_transformers numpy chromadb requests jieba rank_bm251.3 大模型的局限性 #
- 知识更新滞后:大模型的训练数据具有时效性,难以及时反映最新的事实和动态信息。
- 缺乏专有领域知识:对于企业内部、行业专属等私有知识,大模型通常无法覆盖,难以满足专业化需求。
- 存在内容幻觉:大模型有时会生成看似合理但实际错误的信息,容易造成误导和错误决策。
1.4 为什么选择RAG? #
提升答案准确性
RAG通过实时检索外部知识库中的相关信息,有效增强生成内容的准确性和权威性,避免模型“胡编乱造”。显著降低训练与维护成本
相较于完全依赖大规模数据训练的生成模型,RAG只需较少的训练数据即可实现高质量输出,大幅减少算力和数据投入。灵活应对新知识与变化
RAG具备极强的适应性,能够动态检索和利用最新的知识库内容,面对新领域、新事件时无需重新训练模型即可快速响应和生成相关答案。
1.5 RAG工作流程 #
1.5.1 步骤一:知识库构建 #
- 管理员将本地文档转化为可检索的向量,供后续问答使用。
1.5.2 步骤二:检索(Retrieval) #
- 用户输入一个问题(Query)。
- 系统将问题转化为向量(embedding),在知识库中检索与问题最相关的若干条文档或片段。
1.5.3 步骤三:生成(Generation) #
- 将检索到的内容与原始问题一起输入到生成式模型中。
- 生成式模型根据这些信息,生成更准确、更有依据的答案。
1.6 优势 #
- 知识可扩展:模型不需要记住所有知识,只需检索外部知识库,便于更新和扩展。
- 答案更有依据:生成的答案可以引用检索到的具体内容,提升可信度。
- 减少幻觉:降低生成模型“胡编乱造”的概率。
1.7 应用场景 #
- 智能问答(如企业知识库问答、法律咨询等)
- 智能客服
- 文档摘要与分析
- 代码检索与生成
1.8 长上下文和RAG #
1.8.1 Long Context(长上下文) #
直接将大量上下文(如长文档、历史对话等)整体输入到大模型,让模型在“记住”全部内容的基础上直接生成答案。
| 模型名称 | 上下文长度(token) | 备注说明 |
|---|---|---|
| GPT-3 (davinci) | 4,096 | OpenAI,早期主力模型 |
| GPT-3.5 (turbo) | 4,096 | OpenAI,API常用 |
| GPT-3.5-turbo-16k | 16,384 | OpenAI,16k版本 |
| GPT-4 (标准) | 8,192 | OpenAI,API标准版 |
| GPT-4-32k | 32,768 | OpenAI,API高配版 |
| GPT-4o | 128,000 | OpenAI,2024年发布,极大提升上下文窗口 |
| Claude 2 | 100,000 | Anthropic,长文本处理能力强 |
| Claude 3 (Opus) | 200,000 | Anthropic,2024年旗舰版 |
| Gemini 1.5 Pro | 1,000,000 | Google,百万级上下文,适合超长文档 |
| Llama 2 | 4,096 | Meta,开源大模型 |
| Llama 3 | 8,192 / 128,000 | Meta,8k为基础版,128k为高配版 |
| ChatGLM2-6B | 8,192 | 智谱AI,国产开源模型 |
| ChatGLM3-6B | 8,192 | 智谱AI,国产开源模型 |
| Qwen-72B | 32,768 | 通义千问,阿里巴巴 |
| Yi-34B | 32,000 | 零一万物,国产开源 |
| ERNIE Bot 4.0 | 8,192 | 百度文心一言 |
| 维度 | RAG(检索增强生成) | Long Context(长上下文) |
|---|---|---|
| 知识容量 | 理论上无限(依赖外部知识库) | 受限于模型最大上下文窗口(如32K、128K) |
| 实时性 | 检索+生成,检索速度快,生成速度取决于模型 | 直接生成,长文本输入会显著拖慢推理速度 |
| 可扩展性 | 知识库易于扩展和更新,无需重新训练模型 | 上下文窗口有限,超长内容需截断或摘要 |
| 准确性 | 检索相关性决定答案质量,依赖检索效果 | 只要内容在窗口内,模型可直接引用 |
| 幻觉风险 | 检索内容可控,幻觉概率较低 | 长上下文内仍可能出现幻觉 |
| 实现难度 | 需搭建检索系统和知识库,流程较复杂 | 只需支持大窗口模型,流程简单 |
| 成本 | 检索和生成分开,资源消耗可控 | 长上下文推理消耗显著增加 |
1.8.2 适用场景对比 #
RAG适合:
- 企业知识库问答、法律/医疗/金融等专业领域
- 知识库大、内容经常更新的场景
- 需要可追溯、可解释答案的场景
Long Context适合:
- 需要处理长文档、长对话、论文、小说等场景
- 上下文内容有限且全部相关时
- 不方便搭建知识库或检索系统时
2.RAG工作流 #
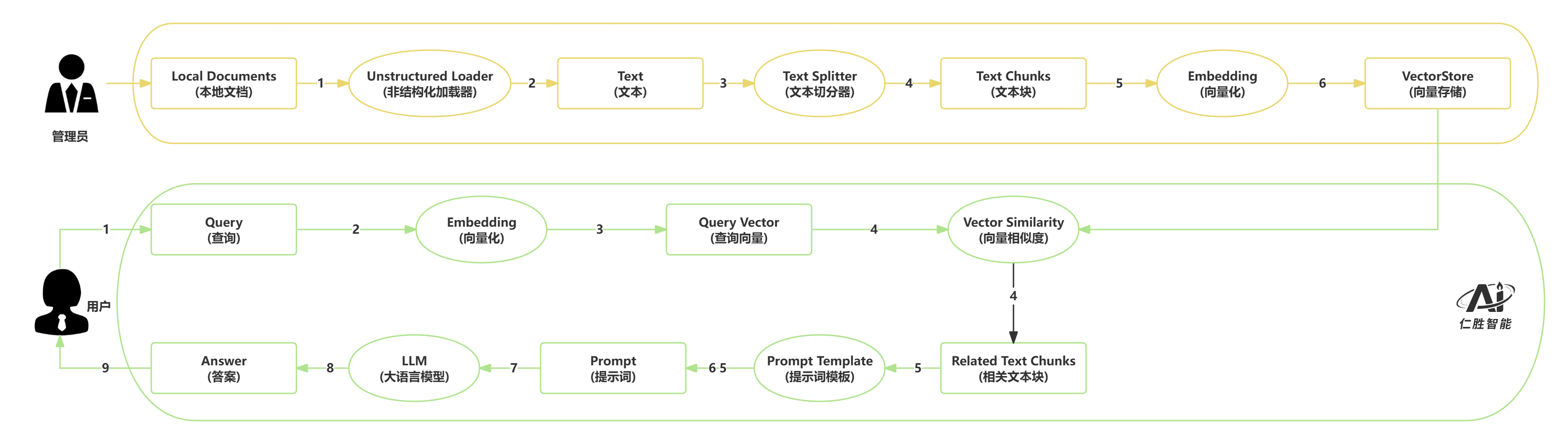
- 管理员负责知识的整理、切分、向量化和入库,保证知识库的丰富和可检索性。
- 用户只需输入问题,系统会自动完成向量化、检索、生成答案等一系列操作,最终返回高质量的答案。
2.1 管理员部分:知识入库流程 #
这部分主要是将本地文档转化为可检索的向量,供后续问答使用。
Local Documents(本地文档)
管理员准备好需要导入的知识文档,格式可以多样(如PDF、Word、txt等)。Unstructured Loader(非结构化加载器)
使用加载器将各种格式的文档解析为纯文本,便于后续处理。Text(文本)
得到的纯文本内容。Text Splitter(文本切分器)
将长文本按照一定规则(如段落、句子、字数等)切分成较小的文本块。Text Chunks(文本块)
切分后得到的多个小文本片段。Embedding(向量化)
利用嵌入模型(如BERT、SentenceTransformer等)将每个文本块转化为高维向量。VectorStore(向量存储)
所有文本块的向量被存入向量数据库(如Milvus等),用于后续的高效检索。
2.2 用户部分:问答检索流程 #
这部分是用户实际提问并获得答案的过程。
Query(查询)
用户输入一个问题或查询。Embedding(向量化)
将用户的查询同样转化为向量表示。Query Vector(查询向量)
得到用户问题的向量。Vector Similarity(向量相似度)
计算查询向量与知识库中所有文本块向量的相似度,找出最相关的若干文本块。Related Text Chunks(相关文本块)
检索到与用户问题最相关的文本片段。Prompt Template(提示词模板)
将用户问题和相关文本块填充到预设的提示词模板中,构建最终的Prompt。Prompt(提示词)
生成用于大语言模型的完整输入。LLM(大语言模型)
将Prompt输入到大语言模型,生成最终的答案。Answer(答案)
返回给用户的最终回答。
3.文档解析 #
3.1 数据格式的多样性 #
