1. 企业级RAG的难题 #
首先,企业内部的数据类型极为丰富,既有结构化信息(如数据库、表格),也有大量非结构化内容(如PDF、PPT、Word文档等)。这些数据来源广泛、格式各异,如何高效地解析、整合并标准化处理,成为知识库构建的首要门槛。
其次,数据处理完成后,如何将其转化为可用的知识资产?这涉及到文本切分、内容分块、索引构建等一系列技术细节。每一步都直接影响后续检索的效率与准确性。
第三,用户的提问方式千差万别,有的简明扼要,有的则需要结合上下文理解。如何让系统灵活应对不同类型的问题,并持续提升答案的相关性和准确度,是系统智能化的关键。
第四,RAG系统的核心在于“检索增强”。只有精准、高效地定位到与问题最相关的信息,才能为生成模型提供坚实的知识支撑。因此,优化检索算法、提升召回质量,是不可忽视的技术挑战。
第五,面对检索到的大量相关内容,如何进行有效筛选、排序,并设计出能充分激发大模型能力的提示词(Prompt),同样考验着系统的综合能力。此外,如何选择最适合业务场景的大语言模型,也是影响最终效果的重要因素。
1.1 参考 #
- math.log
- TF-IDE
- BM25
- ollama
- rag_measure
- ragas
- ASGI
- FastAPI
- FastChat
- Jupyter
- PyTorch
- serper
- uvicorn
- markdownify
- NormalizedLevenshtein
- raq-action
- CrossEncoder
- Bi-Encoder
2.RAG技术优化策略 #
在构建智能问答系统时,我们面临一个核心挑战:如何将海量知识库中的相关信息精准地传递给大语言模型,从而生成高质量的答案?
2.2 传统RAG的局限性 #
传统的检索增强生成(RAG)系统存在一个根本性问题:用户提问方式的多样性与检索匹配的精确性之间存在天然矛盾。当用户以不同表达方式、不同角度描述同一问题时,基于相似度匹配的检索机制往往无法准确识别真正相关的上下文信息。这些"噪声"信息一旦被输入到大语言模型中,就会显著降低最终答案的质量和准确性。
2.3 双重优化策略 #
针对上述挑战,业界发展出了两种核心优化思路:
检索前增强(Pre-retrieval Enhancement) 这种方法从问题本身入手,通过智能改写、语义扩充等技术手段,将用户的原始问题转化为更加丰富、更具表达力的查询形式。这样做的好处是能够显著提升与知识库文档的匹配精度,确保检索到的信息与用户真实意图高度相关。
检索后增强(Post-retrieval Enhancement) 这种方法则专注于对已检索到的上下文信息进行深度处理。主要包括:
- 多策略检索融合:结合向量检索、关键词匹配、语义搜索等多种方法
- 相关性重排序:基于与问题的相关程度对检索结果进行智能排序
- 信息去噪与筛选:过滤掉低质量或无关的上下文信息
2.4 系统性优化 #
除了上述两种策略,还有更高层次的优化方法:
模块化RAG架构
通过引入验证判别模块,如Self-RAG等先进技术,对整个RAG流程进行系统性优化。这种方法不仅关注单个环节的性能提升,更注重整个系统的协调性和鲁棒性。
迭代式检索增强 突破传统单次检索的局限,采用多轮迭代的方式逐步优化检索结果。每一轮迭代都会基于前一轮的结果进行深度分析和改进,从而不断提升最终答案的质量。
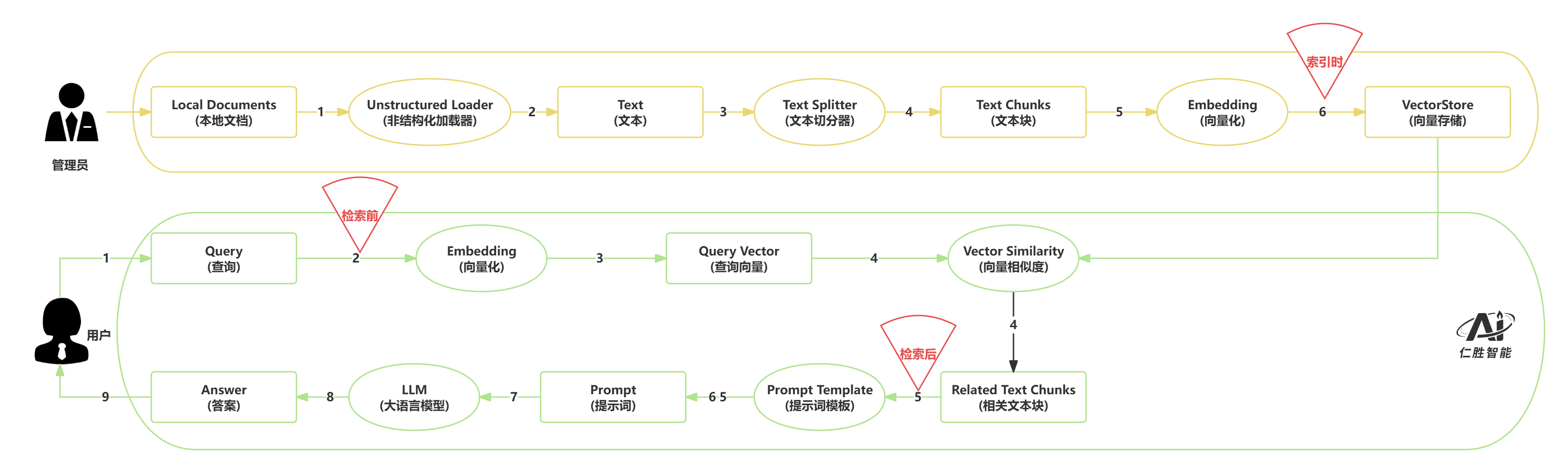
3.信息检索的双重路径 #
先理解信息检索领域的两种核心范式:基于统计的稀疏检索和基于语义的稠密检索。这两种方法代表了从传统文本处理到现代人工智能的演进历程。
3.1 稀疏检索 #
稀疏检索本质上是一种基于关键词匹配的智能筛选机制。其核心思想是通过量化分析文档中词汇的分布特征,来评估查询与文档之间的相关性强度。
3.1.1 TF-IDF算法 #
TF-IDF算法:词频与稀有性的完美平衡
TF-IDF算法由两个相互补充的组件构成:
TF - Term Frequency(词频):衡量词汇在特定文档中的重要性
- 计算公式:TF = (词汇在文档中的出现次数) / (文档总词数)
- 核心思想:高频词汇往往代表文档的核心主题
- 预处理:需要过滤停用词(如"的"、"了"等无意义词汇)
IDF - Inverse Document Frequency(逆文档频率):评估词汇在整个语料库中的区分能力
- 计算公式:IDF = log(语料库总文档数 / 包含该词汇的文档数 + 1)
- 核心思想:越稀有的词汇,其区分能力越强
- 数学特性:加1操作避免除零错误
最终评分:TF-IDF = TF × IDF
这个算法体现了信息检索的一个基本原理:词汇的重要性既取决于其在文档中的出现频率,也取决于其在语料库中的稀有程度。
3.1.2 代码实现 #
# 导入数学库用于对数计算
import math
# 导入Counter用于计数,defaultdict用于默认字典
from collections import Counter, defaultdict
# 计算词频 (Term Frequency)
def calculate_tf(words):
# 统计每个词出现的次数
word_count = Counter(words)
# 统计总词数
total_words = len(words)
# 日志:输出词频统计信息
print(f"[日志] 当前文档总词数: {total_words}")
print(f"[日志] 当前文档词频统计: {word_count}")
# 计算每个词的词频并返回
return {word: count / total_words for word, count in word_count.items()}
# 计算逆文档频率 (Inverse Document Frequency)
def calculate_idf(documents):
# 统计文档总数
total_docs = len(documents)
# 用于统计每个词出现在多少个文档中
word_doc_count = defaultdict(int)
# 遍历每个文档
for idx, doc in enumerate(documents):
# 获取文档中的唯一词集合
unique_words = set(doc)
# 日志:输出当前文档的唯一词
print(f"[日志] 文档{idx+1}唯一词集合: {unique_words}")
# 统计每个词出现的文档数
for word in unique_words:
word_doc_count[word] += 1
# 日志:输出每个词出现的文档数
print(f"[日志] 每个词出现的文档数: {dict(word_doc_count)}")
# 计算每个词的IDF值并返回
return {
word: math.log(total_docs / (count + 1))
for word, count in word_doc_count.items()
}
# 计算TF-IDF值
def calculate_tfidf(documents):
# 计算每个文档的TF值
tf_scores = []