在实际开展文档处理工作前,我们首先要对企业内部的数据类型和特点有一个全面的了解。只有充分认识到数据的多样性和复杂性,才能为后续的数据解析和知识库建设打下坚实基础。
企业在日常运营中会积累大量数据,这些数据因行业、业务流程和管理方式的不同而呈现出极大的多样性。部分数据甚至是企业独有的,外部很难见到。因此,数据处理往往需要根据实际情况定制脚本和工具,灵活应对各种数据格式和内容。
企业数据的复杂性主要体现在两个方面:数据格式的多样性和数据内容的复杂性。
3.2 数据内容的复杂性 #
企业数据大致可以分为两大类:结构化数据和非结构化/半结构化数据。
结构化数据
这类数据通常存储在关系型数据库(如 MySQL、Oracle)中,数据以表格形式组织,每个字段都有明确的定义和含义。除了传统的关系型数据库,还有文档型数据库(如 MongoDB)、全文检索数据库(如 Elasticsearch)、列式数据库(如 ClickHouse)、图数据库(如 Neo4j)以及分布式 NoSQL 数据库(如 Cassandra)等。结构化数据的优点是格式统一、易于查询和分析,通常通过 SQL 或类似的查询语言进行操作。非结构化与半结构化数据
这部分数据类型丰富,包括但不限于 PDF、Word、PPT、Excel 等常见办公文档,纯文本文件(如日志、txt),网页数据(HTML)、数据交换格式(JSON、XML)、Markdown 文档,以及图片、音频、视频等多媒体文件。非结构化数据没有固定的字段和格式,内容表现形式灵活多变,解析和处理难度较大。半结构化数据则介于两者之间,既有一定的结构性,又保留了内容的灵活性。
除了格式多样,企业数据在内容层面也极具挑战性,尤其是非结构化文档。以 PDF 文件为例,单个文档中可能同时包含标题、段落、表格、图片、公式等多种元素。不同文档的排版和布局也各不相同,有的采用单栏,有的为双栏,内容组织方式千变万化。文本、标题、列表、表格、图片等元素可能交错出现,给自动化解析带来很大难度。
正因为企业数据在格式和内容上的复杂性,构建高质量的知识库时,往往需要针对不同类型的数据进行专门的预处理和解析策略。只有这样,才能确保后续知识抽取和检索的准确性和有效性。
总之,企业数据的多样性和复杂性是知识管理和智能文档处理中的一大挑战。理解这些特点,有助于我们选择合适的技术方案和工具,提升数据处理的效率和质量。
3.3 GIGO #
在数据处理和智能系统开发领域,有一个非常重要的理念——“劣质输入,必然导致劣质输出”(Garbage In, Garbage Out,简称GIGO)。这个原则广泛应用于计算机科学和信息系统建设中,强调了数据质量对最终结果的决定性作用。无论你的算法多么先进、流程多么完善,如果最初输入的数据存在问题,最终的输出也难以令人满意。
在构建RAG(检索增强生成)知识库的过程中,数据质量同样是成败的关键。整个流程大致包括:业务数据的选取、数据解析、内容分块、向量化处理,以及将向量存入数据库。每一个环节都可能成为“垃圾数据”产生的源头。
数据源选择
首先,数据源的甄别至关重要。只有与业务需求高度相关的数据,才能为系统提供有价值的支撑。如果引入了无关或低质量的信息,不仅会影响检索效果,还可能导致系统输出错误或无意义的答案。此外,数据本身的准确性和一致性也必须得到保证。如果原始数据中存在矛盾、错误或遗漏,后续所有处理都无法弥补这些缺陷。最后,数据的覆盖面也要足够广泛,避免因信息不全而影响系统的整体表现。
数据解析环节
企业数据格式多样,内容复杂,解析过程中极易出现问题。例如,文本内容可能被错误识别,表格结构解析混乱,或者某些关键信息被遗漏。这些解析失误都会直接影响后续的知识抽取和检索效果。因此,数据解析工具和脚本的选择与调优同样重要。
内容分块策略
文档分块是将大文本拆分为更小的片段,以便后续向量化和检索。但如果分块策略不合理,比如将本应连贯的语义拆散,或者把无关内容混在一起,都会导致上下文丢失或检索噪声增加。这不仅影响检索的相关性,还可能让生成模型输出不准确的答案。
全流程质量把控
综上所述,RAG系统的每一步都可能成为“垃圾数据”的入口。只有在数据源筛选、解析、分块等各个环节都严格把控质量,才能确保最终系统的有效性和可靠性。数据质量的保障,是构建高效智能知识系统的基石。始终牢记:只有高质量的输入,才能带来高价值的输出。
3.4 文档解析 #
pip install PyMuPDF python-docx openpyxl python-pptx beautifulsoup4 lxml3.4.1 读取 PDF 文件 #
# 安装依赖:pip install PyMuPDF
import fitz # PyMuPDF
# 定义一个函数用于提取PDF文件中的所有文本内容
def extract_pdf_text(pdf_path):
"""
提取PDF文件中的所有文本内容
参数:
pdf_path (str): PDF文件路径
返回:
str: 合并后的所有页文本
"""
# 打开PDF文件
pdf = fitz.open(pdf_path)
# 创建一个空列表用于存放每一页的文本内容
text_list = []
# 遍历PDF中的每一页
for page in pdf:
# 提取当前页的文本内容,并添加到列表中
text_list.append(page.get_text("text")) # type: ignore
# 将所有页的文本内容合并为一个字符串
all_text = "\n".join(text_list)
# 返回合并后的文本
return all_text
# 主程序入口,进行测试调用
if __name__ == "__main__":
# 指定要读取的PDF文件名
pdf_file = "example.pdf"
# 调用函数提取PDF文本
result_text = extract_pdf_text(pdf_file)
# 打印提取到的文本内容
print(result_text)
3.4.2 读取 Word 文件 #
# 导入python-docx库中的Document类
from docx import Document
# 定义函数:从Word文档中提取所有段落文本
def extract_text_from_word(file_path):
"""
从Word文档中提取所有段落的文本,并以字符串返回。
:param file_path: Word文档的路径
:return: 文本内容字符串
"""
# 加载Word文档
doc = Document(file_path)
# 遍历所有段落,将段落文本拼接为一个字符串(以换行符分隔)
text = "\n".join([para.text for para in doc.paragraphs])
# 返回拼接后的文本
return text
# 主程序入口,进行测试调用
if __name__ == "__main__":
# 指定要读取的Word文件名
file_path = "example.docx"
# 调用函数提取Word文本
result = extract_text_from_word(file_path)
# 打印提取到的文本内容
print(result)
3.4.3 读取 Excel 文件 #
# 安装依赖:pip install openpyxl
import openpyxl
# 定义函数:从Excel文件中提取所有单元格内容为文本
def extract_text_from_excel(file_path):
"""
从Excel文件中提取所有单元格内容为文本,并以字符串返回。
:param file_path: Excel文件路径
:return: 文本内容字符串
"""
# 加载Excel工作簿
wb = openpyxl.load_workbook(file_path)
# 获取活动工作表
ws = wb.active
# 初始化用于存储每一行文本的列表
rows = []
# 遍历工作表中的每一行,values_only=True表示只获取单元格的值
for row in ws.iter_rows(values_only=True):
# 将每一行的所有单元格内容转换为字符串,并用制表符分隔,空单元格用空字符串代替
rows.append("\t".join([str(cell) if cell is not None else "" for cell in row]))
# 将所有行用换行符拼接为一个大字符串
all_text = "\n".join(rows)
# 返回拼接后的文本
return all_text
# 主程序入口,进行测试调用
if __name__ == "__main__":
# 指定要读取的Excel文件名
file_path = "example.xlsx"
# 调用函数提取Excel文本
result = extract_text_from_excel(file_path)
# 打印提取到的文本内容
print(result)
3.4.4 读取 PPT 文件 #
# 导入Presentation类,用于读取PPT文件
from pptx import Presentation
# 定义函数:提取PPT文件中的所有文本内容
def extract_ppt_text(file_path):
"""
提取PPT文件中的所有文本内容,并以字符串返回。
:param file_path: PPT文件路径
:return: 所有文本内容(以换行符分隔)
"""
# 加载PPT文件
ppt = Presentation(file_path)
# 初始化用于存储所有文本的列表
text_list = []
# 遍历PPT中的每一页幻灯片
for slide in ppt.slides:
# 遍历幻灯片中的每一个形状
for shape in slide.shapes:
# 判断该形状是否有text属性(即是否包含文本)
if hasattr(shape, "text"):
# 如果有,则将文本内容添加到列表中
text_list.append(shape.text)
# 将所有文本用换行符拼接成一个字符串
all_text = "\n".join(text_list)
# 返回拼接后的所有文本
return all_text
# 主程序入口,进行测试调用
if __name__ == "__main__":
# 指定要读取的PPT文件名
ppt_file = "example.pptx"
# 调用函数提取PPT文本内容
result = extract_ppt_text(ppt_file)
# 打印提取到的文本内容
print(result)3.4.5 读取 HTML 文件 #
# 安装依赖:pip install beautifulsoup4
from bs4 import BeautifulSoup # 导入BeautifulSoup库用于解析HTML
# 定义函数:从HTML文件中提取所有文本内容
def extract_text_from_html(file_path):
"""
从指定HTML文件中提取所有文本内容
参数:
file_path (str): HTML文件路径
返回:
str: 提取的文本内容
"""
# 以utf-8编码方式打开HTML文件
with open(file_path, "r", encoding="utf-8") as f:
# 读取整个HTML文件内容为字符串
html = f.read()
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(html, "html.parser")
# 提取所有文本内容,使用换行符分隔
text = soup.get_text(separator="\n")
# 返回提取到的文本内容
return text
# 主程序入口,进行测试调用
if __name__ == "__main__":
# 指定要读取的HTML文件名
file_path = "example.html"
# 调用函数提取HTML文本内容
result = extract_text_from_html(file_path)
# 打印提取到的文本内容
print(result)
3.4.6 读取 JSON 文件 #
# 导入内置的json库
import json
# 定义函数:读取并格式化打印JSON文件内容
def read_and_print_json(filename):
"""
读取指定JSON文件并以格式化字符串打印内容
:param filename: JSON文件名
"""
# 以utf-8编码方式打开指定的JSON文件
with open(filename, "r", encoding="utf-8") as f:
# 使用json.load读取文件内容为Python对象
data = json.load(f)
# 使用json.dumps将Python对象格式化为带缩进的字符串,确保中文正常显示
text = json.dumps(data, ensure_ascii=False, indent=2)
# 打印格式化后的JSON字符串
print(text)
# 主程序入口,进行测试调用
if __name__ == "__main__":
# 调用函数,读取并打印example.json文件内容
read_and_print_json("example.json")
3.4.7 读取 XML 文件 #
# 导入lxml库中的etree模块,用于解析XML
from lxml import etree
# 定义函数:从XML文件中提取所有文本内容
def extract_xml_text(file_path):
"""
读取XML文件并提取所有文本内容
参数:
file_path (str): XML文件路径
返回:
str: 提取的所有文本内容
"""
# 以utf-8编码方式打开XML文件
with open(file_path, "r", encoding="utf-8") as f:
# 读取XML文件的全部内容为字符串
xml = f.read()
# 将字符串形式的XML内容解析为XML树结构
root = etree.fromstring(xml.encode("utf-8"))
# 遍历XML树,提取所有文本内容,并用空格连接
text = " ".join(root.itertext())
# 返回提取到的文本内容
return text