for idx, doc in enumerate(documents):
tf = calculate_tf(doc)
# 日志:输出当前文档的TF值
print(f"[日志] 文档{idx+1}的TF值: {tf}")
tf_scores.append(tf)
# 计算IDF值
idf_scores = calculate_idf(documents)
# 日志:输出所有词的IDF值
print(f"[日志] 所有词的IDF值: {idf_scores}")
# 计算TF-IDF值
tfidf_scores = []
for idx, tf_doc in enumerate(tf_scores):
doc_tfidf = {}
for word, tf in tf_doc.items():
doc_tfidf[word] = tf * idf_scores[word]
# 日志:输出当前文档的TF-IDF值
print(f"[日志] 文档{idx+1}的TF-IDF值: {doc_tfidf}")
tfidf_scores.append(doc_tfidf)
# 返回所有文档的TF-IDF值
return tfidf_scores
# 示例演示
if __name__ == "__main__":
# 示例文档(已分词)
documents = [
["人工智能", "计算机科学", "分支", "创建", "系统"],
["机器学习", "人工智能", "子领域", "计算机", "学习"],
["深度学习", "机器学习", "分支", "神经网络", "学习"],
["自然语言处理", "人工智能", "应用", "计算机", "语言"],
["计算机视觉", "人工智能", "分支", "计算机", "视觉"],
]
# 打印算法演示标题
print("=== TF-IDF算法核心原理演示 ===\n")
# 计算TF-IDF
tfidf_results = calculate_tfidf(documents)
# 显示结果
for i, doc_tfidf in enumerate(tfidf_results):
# 打印当前文档的TF-IDF值
print(f"文档 {i+1} 的TF-IDF值:")
# 按TF-IDF值排序显示
sorted_words = sorted(doc_tfidf.items(), key=lambda x: x[1], reverse=True)
for word, score in sorted_words:
print(f" {word}: {score:.4f}")
print()
# 数学原理说明
print("=== 数学公式 ===")
print("TF(t,d) = 词t在文档d中的出现次数 / 文档d的总词数")
print("IDF(t) = log(总文档数 / 包含词t的文档数 + 1)")
print("TF-IDF(t,d) = TF(t,d) × IDF(t)")
print("\n核心思想:词汇重要性 = 在文档中的频率 × 在语料库中的稀有性")
3.1.3 算法整体架构 #
TF-IDF算法分为三个主要阶段:
- TF计算阶段:计算每个词在文档中的频率
- IDF计算阶段:计算每个词在整个语料库中的稀有性
- TF-IDF计算阶段:综合TF和IDF值,得到最终的重要性评分
3.1.4 详细执行流程 #
3.1.4.1 阶段一:TF(词频)计算 #
- 输入处理:接收文档的词列表
- 词频统计:使用
Counter统计每个词的出现次数 - 总词数计算:计算文档的总词数
- TF值计算:
TF = 词频 / 总词数 - 日志输出:记录计算过程和结果
3.1.4.2 阶段二:IDF(逆文档频率)计算 #
- 文档统计:统计语料库中的文档总数
- 词文档频率统计:统计每个词出现在多少个文档中
- IDF值计算:
IDF = log(总文档数 / (包含该词的文档数 + 1)) - 日志输出:记录统计过程和结果
3.1.4.3 阶段三:TF-IDF计算 #
- 遍历文档:对每个文档的TF值进行处理
- 遍历词汇:对文档中的每个词计算TF-IDF值
- 综合计算:
TF-IDF = TF × IDF - 结果存储:将计算结果存储到字典中
- 日志输出:记录每个文档的TF-IDF值
3.1.5 算法核心思想 #
TF-IDF的核心思想是平衡两个因素:
- TF(词频):反映词在文档中的重要性
- IDF(逆文档频率):反映词在整个语料库中的稀有性
3.2. BM25算法:TF-IDF的进化版本 #
BM25是TF-IDF的改进版本,引入了更复杂的参数调节机制,能够更好地处理文档长度差异和词汇饱和效应。虽然计算复杂度更高,但提供了更精确的相关性评估。
3.2.1 特殊参数 #
k_1控制词频对分数的影响程度
$ k_1 $小:你对某个词出现一次就很敏感,出现多次也不会更感兴趣。$ k_1 $大:你对某个词出现多次很在意,出现得越多你越觉得相关。
b用来控制文档长度对分数的影响
b = 0:完全不考虑文档长度,BM25退化为只看词频(TF)和IDF,长文短文一视同仁。b = 1:完全按照文档长度归一化,文档越长,分母越大,词频的作用被削弱。0 < b < 1:部分归一化,b越大,长度归一化作用越强;b越小,长度归一化作用越弱。

3.2.2 代码实现 #
# 导入数学库用于对数计算
import math
# 导入Counter用于统计词频,defaultdict备用
from collections import Counter, defaultdict
# =========================
# BM25参数设置
# =========================
# 词频饱和参数k1,控制词频对分数的影响程度
K1 = 1.5
# 文档长度归一化参数b,控制文档长度对分数的影响
B = 0.75
# =========================
# 计算文档集合的平均长度
# =========================
def average_doc_length(documents):
# 计算所有文档长度之和
total_length = sum(len(doc) for doc in documents)
# 计算文档数量
num_docs = len(documents)
# 日志输出
print(f"[日志] 文档总数: {num_docs},总长度: {total_length}")
# 返回平均长度
avg_length = total_length / num_docs
print(f"[日志] 文档平均长度: {avg_length:.4f}")
return avg_length
# =========================
# 计算BM25的IDF(改进版)
# =========================
def calculate_idf(term, documents):
# 统计文档总数
N = len(documents)
# 统计包含term的文档数
df = sum(1 for doc in documents if term in doc)
# 日志输出
print(f"[日志] 词: {term} 出现于 {df} 个文档, 总文档数: {N}")
# 按照BM25改进公式计算IDF
idf = math.log((N - df + 0.5) / (df + 0.5) + 1)
print(f"[日志] 词: {term} 的IDF值: {idf:.4f}")
return idf
# =========================
# 计算单个文档的BM25分数
# =========================
def bm25_score(query_terms, document, documents, k1=K1, b=B):
# 计算文档集合的平均长度
avgdl = average_doc_length(documents)
# 初始化BM25总分
score = 0.0
# 当前文档长度
doc_len = len(document)
# 统计当前文档的词频
term_freq = Counter(document)
print(f"[日志] 当前文档长度: {doc_len}")
print(f"[日志] 当前文档词频统计: {dict(term_freq)}")
# 遍历每个查询词
for term in query_terms:
# 计算当前词的IDF
idf = calculate_idf(term, documents)
# 当前词在文档中的出现次数
f = term_freq[term]
# 计算分母部分
denom = f + k1 * (1 - b + b * doc_len / avgdl)
# 计算TF部分
tf = (f * (k1 + 1)) / denom if denom != 0 else 0
# 累加BM25分数
score += idf * tf
# 日志输出每个查询词的详细计算过程
print(
f"[日志] 词: {term} | 词频TF: {f} | 分母: {denom:.4f} | TF部分: {tf:.4f} | IDF: {idf:.4f} | BM25项: {idf * tf:.4f}"
)
# 返回总分
print(f"[日志] 当前文档BM25总分: {score:.4f}")
return score
if __name__ == "__main__":
# 示例文档集合(每个文档为分词后的词列表)
documents = [
["人工智能", "计算机科学", "分支", "创建", "系统"],
["机器学习", "人工智能", "子领域", "计算机", "学习"],
["深度学习", "机器学习", "分支", "神经网络", "学习"],
["自然语言处理", "人工智能", "应用", "计算机", "语言"],
["计算机视觉", "人工智能", "分支", "计算机", "视觉"],
]
# 查询词列表
query = ["人工智能", "学习"]
# 打印查询内容
print(f"查询: {' '.join(query)}\n")
# 依次计算每个文档的BM25分数
for i, doc in enumerate(documents):
print(f"------------------------------")
print(f"[日志] 正在计算文档 {i+1} 的BM25分数...")
score = bm25_score(query, doc, documents)
print(f"文档 {i+1} 的BM25分数: {score:.4f}\n")
# 数学原理说明
print("IDF(t) = log((N - df + 0.5) / (df + 0.5) + 1)")
print("TF部分 = (f * (k1 + 1)) / (f + k1 * (1 - b + b * |d|/avgdl))")
print("BM25 = IDF × TF部分,所有查询词累加")
print("\n核心思想:相关性 = 稀有词汇权重 × 词频饱和调整 × 长度归一化")
print("IDF(t) = log((N - df + 0.5) / (df + 0.5) + 1)")
print("TF部分 = (f * (k1 + 1)) / (f + k1 * (1 - b + b * |d|/avgdl))")
print("BM25 = IDF × TF部分,所有查询词累加")
print("\n核心思想:相关性 = 稀有词汇权重 × 词频饱和调整 × 长度归一化")
3.2.3 工作流程 #
1. 计算文档集合的平均长度
avgdl = average_doc_length(documents)- 作用:统计所有文档的平均长度,为后续长度归一化做准备。
- 意义:BM25会根据文档长度和平均长度的比例调整分数,防止长文因词多而分数虚高。
2. 初始化分数和统计当前文档信息
score = 0.0
doc_len = len(document)
term_freq = Counter(document)- 作用:
score:累计BM25总分。doc_len:当前文档的长度。term_freq:统计当前文档中每个词出现的次数(词频)。
3. 遍历每个查询词,逐项累加分数
for term in query_terms:
# 计算IDF
idf = calculate_idf(term, documents)
# 当前词在文档中的词频
f = term_freq[term]
# 计算分母
denom = f + k1 * (1 - b + b * doc_len / avgdl)
# 计算TF部分
tf = (f * (k1 + 1)) / denom if denom != 0 else 0
# 累加BM25分数
score += idf * tf- 详细说明:
- 计算IDF:衡量查询词在所有文档中的稀有程度,稀有词权重高。
- 获取词频f:查询词在当前文档中出现的次数。
- 计算分母:结合词频、文档长度、平均长度和参数k1、b,进行长度归一化和词频饱和处理。
- 计算TF部分:词频加权,体现词频对分数的影响(受k1调节)。
- 累加分数:每个查询词的BM25项累加,得到文档对整个查询的相关性分数。
4. 返回总分
return score- 作用:输出当前文档对查询的BM25相关性分数。
3.3 稠密检索 #
3.3.1 稀疏检索的缺陷 #
尽管稀疏检索在计算效率和可解释性方面表现出色,但它存在一个根本性缺陷:无法理解词汇的语义关系和上下文信息。
词汇顺序敏感性缺失
考虑以下例子:
"我 爱 刘德华" vs "刘德华 爱 我"
- 词汇集合完全一致
- 表达含义完全不同
- 稀疏检索视为相同
这个例子清楚地说明了稀疏检索的局限性:它只能识别词汇的存在性,无法理解词汇间的语义关系。
3.3.2 稠密检索 #
稠密检索通过将文本转换为高维向量空间中的点,实现了从词汇匹配到语义理解的跨越。
Embedding技术:文本的向量化表示
稠密检索的核心是Embedding技术,它将离散的文本符号转换为连续的数值向量。这些向量不仅包含了词汇的语义信息,还编码了词汇间的顺序关系和上下文依赖。
为什么称为"稠密"检索?