# 主程序入口,进行测试调用
if __name__ == "__main__":
# 指定要读取的XML文件名
xml_file = "example.xml"
# 调用函数提取XML文本内容
result = extract_xml_text(xml_file)
# 打印提取到的文本内容
print(result)
3.4.8 读取 CSV 文件 #
# 导入内置的csv库
import csv
# 定义函数:读取CSV文件内容,并将每行用逗号连接,所有行用换行符拼接成一个字符串返回
def read_csv_to_text(filename):
"""
读取CSV文件内容,并将每行用逗号连接,所有行用换行符拼接成一个字符串返回。
"""
# 以utf-8编码方式打开CSV文件
with open(filename, "r", encoding="utf-8") as f:
# 创建csv.reader对象,按行读取CSV内容
reader = csv.reader(f)
# 对每一行,用逗号连接各列,生成字符串列表
rows = [", ".join(row) for row in reader]
# 用换行符拼接所有行,得到完整文本
all_text = "\n".join(rows)
# 返回拼接后的文本
return all_text
# 测试调用
if __name__ == "__main__":
# 调用函数读取example.csv文件内容
result = read_csv_to_text("example.csv")
# 打印读取到的内容
print(result)
3.4.9 读取纯文本文件 #
# 定义一个函数,用于读取指定文本文件的内容并返回
def read_text_file(filename):
"""
读取指定文本文件内容并返回
:param filename: 文件名
:return: 文件内容字符串
"""
# 以只读模式并指定utf-8编码打开文件
with open(filename, "r", encoding="utf-8") as f:
# 读取文件全部内容
text = f.read()
# 返回读取到的文本内容
return text
# 测试代码块,只有当本文件作为主程序运行时才会执行
if __name__ == "__main__":
# 调用函数读取example.txt文件内容
result = read_text_file("example.txt")
# 打印读取到的内容
print(result)
3.4.10 读取 Markdown #
# 定义一个函数,用于读取Markdown文件内容
def read_markdown_file(file_path):
# 以只读模式并指定utf-8编码打开Markdown文件
with open(file_path, "r", encoding="utf-8") as f:
# 读取并返回文件的全部内容
return f.read()
# 测试代码块,只有当本文件作为主程序运行时才会执行
if __name__ == "__main__":
# 调用函数读取example.md文件内容
content = read_markdown_file("example.md")
# 打印读取到的内容
print(content)
4 文档分割 #
文本分块(Text Chunking)是一种将长文档分解为更小、更易处理的文本片段的技术。这个过程类似于将一本厚重的书籍拆分成多个章节,每个章节都包含相对独立且完整的信息单元。
4.1 文本分块的核心价值 #
在构建检索增强生成(RAG)系统时,文本分块技术具有以下重要意义:
语义纯度保证:长文档往往包含多个不同的主题和语义信息,直接处理会导致语义混淆,影响检索精度。
检索精度提升:通过分块,系统能够更精确地匹配用户查询,避免返回无关信息,从而提高回答质量。
模型限制适配:现代语言模型都有输入长度限制,分块技术确保每个文本片段都能在模型的处理范围内。
4.2. 文本分块的基本原则 #
4.2.1 语义完整性原则 #
每个文本块应该包含一个完整且独立的语义单元。这就像拼图游戏中的每一块,都应该能够独立表达一个完整的概念。
4.2.2 大小平衡原则 #
- 过小的块:会破坏语义的完整性,导致上下文信息缺失
- 过大的块:可能包含多个不相关的主题,降低检索精度
4.3 递归分割策略 #
递归分割是一种基于规则的分块方法,其核心思想是使用预定义的分隔符对文档进行逐级分解。
4.3.1 工作原理 #
文档 → 段落 → 句子 → 单词 → 字符系统首先使用最粗粒度的分隔符(如段落分隔符),如果生成的块仍然过大,则使用更细粒度的分隔符继续分割,直到所有块都符合预设大小。
4.3.2 关键参数设置 #
- 块大小(Chunk Size):通常设置为200-1000个字符,具体取决于embedding模型的输入限制
- 重叠长度(Overlap):在相邻块之间保留一定长度的重复文本,确保语义连贯性
- 分隔符优先级:从粗到细的分割策略
4.3.3 代码实现 #
递归分割过程:
- 首先尝试用第一个分隔符(如
\n\n)分割文本 - 检查每个分割后的部分是否仍大于
chunk_size - 如果仍太大,则用下一个优先级的分隔符(如
\n)继续分割 - 重复此过程直到所有部分都小于等于
chunk_size或用完所有分隔符
- 首先尝试用第一个分隔符(如
重叠处理:
- 在分割时会保留
chunk_overlap指定的重叠量 - 重叠部分通常是前一个块的结尾和后一个块的开头
- 在分割时会保留
# 递归字符分割器的导入(可选,实际未用到)
# from langchain.text_splitter import RecursiveCharacterTextSplitter
# 定义递归字符分割器类
class RecursiveCharacterTextSplitter:
# 构造函数,初始化分块大小、重叠长度和分隔符
def __init__(self, chunk_size=128, chunk_overlap=30, separators=None):
# 设置分块的最大长度
self.chunk_size = chunk_size
# 设置分块之间的重叠长度
self.chunk_overlap = chunk_overlap
# 如果没有传入分隔符,则使用默认分隔符列表
if separators is None:
self.separators = ["\n\n", "\n", " ", ""]
else:
# 否则使用用户自定义的分隔符
self.separators = separators
# 文本分割的主函数
def split_text(self, text):
# 定义递归分割的内部函数
def recursive_split(txt, seps):
# 如果分隔符列表为空,直接按块大小切分
if not seps:
# 返回按chunk_size切分的文本块列表
return [
txt[i : i + self.chunk_size]
for i in range(0, len(txt), self.chunk_size)
]
# 取当前分隔符
sep = seps[0]
# 按当前分隔符分割文本
parts = txt.split(sep)
# 初始化结果列表
result = []
# 遍历每一段
for part in parts:
# 如果不是最后一段,则补回分隔符
if part != parts[-1]:
part = part + sep
# 如果当前段落长度大于块大小,递归用下一个分隔符继续分割
if len(part) > self.chunk_size:
result.extend(recursive_split(part, seps[1:]))
else:
# 否则直接加入结果
result.append(part)
# 返回分割结果
return result
# 递归分割文本,并去除空白分块
splits = [s for s in recursive_split(text, self.separators) if s.strip()]
# 初始化分块列表
chunks = []
# 初始化索引
i = 0
# 遍历所有分割结果
while i < len(splits):
# 当前分块
chunk = splits[i]
# 下一个分块的索引
j = i + 1
# 尽量合并多个分块到一个chunk,直到超出块大小
while j < len(splits) and len(chunk) + len(splits[j]) <= self.chunk_size:
# 合并分块
chunk += splits[j]
j += 1
# 添加合并后的分块到结果列表
chunks.append(chunk)
# 如果需要重叠,并且还有剩余分块
if self.chunk_overlap > 0 and j < len(splits):
# 获取重叠部分
overlap = chunk[-self.chunk_overlap :]
# 将重叠部分加到下一个分块前面
if j < len(splits):
splits[j] = overlap + splits[j]
# 移动到下一个分块
i = j
# 返回所有分块
return chunks
# 创建分块器对象,指定分块大小、重叠长度和分隔符
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=50, # 每个分块最大50字符
chunk_overlap=10, # 相邻分块重叠10字符
separators=[
"\n\n", # 段落分隔
"\n", # 换行
".", # 英文句号
"。", # 中文句号
",", # 英文逗号
",", # 中文逗号
],
)
# 定义示例文本
text = """
这是第一句话。
这是第二句话,包含中文逗号,
This is the first English sentence.
This is the second English sentence.
这是第三句话.
这是第四句话,包含英文逗号,
这是第五句话,段落分隔。
这是第六句话,包含两个换行。
"""
# 调用分块器进行文本分块
chunks = r_splitter.split_text(text)
# 遍历输出每个分块的内容
for i, chunk in enumerate(chunks):
# 输出每个分块的编号和内容
print(f"Chunk {i+1}: {chunk}")
4.3 语义感知分块策略 #
基于规则的分块方法虽然简单有效,但有时无法准确识别语义边界。语义感知分块技术通过分析文本的语义特征来进行更智能的分割。
基于Embedding的语义分块利用预训练的embedding模型来计算文本片段之间的语义相似度。
核心思想
- 语义分块:不是简单的按长度或句子数分割,而是基于语义相似度进行智能分割。
- 滑动窗口:先用固定大小的窗口创建初始块,再根据语义相似度调整。
- 相似度阈值:通过阈值控制分割的粒度,阈值越高分割越细,阈值越低分割越粗。

# 导入句子嵌入模型
from sentence_transformers import SentenceTransformer
# 导入numpy用于数值计算
import numpy as np
# 导入正则表达式模块
import re
# 加载预训练的句子嵌入模型
print("正在加载句子嵌入模型...")
model = SentenceTransformer("all-MiniLM-L6-v2")
print("模型加载完成。")
# 定义基于语义的分块器类
class SemanticChunker:
# 初始化方法,设置窗口大小和相似度阈值
def __init__(self, window_size=2, threshold=0.85):
# 设置每个窗口包含的句子数
self.window_size = window_size
# 设置相邻窗口的相似度阈值
self.threshold = threshold
# 日志:输出初始化参数
print(
f"SemanticChunker初始化,窗口大小: {window_size},相似度阈值: {threshold}"
)
# 创建分块文档的方法
def create_documents(self, text):
# 使用正则表达式按中英文标点和换行分割句子
# 当正则表达式中使用捕获分组时,分隔符会包含在结果中
print("正在分割原始文本为句子...")
sentences = re.split(r"(。|!|?|\!|\?|\.|\n)", text)
# 初始化句子列表
sents = []
# 遍历分割后的句子和标点,合并为完整句子
for i in range(0, len(sentences) - 1, 2):
# 拼接句子内容和分隔符
s = sentences[i].strip() + sentences[i + 1].strip()
# 如果拼接后不为空,则加入句子列表
if s.strip():
sents.append(s)
# 日志:输出分割后的句子数量
print(f"分割得到 {len(sents)} 个句子。")
# 初始化分块列表
docs = []
# 设置起始索引
start = 0
# 使用滑动窗口将句子分组
print("正在使用滑动窗口进行初步分块...")
while start < len(sents):
# 计算窗口结束位置
end = min(start + self.window_size, len(sents))
# 获取当前窗口的句子
window = sents[start:end]
# 合并窗口内句子为一个块
docs.append("".join(window))
# 移动到下一个窗口
start = end
# 日志:输出初步分块数量
print(f"初步分块完成,共 {len(docs)} 个块。")
# 计算每个窗口的嵌入向量
print("正在计算每个块的嵌入向量...")
embeddings = model.encode(docs)
# 初始化分割点列表,起始点为0
split_points = [0]
# 遍历相邻窗口,计算相似度
print("正在计算相邻块之间的相似度...")