传统文本是稀疏的——每个字符都是独立的符号。而Embedding将这种稀疏表示压缩为固定长度的稠密向量,实现了信息的有效编码。这种压缩过程虽然存在信息损失的风险,但大大提升了语义理解的准确性。
3.4 两种范式的融合 #
稀疏检索和稠密检索各有优势:
- 稀疏检索:计算高效、可解释性强、适合精确匹配
- 稠密检索:语义理解能力强、适合模糊查询、支持跨语言检索
在实际应用中,将两种方法结合使用往往能获得最佳效果。这种混合策略能够同时利用统计方法的可靠性和语义方法的灵活性,为信息检索系统提供更强大的能力。
4.查询增强技术 #
在构建智能问答系统时,我们面临着一个核心挑战:用户输入的查询往往存在各种缺陷,这些缺陷直接影响着检索的精准度。
在RAG(检索增强生成)流程中,用户的原始查询需要经过知识库检索来获取相关上下文。然而,用户行为的不确定性导致查询质量参差不齐:
- 语义模糊性:查询表达不清,缺乏关键信息,语义边界模糊
- 信息不完整性:查询过于简短,缺乏必要的上下文信息
- 歧义性问题:查询具有多重含义,容易产生误解
- 复杂度超载:单个查询包含过多子问题或细节信息
这些低质量查询直接导致语义匹配度下降,检索结果精度不足。因此,我们需要引入查询增强技术来优化检索效果。
4.1 伪文档生成法(Query-to-Document) #
这个方案的核心是在查询向量化之前,先使用大语言模型生成伪文档,然后将原始查询与伪文档合并进行检索。
4.1.1 处理流程 #
- 用户输入查询
- 生成伪文档(新增核心步骤)
- 合并查询与伪文档(新增步骤)
- 增强查询向量化
- 向量检索
- 构建Prompt
- 调用大模型生成答案
- 输出答案
4.1.2 技术方案优势 #
- 语义丰富化:伪文档包含回答原始查询所需的关键信息
- 关键词扩展:增加检索词汇,提升稀疏检索效果
- 上下文补充:为原始查询提供必要的背景信息
4.1.3 代码实现 #
Query-to-Document.py
# 导入sentence_transformers库中的SentenceTransformer类
from sentence_transformers import SentenceTransformer
# 导入chromadb库
import chromadb
# 从本地llm.local模块导入ollama_qa函数
from llm.local import ollama_qa
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的Chroma客户端,数据将保存在本地的./chroma_db目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
+# 定义函数:生成伪文档
+def generate_pseudo_document(query):
+ """
+ 使用大语言模型为原始查询生成伪文档
+ 核心思想:利用大语言模型为原始查询生成一个"伪答案文档"
+ """
+ print("[日志] 正在生成伪文档...")
+
+ # 设计伪文档生成的提示词
+ pseudo_doc_prompt = (
+ f"请针对以下问题撰写一段详细的回答,包含相关的背景信息和关键概念:{query}"
+ )
+
+ # 调用大语言模型生成伪文档
+ pseudo_document = ollama_qa(pseudo_doc_prompt)
+
+ print(f"[日志] 伪文档生成完成,长度:{len(pseudo_document)}字符")
+ return pseudo_document
+
+
+# 定义函数:合并查询与伪文档
+def merge_query_with_pseudo_document(query, pseudo_document):
+ """
+ 将原始查询与伪文档合并,形成增强后的查询
+ """
+ print("[日志] 正在合并查询与伪文档...")
+
+ # 合并策略:原始查询 + 伪文档内容
+ enhanced_query = f"{query}\n\n相关背景信息:{pseudo_document}"
+
+ print(f"[日志] 查询合并完成,增强后查询长度:{len(enhanced_query)}字符")
+ return enhanced_query
+
+
# 定义函数:将query转为embedding向量
def get_query_embedding(query):
# 日志:打印正在进行query向量化
print("[日志] 正在将Query转为向量...")
# 使用模型对query进行编码,并转为list格式
return model.encode(query).tolist()
# 定义函数:向量检索,返回最相关的文本块列表
def retrieve_related_chunks(query_embedding, n_results=3):
# 日志:打印正在进行向量检索
print(f"[日志] 正在进行向量检索,返回最相关的{n_results}个文本块...")
# 在集合中进行向量检索,返回最相关的n_results个结果
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
# 获取检索到的文档内容
related_chunks = results.get("documents")
# 如果没有检索到相关内容,则提示并退出程序
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
# 日志:打印检索到的文本块数量
print(f"[日志] 成功检索到{len(related_chunks[0])}个相关文本块。")
# 返回最相关的文本块列表
return related_chunks[0]
# 主程序入口
if __name__ == "__main__":
# 日志:程序启动
print("[日志] 程序启动,准备接受用户输入。")
+ print("[日志] 使用伪文档生成法(Query-to-Document)")
# 1. 用户输入Query
query = input("请输入您的问题:")
# 日志:打印用户输入的Query
print(f"[日志] 用户输入的问题为:{query}")
# 2. 生成伪文档(技术方案一的核心步骤)
+ pseudo_document = generate_pseudo_document(query)
# 3. 合并查询与伪文档,形成增强查询
+ enhanced_query = merge_query_with_pseudo_document(query, pseudo_document)
# 4. 增强查询向量化
+ query_embedding = get_query_embedding(enhanced_query)
# 日志:打印增强查询向量化完成
+ print("[日志] 增强查询向量化完成。")
# 5. 向量检索
related_chunks = retrieve_related_chunks(query_embedding, n_results=3)
# 日志:打印向量检索完成
print("[日志] 向量检索完成。")
# 6. 构建Prompt,将检索到的相关内容拼接为上下文
context = "\n".join(related_chunks)
prompt = f"已知信息:\n{context}\n\n请根据上述内容回答用户问题:{query}"
print("prompt:", prompt)
# 日志:打印Prompt构建完成
print("[日志] Prompt构建完成,准备调用大模型生成答案。")
# 7. 调用大模型生成答案
answer = ollama_qa(prompt)
# 日志:打印答案生成完成
print("[日志] 答案生成完成。")
# 8. 输出答案
print("\n【答案】\n", answer)
4.2 假设文档向量化 #
这个方案的核心是生成多个假设文档,将它们向量化后与原始查询向量进行平均,从而提升检索精度。
4.2.1 处理流程 #
- 用户输入查询
- 生成3个不同角度的假设文档
- 将所有文档(原始查询+假设文档)向量化
- 计算向量平均值
- 使用平均向量进行知识库检索
- 构建Prompt并生成最终答案
4.2.2 技术优势 #
- 多角度语义覆盖:通过不同角度的假设文档,提升语义空间的覆盖范围
- 向量空间优化:平均向量在语义空间中更接近目标文档
- 检索精度提升:增强后的查询向量具有更好的检索召回率
4.2.3 代码实现 #
Hypothetical_Document_Embeddings.py
# 导入sentence_transformers库中的SentenceTransformer类
from sentence_transformers import SentenceTransformer
# 导入chromadb库
import chromadb
+# 导入numpy用于向量计算
+import numpy as np
+
# 从本地llm.local模块导入ollama_qa函数
from llm.local import ollama_qa
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的Chroma客户端,数据将保存在本地的./chroma_db目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
+# 定义函数:多角度生成假设文档
+def generate_hypothetical_documents(query, num_documents=3):
+ """
+ 从不同角度生成多个假设性回答
+ 创新理念:通过多角度假设文档的向量平均来提升检索精度
+ """
+ print(f"[日志] 正在从{num_documents}个不同角度生成假设文档...")