for i in range(1, len(docs)):
# 计算余弦相似度
sim = np.dot(embeddings[i - 1], embeddings[i]) / (
np.linalg.norm(embeddings[i - 1]) * np.linalg.norm(embeddings[i])
)
# 日志:输出每对块的相似度
print(f"块 {i} 与块 {i-1} 的相似度为: {sim:.4f}")
# 如果相似度低于阈值,则作为新的分割点
if sim < self.threshold:
print(f"相似度低于阈值({self.threshold}),在位置 {i} 添加分割点。")
split_points.append(i)
# 初始化最终分块结果列表
result = []
# 遍历所有分割点,生成最终文本块
print("正在根据分割点生成最终分块结果...")
for i in range(len(split_points)):
# 当前块的起始索引
start = split_points[i]
# 当前块的结束索引
end = split_points[i + 1] if i + 1 < len(split_points) else len(docs)
# 合并该范围内的窗口为一个块
chunk = "".join(docs[start:end])
# 如果块内容不为空,则加入结果列表
if chunk.strip():
print(f"生成第 {len(result)+1} 个块,内容长度: {len(chunk)}")
result.append(chunk)
# 返回所有分块
print(f"最终分块完成,共 {len(result)} 个块。")
return result
# 创建语义分块器对象,设置窗口大小和相似度阈值
print("正在创建语义分块器对象...")
semantic_splitter = SemanticChunker(window_size=2, threshold=0.85)
# 准备需要分割的长文本
print("准备待分割的长文本...")
long_text = """
今天天气晴朗,适合去公园散步。
量子力学中的叠加态是描述粒子同时处于多个状态的数学工具。
Windows命令行中,复制文件可以使用:copy source.txt destination.txt
大熊猫主要以竹子为食,是中国的国宝。
欧拉公式被誉为“最美的数学公式”。
"""
# 执行文本分割,得到分块结果
print("开始执行文本分割...")
documents = semantic_splitter.create_documents(long_text)
# 打印分割结果,显示每个块的内容
print(f"总共分割为 {len(documents)} 个块:\n")
for i, doc in enumerate(documents, 1):
# 打印当前块的编号
print(f"=== 第 {i} 个块 ===")
# 打印当前块的内容
print(doc)
1. 句子分割阶段
sentences = re.split(r"(。|!|?|\!|\?|\.|\n)", text)- 作用:使用正则表达式按中英文标点符号和换行符分割文本。
- 正则表达式说明:
(。|!|?|\!|\?|\.|\n):匹配中文句号、感叹号、问号,英文感叹号、问号、句号,以及换行符。- 由于使用了捕获分组
(),分隔符会保留在结果中。
- 结果:得到一个包含句子内容和分隔符的列表。
2. 句子重构阶段
sents = []
for i in range(0, len(sentences) - 1, 2):
s = sentences[i].strip() + sentences[i + 1].strip()
if s.strip():
sents.append(s)- 作用:将分割后的句子内容和分隔符合并为完整的句子。
- 逻辑说明:
- 由于正则分割的结果是
[句子1, 分隔符1, 句子2, 分隔符2, ...],所以每两个元素为一组。 sentences[i]是句子内容,sentences[i + 1]是对应的分隔符。- 合并后得到完整的句子,并过滤掉空字符串。
- 由于正则分割的结果是
3. 初始分块阶段(滑动窗口)
docs = []
start = 0
while start < len(sents):
end = min(start + self.window_size, len(sents))
window = sents[start:end]
docs.append("".join(window))
start = end- 作用:使用滑动窗口将句子分组,创建初始的文本块。
- 参数说明:
window_size=2:每个窗口包含2个句子。
- 执行过程:
- 从第0个句子开始,每次取2个句子组成一个窗口。
- 将窗口内的句子合并为一个文本块。
- 移动到下一个窗口,直到处理完所有句子。
4. 嵌入向量计算阶段
embeddings = model.encode(docs)- 作用:使用预训练的句子嵌入模型将每个文本块转换为向量表示。
- 模型说明:
all-MiniLM-L6-v2是一个轻量级的句子嵌入模型,能够将文本转换为384维的向量。
5. 相似度计算和分割点确定阶段
split_points = [0]
for i in range(1, len(docs)):
sim = np.dot(embeddings[i - 1], embeddings[i]) / (
np.linalg.norm(embeddings[i - 1]) * np.linalg.norm(embeddings[i])
)
if sim < self.threshold:
split_points.append(i)- 作用:计算相邻文本块的余弦相似度,根据相似度阈值确定分割点。
- 计算过程:
- 使用余弦相似度公式
- 如果相似度低于阈值(0.85),则认为这两个块语义差异较大,需要分割。
- 结果:得到一个分割点列表,表示哪些位置需要分割。
6. 最终分块生成阶段
result = []
for i in range(len(split_points)):
start = split_points[i]
end = split_points[i + 1] if i + 1 < len(split_points) else len(docs)
chunk = "".join(docs[start:end])
if chunk.strip():
result.append(chunk)- 作用:根据分割点生成最终的文本块。
- 逻辑说明:
- 遍历所有分割点,每个分割点之间的范围作为一个文本块。
- 将范围内的初始文本块合并为一个最终块。
- 过滤掉空字符串,返回最终的分块结果。
5. 向量化 #
5.1 doubao #
embedding\doubao.py
# 导入os模块,用于读取环境变量
import os
# 导入requests库,用于发送HTTP请求
import requests
# 设置文本向量API的URL
VOLC_EMBEDDINGS_API_URL = "https://ark.cn-beijing.volces.com/api/v3/embeddings"
# 设置API密钥
VOLC_API_KEY = "d52e49a1-36ea-44bb-bc6e-65ce789a72f6"
# 定义获取文档向量的函数,参数为文档内容
def get_doubao_embedding(doc_content):
# 构造请求头,包含内容类型和认证信息
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {VOLC_API_KEY}",
}
# 构造请求体,指定模型和输入内容
payload = {"model": "doubao-embedding-text-240715", "input": doc_content}
# 发送POST请求到向量API,获取响应
response = requests.post(VOLC_EMBEDDINGS_API_URL, json=payload, headers=headers)
# 判断响应状态码是否为200,表示请求成功
if response.status_code == 200:
# 解析响应的JSON数据
data = response.json()
# 提取嵌入向量
embedding = data["data"][0]["embedding"]
# 返回嵌入向量
return embedding
else:
# 如果请求失败,抛出异常并输出错误信息
raise Exception(f"Embedding API error: {response.text}")
# 主程序入口
if __name__ == "__main__":
# 定义待处理的文档内容
doc_content = "这是一个示例文档"