+
+ # 定义不同的角度提示词
+ perspectives = [
+ f"请从学术研究的角度,针对以下问题撰写一段详细的回答:{query}",
+ f"请从实际应用的角度,针对以下问题撰写一段详细的回答:{query}",
+ f"请从基础概念的角度,针对以下问题撰写一段详细的回答:{query}",
+ ]
+
+ hypothetical_documents = []
+
+ # 生成多个假设文档
+ for i, perspective in enumerate(perspectives[:num_documents]):
+ print(f"[日志] 正在生成第{i+1}个假设文档...")
+ doc = ollama_qa(perspective)
+ hypothetical_documents.append(doc)
+ print(f"[日志] 第{i+1}个假设文档生成完成,长度:{len(doc)}字符")
+
+ return hypothetical_documents
+
+
+# 定义函数:将文本转为embedding向量
+def get_text_embedding(text):
+ """将文本转换为embedding向量"""
+ return model.encode(text).tolist()
+
+
+# 定义函数:计算向量平均
+def calculate_average_vectors(vectors):
+ """
+ 计算多个向量的平均值
+ 数学表达:q_final = (q + h_1 + h_2 + ... + h_n) / (n+1)
+ """
+ print("[日志] 正在计算向量平均值...")
+
+ # 将向量列表转换为numpy数组
+ vectors_array = np.array(vectors)
+
+ # 计算平均值
+ average_vector = np.mean(vectors_array, axis=0).tolist()
+
+ print(f"[日志] 向量平均计算完成,参与计算的向量数量:{len(vectors)}")
+ return average_vector
+
+
+# 定义函数:HyDE增强查询向量化
+def hyde_query_embedding(query, num_hypothetical_docs=3):
+ """
+ 假设文档向量化(HyDE)的核心函数
+ 技术流程:
+ 1. 多角度文档生成:从不同角度生成多个假设性回答
+ 2. 向量化处理:将每个假设文档转换为embedding向量
+ 3. 向量平均:计算所有向量的平均值
+ """
+ print("[日志] 开始HyDE(假设文档向量化)处理...")
+
+ # 1. 多角度文档生成
+ hypothetical_docs = generate_hypothetical_documents(query, num_hypothetical_docs)
+
+ # 2. 向量化处理
+ print("[日志] 正在将假设文档转换为向量...")
+ vectors = []
+
+ # 首先添加原始查询向量
+ query_vector = get_text_embedding(query)
+ vectors.append(query_vector)
+ print("[日志] 原始查询向量化完成")
+
+ # 然后添加假设文档向量
+ for i, doc in enumerate(hypothetical_docs):
+ doc_vector = get_text_embedding(doc)
+ vectors.append(doc_vector)
+ print(f"[日志] 第{i+1}个假设文档向量化完成")
+
+ # 3. 向量平均
+ final_query_vector = calculate_average_vectors(vectors)
+
+ print("[日志] HyDE处理完成")
+ return final_query_vector
# 定义函数:向量检索,返回最相关的文本块列表
def retrieve_related_chunks(query_embedding, n_results=3):
# 日志:打印正在进行向量检索
print(f"[日志] 正在进行向量检索,返回最相关的{n_results}个文本块...")
# 在集合中进行向量检索,返回最相关的n_results个结果
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
# 获取检索到的文档内容
related_chunks = results.get("documents")
# 如果没有检索到相关内容,则提示并退出程序
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
# 日志:打印检索到的文本块数量
print(f"[日志] 成功检索到{len(related_chunks[0])}个相关文本块。")
# 返回最相关的文本块列表
return related_chunks[0]
# 主程序入口
if __name__ == "__main__":
# 日志:程序启动
print("[日志] 程序启动,准备接受用户输入。")
+ print("[日志] 使用技术方案二:假设文档向量化(HyDE)")
+
# 1. 用户输入Query
query = input("请输入您的问题:")
# 日志:打印用户输入的Query
print(f"[日志] 用户输入的问题为:{query}")
+ # 2. HyDE增强查询向量化
+ query_embedding = hyde_query_embedding(query, num_hypothetical_docs=3)
+ # 日志:打印HyDE增强查询向量化完成
+ print("[日志] HyDE增强查询向量化完成。")
# 3. 向量检索
related_chunks = retrieve_related_chunks(query_embedding, n_results=3)
# 日志:打印向量检索完成
print("[日志] 向量检索完成。")
# 4. 构建Prompt,将检索到的相关内容拼接为上下文
context = "\n".join(related_chunks)
prompt = f"已知信息:\n{context}\n\n请根据上述内容回答用户问题:{query}"
print("prompt:", prompt)
# 日志:打印Prompt构建完成
print("[日志] Prompt构建完成,准备调用大模型生成答案。")
# 5. 调用大模型生成答案
answer = ollama_qa(prompt)
# 日志:打印答案生成完成
print("[日志] 答案生成完成。")
# 6. 输出答案
print("\n【答案】\n", answer)
4.3 问题分解策略(Sub-Question Decomposition) #
这个方案的核心是将复杂问题拆解为多个子问题,然后并行检索并整合答案。
4.3.1 处理流程 #
- 用户输入复杂查询
- 智能分解:将复杂问题拆解为3-5个子问题
- 并行检索:每个子问题独立检索,获得相关文本块
- 去重合并:合并所有检索结果并去重
- 答案整合:基于所有检索信息生成最终答案
- 输出全面、准确的最终答案
4.3.2 应用场景优势 #
- 复杂多层次查询:针对包含多个子问题的复杂查询
- 语义信息保护:避免直接检索导致的语义信息丢失
- 全面覆盖:确保原始问题的所有方面都得到处理
4.3.3 代码实现 #
Sub_Question_Decomposition.py
# 导入sentence_transformers库中的SentenceTransformer类
from sentence_transformers import SentenceTransformer
# 导入chromadb库
import chromadb
+# 导入json用于处理子问题列表
+import json
+
# 从本地llm.local模块导入ollama_qa函数
from llm.local import ollama_qa
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的Chroma客户端,数据将保存在本地的./chroma_db目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
+# 定义函数:智能分解复杂问题
+def decompose_complex_query(query):
+ """
+ 利用大语言模型将复杂问题拆解为语义相关的子问题
+ 应用场景:针对复杂多层次的用户查询,直接检索往往会导致部分语义信息丢失
+ """
+ print("[日志] 正在分解复杂问题...")
+
+ # 设计问题分解的提示词
+ decomposition_prompt = f"""
+任务:将用户的复杂问题分解为一系列相关的小问题,以帮助更好地检索相关信息。
+
+要求:
+- 子问题必须与原始问题高度相关
+- 每个子问题应该明确具体
+- 子问题组合应覆盖原始问题的所有方面
+
+用户问题:{query}
+
+请将上述问题分解为3-5个子问题,以JSON格式返回:
+{{
+ "sub_questions": [
+ "子问题1",
+ "子问题2",
+ "子问题3"
+ ]
+}}
+"""
+
+ # 调用大语言模型进行问题分解
+ decomposition_result = ollama_qa(decomposition_prompt)
+
+ try:
+ # 尝试解析JSON格式的响应
+ if "{" in decomposition_result and "}" in decomposition_result:
+ # 提取JSON部分
+ json_start = decomposition_result.find("{")
+ json_end = decomposition_result.rfind("}") + 1
+ json_str = decomposition_result[json_start:json_end]
+ parsed_result = json.loads(json_str)
+ sub_questions = parsed_result.get("sub_questions", [])
+ else:
+ # 如果无法解析JSON,尝试从文本中提取子问题
+ lines = decomposition_result.split("\n")
+ sub_questions = []
+ for line in lines:
+ line = line.strip()
+ if line and (
+ line.startswith("-")
+ or line.startswith("•")
+ or line.startswith("1.")
+ or line.startswith("2.")
+ or line.startswith("3.")
+ ):
+ # 移除前缀
+ question = line.lstrip("-•1234567890. ")
+ if question:
+ sub_questions.append(question)
+
+ # 如果还是没有提取到,将原始问题作为唯一子问题
+ if not sub_questions:
+ sub_questions = [query]
+ except:
+ # 解析失败时,将原始问题作为唯一子问题
+ sub_questions = [query]
+
+ print(f"[日志] 问题分解完成,生成了{len(sub_questions)}个子问题")
+ for i, sub_q in enumerate(sub_questions):
+ print(f"[日志] 子问题{i+1}: {sub_q}")
+
+ return sub_questions
+
+
# 定义函数:将query转为embedding向量
def get_query_embedding(query):
# 日志:打印正在进行query向量化
print("[日志] 正在将Query转为向量...")
# 使用模型对query进行编码,并转为list格式
return model.encode(query).tolist()
# 定义函数:向量检索,返回最相关的文本块列表
def retrieve_related_chunks(query_embedding, n_results=3):
# 日志:打印正在进行向量检索
print(f"[日志] 正在进行向量检索,返回最相关的{n_results}个文本块...")
# 在集合中进行向量检索,返回最相关的n_results个结果
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
# 获取检索到的文档内容
related_chunks = results.get("documents")
# 如果没有检索到相关内容,则提示并退出程序
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
# 日志:打印检索到的文本块数量
print(f"[日志] 成功检索到{len(related_chunks[0])}个相关文本块。")
# 返回最相关的文本块列表
return related_chunks[0]
+# 定义函数:并行检索子问题
+def parallel_retrieve_sub_questions(sub_questions, n_results_per_question=2):
+ """
+ 每个子问题独立进行知识库检索
+ 技术架构:复杂查询 → 子问题分解 → 并行检索 → 答案整合 → 最终回答
+ """
+ print("[日志] 开始并行检索子问题...")
+
+ all_related_chunks = []
+
+ for i, sub_question in enumerate(sub_questions):
+ print(f"[日志] 正在检索子问题{i+1}: {sub_question}")
+
+ # 将子问题向量化
+ sub_question_embedding = get_query_embedding(sub_question)
+
+ # 检索相关文本块
+ related_chunks = retrieve_related_chunks(
+ sub_question_embedding, n_results_per_question
+ )
+
+ # 将检索结果添加到总列表中
+ all_related_chunks.extend(related_chunks)
+
+ print(f"[日志] 子问题{i+1}检索完成,获得{len(related_chunks)}个文本块")
+
+ # 去重并合并所有检索结果
+ unique_chunks = list(set(all_related_chunks))
+ print(f"[日志] 并行检索完成,总共获得{len(unique_chunks)}个唯一文本块")
+
+ return unique_chunks
+
+
+# 定义函数:答案整合
+def integrate_answers(original_query, all_related_chunks):
+ """
+ 将各子问题的检索结果和答案进行综合处理
+ 实现机制:答案融合:将各子问题的检索结果和答案进行综合处理
+ """
+ print("[日志] 正在整合答案...")
+
+ # 构建整合提示词
+ context = "\n".join(all_related_chunks)
+ integration_prompt = f"""
+基于以下检索到的相关信息,请回答用户的原始问题。
+
+检索到的相关信息:
+{context}
+
+用户原始问题:{original_query}
+
+请提供一个全面、准确的回答,确保:
+1. 回答覆盖原始问题的所有方面
+2. 基于检索到的信息进行回答
+3. 如果信息不足,请明确指出
+4. 保持逻辑清晰,结构合理
+
+回答:
+"""
+
+ # 调用大语言模型生成最终答案
+ final_answer = ollama_qa(integration_prompt)
+
+ print("[日志] 答案整合完成")
+ return final_answer
+
+
# 主程序入口
if __name__ == "__main__":
# 日志:程序启动
print("[日志] 程序启动,准备接受用户输入。")
+ print("[日志] 使用问题分解策略(Sub-Question Decomposition)")
+
# 1. 用户输入Query
query = input("请输入您的问题:")
# 日志:打印用户输入的Query
print(f"[日志] 用户输入的问题为:{query}")
+ # 2. 智能分解复杂问题
+ sub_questions = decompose_complex_query(query)
+ # 3. 并行检索子问题
+ all_related_chunks = parallel_retrieve_sub_questions(
+ sub_questions, n_results_per_question=2
+ )
+ # 日志:打印并行检索完成
+ print("[日志] 并行检索完成。")
+ # 4. 答案整合
+ final_answer = integrate_answers(query, all_related_chunks)
+ # 日志:打印答案整合完成
+ print("[日志] 答案整合完成。")
+ # 5. 输出最终答案
+ print("\n【最终答案】\n", final_answer)
4.4 多角度查询重写(Query Rewriting) #
这个方案的核心是通过多角度重构来提升查询质量,解决表达不清、措辞不当或信息缺失的问题。
4.4.1 处理流程 #
- 用户输入查询
- 多版本生成:生成3-5个不同表达方式的查询版本
- 并行检索:使用所有查询版本同时进行知识库检索
- 结果整合:将多个检索结果合并,形成更全面的上下文信息
- 答案生成:基于整合的上下文生成最终答案
- 输出准确、全面的最终答案
4.4.2 技术优势 #
- 查询质量提升:通过多角度重写解决表达问题
- 检索覆盖增强:多个查询版本提供更全面的检索覆盖
- 上下文丰富化:整合多个检索结果形成更丰富的上下文
- 容错能力强:具有完善的错误处理机制
4.4.3 代码实现 #
Query_Rewriting.py
# 导入sentence_transformers库中的SentenceTransformer类
from sentence_transformers import SentenceTransformer
# 导入chromadb库
import chromadb
+# 导入json用于处理查询版本列表
+import json
+
# 从本地llm.local模块导入ollama_qa函数
from llm.local import ollama_qa
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的Chroma客户端,数据将保存在本地的./chroma_db目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
+# 定义函数:多角度查询重写
+def rewrite_query_multiple_versions(original_query):
+ """
+ 基于原始查询生成多个不同表达方式的查询版本
+ 问题识别:当用户查询存在表达不清、措辞不当或信息缺失时,检索性能会显著下降
+ """
+ print("[日志] 正在进行多角度查询重写...")