# 调用函数获取嵌入向量
embedding = get_doubao_embedding(doc_content)
# 打印嵌入向量
print(embedding)
5.2 本地向量化 #
embedding\sentence.py
# 从sentence_transformers库中导入SentenceTransformer类
from sentence_transformers import SentenceTransformer
# 加载预训练的句子嵌入模型"all-MiniLM-L6-v2"
model = SentenceTransformer("all-MiniLM-L6-v2")
# 定义一个函数,用于获取输入文档内容的向量表示
def get_sentence_embedding(doc_content):
# 使用模型对文档内容进行编码,得到嵌入向量
embedding = model.encode(doc_content)
# 返回嵌入向量
return embedding
# 判断当前脚本是否为主程序入口
if __name__ == "__main__":
# 定义一个示例文档内容
doc_content = "这是一个示例文档"
# 获取示例文档的嵌入向量
embedding = get_sentence_embedding(doc_content)
# 打印嵌入向量
print(embedding)
6. 向量存储 #
vectorstore\db.py
# 导入 chromadb 库
import chromadb
# 导入 sentence_transformers 库中的 SentenceTransformer 类
from sentence_transformers import SentenceTransformer
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
# 首次调用时会触发下载和安装过程保存到缓存目录(默认 ~/.cache/sentence_transformers)
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的 Chroma 客户端,数据将保存在本地的 ./chroma_db 目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 定义将文本保存到 ChromaDB 的函数
def save_text_to_db(text, collection_name="rag_collection"):
"""
将文本保存到ChromaDB指定集合中,使用sentence_transformers生成embedding。
:param text: 要保存的文本
:param collection_name: 集合名称,默认rag_collection
"""
# 获取指定名称的集合,如果不存在则创建
collection = client.get_or_create_collection(collection_name)
# 使用文本内容的哈希值作为唯一id
text_id = str(abs(hash(text)))
# 生成文本的向量表示(embedding),并转换为列表格式
embedding = model.encode([text])[0].tolist()
# 向集合中添加文本、元数据、id和embedding
collection.add(
documents=[text],
metadatas=[{"source": "user_input"}],
ids=[text_id],
embeddings=[embedding],
)
# 打印保存成功的信息及文本id
print(f"文本已保存到ChromaDB,id={text_id}")
# 返回文本id
return text_id
# 主程序入口示例
if __name__ == "__main__":
# 调用函数,将测试文本保存到数据库
tid = save_text_to_db("这是一个测试文本")
第一阶段:系统初始化 程序启动后首先导入必要的库,包括向量数据库客户端和句子嵌入模型。系统会加载预训练的句子嵌入模型,这个模型负责将文本转换为向量表示。同时创建持久化的数据库客户端,连接到本地的向量数据库存储目录。
第二阶段:数据库连接准备 系统连接到指定的向量数据库,获取或创建用于存储文档的集合。如果集合不存在,系统会自动创建一个新的集合。这个集合将用于存储所有的文本数据及其对应的向量表示。
第三阶段:文本标识生成 为要保存的文本生成唯一的标识符。系统使用文本内容的哈希值作为唯一ID,确保相同内容的文本具有相同的标识符,不同内容的文本具有不同的标识符。这种标识方式既保证了唯一性又便于后续的查找和管理。
第四阶段:向量化处理 使用预训练的句子嵌入模型将文本内容转换为向量表示。模型会将文本编码为高维向量,然后转换为列表格式以便存储。这个过程是文本检索和相似度计算的基础,向量化的质量直接影响后续检索的效果。
第五阶段:数据存储操作 将文本内容、元数据、唯一标识符和向量表示一起存储到向量数据库中。系统会为每个文本条目添加源信息等元数据,便于后续的数据管理和追踪。所有信息都会被组织成结构化的数据格式存储在数据库中。
第六阶段:完成确认 存储操作完成后,系统会输出成功信息,包括保存的文本ID和操作状态。同时返回文本的标识符,供调用方进行后续处理或引用。
7. 入库 #
input.py
# 导入os模块用于文件路径处理
import os
# 从vectorstore.db模块导入保存文本到数据库的函数
from vectorstore.db import save_text_to_db
# 导入各类文件解析函数
from parser.pdf import extract_pdf_text
from parser.word import extract_text_from_word
from parser.excel import extract_text_from_excel
from parser.ppt import extract_ppt_text
from parser.htm import extract_text_from_html
from parser.xmls import extract_xml_text
from parser.csvs import read_csv_to_text
# 导入文本分块器
from splitter.text_splitter import RecursiveCharacterTextSplitter
# 导入logging模块用于日志记录
import logging
# 配置日志格式和级别
logging.basicConfig(
level=logging.INFO, format="%(asctime)s [%(levelname)s] %(message)s"
)
# 自动根据文件类型提取文本内容的函数
def extract_text_auto(file_path):
# 获取文件扩展名并转为小写
ext = os.path.splitext(file_path)[-1].lower()
# 根据不同文件类型调用相应的解析函数
if ext == ".pdf":
logging.info(f"检测到PDF文件,开始提取文本: {file_path}")
return extract_pdf_text(file_path)
elif ext in [".docx", ".doc"]:
logging.info(f"检测到Word文件,开始提取文本: {file_path}")
return extract_text_from_word(file_path)
elif ext in [".xlsx", ".xls"]:
logging.info(f"检测到Excel文件,开始提取文本: {file_path}")
return extract_text_from_excel(file_path)
elif ext in [".pptx", ".ppt"]:
logging.info(f"检测到PPT文件,开始提取文本: {file_path}")
return extract_ppt_text(file_path)
elif ext in [".html", ".htm"]:
logging.info(f"检测到HTML文件,开始提取文本: {file_path}")
return extract_text_from_html(file_path)
elif ext == ".xml":
logging.info(f"检测到XML文件,开始提取文本: {file_path}")
return extract_xml_text(file_path)
elif ext == ".csv":
logging.info(f"检测到CSV文件,开始提取文本: {file_path}")
return read_csv_to_text(file_path)