+
+ # 设计查询重写的提示词
+ rewriting_prompt = f"""
+请对以下用户查询进行多角度重写,生成3-5个不同表达方式的查询版本。
+
+要求:
+1. 保持原始查询的核心语义不变
+2. 使用不同的表达方式和措辞
+3. 可以补充相关的关键词或概念
+4. 考虑不同的查询意图和表达习惯
+5. 确保每个重写版本都是完整、清晰的查询
+
+原始查询:{original_query}
+
+请以JSON格式返回重写结果:
+{{
+ "rewritten_queries": [
+ "重写版本1",
+ "重写版本2",
+ "重写版本3"
+ ]
+}}
+"""
+
+ # 调用大语言模型进行查询重写
+ rewriting_result = ollama_qa(rewriting_prompt)
+
+ try:
+ # 尝试解析JSON格式的响应
+ if "{" in rewriting_result and "}" in rewriting_result:
+ # 提取JSON部分
+ json_start = rewriting_result.find("{")
+ json_end = rewriting_result.rfind("}") + 1
+ json_str = rewriting_result[json_start:json_end]
+ parsed_result = json.loads(json_str)
+ rewritten_queries = parsed_result.get("rewritten_queries", [])
+ else:
+ # 如果无法解析JSON,尝试从文本中提取重写版本
+ lines = rewriting_result.split("\n")
+ rewritten_queries = []
+ for line in lines:
+ line = line.strip()
+ if line and (
+ line.startswith("-")
+ or line.startswith("•")
+ or line.startswith("1.")
+ or line.startswith("2.")
+ or line.startswith("3.")
+ ):
+ # 移除前缀
+ query = line.lstrip("-•1234567890. ")
+ if query:
+ rewritten_queries.append(query)
+
+ # 如果还是没有提取到,将原始查询作为唯一版本
+ if not rewritten_queries:
+ rewritten_queries = [original_query]
+ except:
+ # 解析失败时,将原始查询作为唯一版本
+ rewritten_queries = [original_query]
+
+ # 确保包含原始查询
+ if original_query not in rewritten_queries:
+ rewritten_queries.insert(0, original_query)
+
+ print(f"[日志] 查询重写完成,生成了{len(rewritten_queries)}个查询版本")
+ for i, query in enumerate(rewritten_queries):
+ print(f"[日志] 查询版本{i+1}: {query}")
+
+ return rewritten_queries
+
+
# 定义函数:将query转为embedding向量
def get_query_embedding(query):
# 日志:打印正在进行query向量化
print("[日志] 正在将Query转为向量...")
# 使用模型对query进行编码,并转为list格式
return model.encode(query).tolist()
# 定义函数:向量检索,返回最相关的文本块列表
def retrieve_related_chunks(query_embedding, n_results=3):
# 日志:打印正在进行向量检索
print(f"[日志] 正在进行向量检索,返回最相关的{n_results}个文本块...")
# 在集合中进行向量检索,返回最相关的n_results个结果
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
# 获取检索到的文档内容
related_chunks = results.get("documents")
# 如果没有检索到相关内容,则提示并退出程序
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
# 日志:打印检索到的文本块数量
print(f"[日志] 成功检索到{len(related_chunks[0])}个相关文本块。")
# 返回最相关的文本块列表
return related_chunks[0]
+# 定义函数:并行检索多个查询版本
+def parallel_retrieve_multiple_queries(rewritten_queries, n_results_per_query=2):
+ """
+ 使用所有查询版本同时进行知识库检索
+ 技术方法:并行检索:使用所有查询版本同时进行知识库检索
+ """
+ print("[日志] 开始并行检索多个查询版本...")
+
+ all_related_chunks = []
+
+ for i, query in enumerate(rewritten_queries):
+ print(f"[日志] 正在检索查询版本{i+1}: {query}")
+
+ # 将查询版本向量化
+ query_embedding = get_query_embedding(query)
+
+ # 检索相关文本块
+ related_chunks = retrieve_related_chunks(query_embedding, n_results_per_query)
+
+ # 将检索结果添加到总列表中
+ all_related_chunks.extend(related_chunks)
+
+ print(f"[日志] 查询版本{i+1}检索完成,获得{len(related_chunks)}个文本块")
+
+ # 去重并合并所有检索结果
+ unique_chunks = list(set(all_related_chunks))
+ print(f"[日志] 并行检索完成,总共获得{len(unique_chunks)}个唯一文本块")
+
+ return unique_chunks
+
+
+# 定义函数:上下文整合
+def integrate_context_and_generate_answer(original_query, all_related_chunks):
+ """
+ 将多个检索结果合并,形成更全面的上下文信息
+ 技术方法:结果整合:将多个检索结果合并,形成更全面的上下文信息
+ """
+ print("[日志] 正在整合上下文并生成答案...")
+
+ # 构建整合提示词
+ context = "\n".join(all_related_chunks)
+ integration_prompt = f"""
+基于以下从多个查询版本检索到的相关信息,请回答用户的原始问题。
+
+检索到的相关信息:
+{context}
+
+用户原始问题:{original_query}
+
+请提供一个准确、全面的回答,确保:
+1. 直接回答用户的原始问题
+2. 充分利用检索到的相关信息
+3. 如果信息不足,请明确指出
+4. 保持回答的连贯性和逻辑性
+
+回答:
+"""
+
+ # 调用大语言模型生成最终答案
+ final_answer = ollama_qa(integration_prompt)
+
+ print("[日志] 上下文整合和答案生成完成")
+ return final_answer
+
+
# 主程序入口
if __name__ == "__main__":
# 日志:程序启动
print("[日志] 程序启动,准备接受用户输入。")
+ print("[日志] 使用多角度查询重写(Query Rewriting)")
+
# 1. 用户输入Query
query = input("请输入您的问题:")
# 日志:打印用户输入的Query
print(f"[日志] 用户输入的问题为:{query}")
+ # 2. 多角度查询重写
+ rewritten_queries = rewrite_query_multiple_versions(query)
+ # 3. 并行检索多个查询版本
+ all_related_chunks = parallel_retrieve_multiple_queries(
+ rewritten_queries, n_results_per_query=2
+ )
+ # 日志:打印并行检索完成
+ print("[日志] 并行检索完成。")
+ # 4. 上下文整合和答案生成
+ final_answer = integrate_context_and_generate_answer(query, all_related_chunks)
# 日志:打印答案生成完成
print("[日志] 答案生成完成。")
+ # 5. 输出最终答案
+ print("\n【最终答案】\n", final_answer)
4.5. 抽象化查询转换(Take a Step Back) #
这个方案的核心是通过"退后一步"的方式,将具体问题转化为更高层次的抽象问题。
4.5.1 处理流程 #
- 用户输入具体查询
- 抽象化转换:将具体问题转化为抽象问题
- 混合检索:
- 使用抽象化查询进行广泛检索(5个结果)
- 使用原始查询进行精确检索(3个结果)
- 结果合并:合并检索结果并去重
- 答案生成:基于混合检索结果生成最终答案
- 输出准确、全面的最终答案
4.5.2 技术优势 #
- 提升召回率:抽象化查询能够匹配更多相关文档
- 减少过拟合:避免因具体细节导致的检索偏差
- 增强泛化性:提高系统对类似问题的处理能力
4.5.3 代码实现 #
Take_a_Step_Back.py
# 导入sentence_transformers库中的SentenceTransformer类
from sentence_transformers import SentenceTransformer
# 导入chromadb库
import chromadb
+# 导入json用于处理抽象化查询
+import json
+
# 从本地llm.local模块导入ollama_qa函数
from llm.local import ollama_qa
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的Chroma客户端,数据将保存在本地的./chroma_db目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
+# 定义函数:抽象化查询转换
+def abstractify_query(original_query):
+ """
+ 将具体问题转化为更高层次的抽象问题
+ 核心洞察:当用户查询过于具体和详细时,大量细节信息可能掩盖了真正的核心问题
+ """
+ print("[日志] 正在进行抽象化查询转换...")