elif ext in [".md", ".txt", ".jsonl"]:
logging.info(f"检测到文本/Markdown/JSONL文件,开始读取: {file_path}")
with open(file_path, "r", encoding="utf-8") as f:
return f.read()
else:
# 不支持的文件类型,抛出异常
logging.error(f"不支持的文件类型: {ext}")
raise ValueError("不支持的文件类型: " + ext)
# 文档入库主流程函数
def doc_to_vectorstore(file_path, collection_name="rag_collection"):
# 1. 非结构化文本加载
logging.info(f"开始提取文件内容: {file_path}")
text = extract_text_auto(file_path)
logging.info(f"文件内容提取完成,长度为{len(text)}个字符")
# 2. 文本分块
logging.info("开始进行文本分块")
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=30)
chunks = splitter.split_text(text)
logging.info(f"文本分块完成,共分为{len(chunks)}块")
# 3. 嵌入并保存到向量数据库
for idx, chunk in enumerate(chunks):
logging.info(f"正在保存第{idx+1}/{len(chunks)}块到向量数据库")
save_text_to_db(chunk, collection_name=collection_name)
# 入库完成提示
print(f"文件 {file_path} 已完成入库,共分块 {len(chunks)} 个。")
logging.info(f"文件 {file_path} 已全部分块并入库完成")
# 示例用法
if __name__ == "__main__":
# 提示用户输入文件路径
file_path = input(
"请输入要入库的文件路径(如:lora_hust_student_handbookt.jsonl):"
)
# 执行文档入库流程
doc_to_vectorstore(file_path)
第一阶段:系统环境准备 程序启动后首先导入必要的模块和库,包括文件路径处理模块、各种文件解析器、文本分块器、数据库操作函数以及日志记录模块。同时配置日志系统,设置日志格式和记录级别,为后续的文件处理操作提供详细的执行记录。
第二阶段:文件类型识别 系统根据用户输入的文件路径,自动识别文件的扩展名并转换为小写格式。通过文件扩展名判断文件类型,支持多种常见格式包括PDF、Word、Excel、PPT、HTML、XML、CSV以及纯文本文件等。
第三阶段:文本内容提取 根据识别出的文件类型,调用相应的解析函数进行文本提取。每种文件类型都有专门的解析器,能够处理不同格式的文档结构。系统会记录提取过程的日志信息,包括检测到的文件类型和提取状态。
第四阶段:文本分块处理 将提取出的完整文本内容进行分块处理。使用递归字符分块器,设置合适的分块大小和重叠长度,确保文本块既保持语义完整性又便于后续的向量化处理。系统会记录分块的数量和进度。
第五阶段:向量化存储 逐个处理每个文本块,将文本内容转换为向量表示并存储到向量数据库中。每个文本块都会被保存到指定的集合中,系统会记录每个块的保存进度,确保所有内容都正确入库。
第六阶段:完成确认 当所有文本块都成功保存到向量数据库后,系统会输出完成提示信息,包括处理的文件路径和总的分块数量。同时记录详细的日志信息,便于后续的调试和监控。
8. 用户查询 #
# 导入sentence_transformers库中的SentenceTransformer类
from sentence_transformers import SentenceTransformer
# 导入chromadb库
import chromadb
# 从本地llm.local模块导入ollama_qa函数
from llm.local import ollama_qa
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的Chroma客户端,数据将保存在本地的./chroma_db目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
# 定义函数:将query转为embedding向量
def get_query_embedding(query):
# 日志:打印正在进行query向量化
print("[日志] 正在将Query转为向量...")
# 使用模型对query进行编码,并转为list格式
return model.encode(query).tolist()
# 定义函数:向量检索,返回最相关的文本块列表
def retrieve_related_chunks(query_embedding, n_results=3):
# 日志:打印正在进行向量检索
print(f"[日志] 正在进行向量检索,返回最相关的{n_results}个文本块...")
# 在集合中进行向量检索,返回最相关的n_results个结果
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
# 获取检索到的文档内容
related_chunks = results.get("documents")
# 如果没有检索到相关内容,则提示并退出程序
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
# 日志:打印检索到的文本块数量
print(f"[日志] 成功检索到{len(related_chunks[0])}个相关文本块。")
# 返回最相关的文本块列表
return related_chunks[0]
# 主程序入口
if __name__ == "__main__":
# 日志:程序启动
print("[日志] 程序启动,准备接受用户输入。")
# 1. 用户输入Query
query = input("请输入您的问题:")
# 日志:打印用户输入的Query
print(f"[日志] 用户输入的问题为:{query}")
# 2. Query向量化
query_embedding = get_query_embedding(query)
# 日志:打印Query向量化完成
print("[日志] Query向量化完成。")
# 3. 向量检索
related_chunks = retrieve_related_chunks(query_embedding, n_results=3)
# 日志:打印向量检索完成
print("[日志] 向量检索完成。")
# 4. 构建Prompt,将检索到的相关内容拼接为上下文
context = "\n".join(related_chunks)
prompt = f"已知信息:\n{context}\n\n请根据上述内容回答用户问题:{query}"
print("prompt:", prompt)
# 日志:打印Prompt构建完成
print("[日志] Prompt构建完成,准备调用大模型生成答案。")
# 5. 调用大模型生成答案
answer = ollama_qa(prompt)
# 日志:打印答案生成完成
print("[日志] 答案生成完成。")
# 6. 输出答案
print("\n【答案】\n", answer)第一阶段:系统初始化 程序启动后首先进行环境准备,加载预训练的句子嵌入模型,用于将文本转换为向量表示。同时连接到向量数据库,获取或创建用于存储文档的集合。这个阶段为后续的检索和生成操作奠定基础。
第二阶段:用户交互 系统等待用户输入问题,用户输入后程序将问题内容存储在变量中,准备进行后续处理。这是整个流程的起点,用户的问题将决定后续检索的方向。
第三阶段:查询向量化 将用户输入的文本问题转换为数学向量。这个过程使用预训练的句子嵌入模型,将自然语言转换为高维向量空间中的点。向量化后的查询可以用于后续的相似度计算和检索操作。
第四阶段:向量检索 在向量数据库中搜索与查询向量最相似的文档片段。系统使用向量相似度算法(如余弦相似度)计算查询向量与数据库中所有文档向量的相似程度,然后返回相似度最高的几个文档片段作为候选结果。
第五阶段:上下文构建 将检索到的相关文档片段合并成一个完整的上下文字符串。然后构建包含检索到的上下文信息和用户原始问题的完整提示词,为大语言模型提供必要的背景信息。
第六阶段:答案生成 调用本地大语言模型,基于构建的上下文和用户问题生成答案。模型会综合考虑检索到的相关信息,生成准确、相关的回答。
第七阶段:结果输出 将大语言模型生成的答案格式化后输出给用户,完成整个问答流程。