+
+ # 设计抽象化转换的提示词
+ abstraction_prompt = f"""
+请对以下用户查询进行抽象化转换,将其转化为更高层次的抽象问题。
+
+技术原理:
+1. 细节剥离:去除查询中的具体细节信息(如具体时间、地点、人名等)
+2. 概念抽象:将具体问题转化为通用概念
+3. 范围扩展:扩大查询的语义范围
+
+用户查询:{original_query}
+
+请生成一个抽象化的查询版本,要求:
+1. 保持原始查询的核心意图
+2. 去除过于具体的细节信息
+3. 使用更通用的概念和表达
+4. 扩大查询的语义范围
+5. 确保抽象化后的查询仍然有意义
+
+请以JSON格式返回结果:
+{{
+ "abstract_query": "抽象化后的查询",
+ "abstraction_reason": "抽象化的原因说明"
+}}
+"""
+
+ # 调用大语言模型进行抽象化转换
+ abstraction_result = ollama_qa(abstraction_prompt)
+
+ try:
+ # 尝试解析JSON格式的响应
+ if "{" in abstraction_result and "}" in abstraction_result:
+ # 提取JSON部分
+ json_start = abstraction_result.find("{")
+ json_end = abstraction_result.rfind("}") + 1
+ json_str = abstraction_result[json_start:json_end]
+ parsed_result = json.loads(json_str)
+ abstract_query = parsed_result.get("abstract_query", original_query)
+ abstraction_reason = parsed_result.get("abstraction_reason", "抽象化转换")
+ else:
+ # 如果无法解析JSON,尝试从文本中提取抽象化查询
+ lines = abstraction_result.split("\n")
+ abstract_query = original_query
+ abstraction_reason = "自动抽象化转换"
+
+ for line in lines:
+ line = line.strip()
+ if (
+ line
+ and not line.startswith("-")
+ and not line.startswith("•")
+ and not line.startswith("1.")
+ and not line.startswith("2.")
+ and not line.startswith("3.")
+ ):
+ if len(line) > 10 and len(line) < 200: # 合理的查询长度
+ abstract_query = line
+ break
+ except:
+ # 解析失败时,保持原始查询
+ abstract_query = original_query
+ abstraction_reason = "解析失败,保持原始查询"
+
+ print(f"[日志] 抽象化转换完成")
+ print(f"[日志] 原始查询: {original_query}")
+ print(f"[日志] 抽象化查询: {abstract_query}")
+ print(f"[日志] 抽象化原因: {abstraction_reason}")
+
+ return abstract_query, abstraction_reason
+
+
# 定义函数:将query转为embedding向量
def get_query_embedding(query):
# 日志:打印正在进行query向量化
print("[日志] 正在将Query转为向量...")
# 使用模型对query进行编码,并转为list格式
return model.encode(query).tolist()
# 定义函数:向量检索,返回最相关的文本块列表
def retrieve_related_chunks(query_embedding, n_results=3):
# 日志:打印正在进行向量检索
print(f"[日志] 正在进行向量检索,返回最相关的{n_results}个文本块...")
# 在集合中进行向量检索,返回最相关的n_results个结果
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
# 获取检索到的文档内容
related_chunks = results.get("documents")
# 如果没有检索到相关内容,则提示并退出程序
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
# 日志:打印检索到的文本块数量
print(f"[日志] 成功检索到{len(related_chunks[0])}个相关文本块。")
# 返回最相关的文本块列表
return related_chunks[0]
+# 定义函数:基于抽象化查询的检索
+def retrieve_with_abstract_query(abstract_query, n_results=5):
+ """
+ 使用抽象化查询进行知识库检索
+ 技术优势:
+ - 提升召回率:抽象化查询能够匹配更多相关文档
+ - 减少过拟合:避免因具体细节导致的检索偏差
+ - 增强泛化性:提高系统对类似问题的处理能力
+ """
+ print("[日志] 使用抽象化查询进行检索...")
+
+ # 将抽象化查询向量化
+ abstract_query_embedding = get_query_embedding(abstract_query)
+
+ # 使用抽象化查询进行检索,增加检索数量以获得更多相关文档
+ related_chunks = retrieve_related_chunks(abstract_query_embedding, n_results)
+
+ print(f"[日志] 抽象化查询检索完成,获得{len(related_chunks)}个相关文本块")
+ return related_chunks
+
+
+# 定义函数:基于原始查询的精确检索
+def retrieve_with_original_query(original_query, n_results=3):
+ """
+ 使用原始查询进行精确检索
+ 用于在抽象化检索的基础上进行精确匹配
+ """
+ print("[日志] 使用原始查询进行精确检索...")
+
+ # 将原始查询向量化
+ original_query_embedding = get_query_embedding(original_query)
+
+ # 使用原始查询进行精确检索
+ related_chunks = retrieve_related_chunks(original_query_embedding, n_results)
+
+ print(f"[日志] 原始查询精确检索完成,获得{len(related_chunks)}个相关文本块")
+ return related_chunks
+
+
+# 定义函数:混合检索和答案生成
+def hybrid_retrieve_and_answer(original_query, abstract_query, abstraction_reason):
+ """
+ 结合抽象化查询和原始查询进行混合检索
+ 技术原理:通过抽象化转换扩大检索范围,再结合原始查询进行精确匹配
+ """
+ print("[日志] 开始混合检索...")
+
+ # 1. 使用抽象化查询进行广泛检索
+ abstract_chunks = retrieve_with_abstract_query(abstract_query, n_results=5)
+
+ # 2. 使用原始查询进行精确检索
+ original_chunks = retrieve_with_original_query(original_query, n_results=3)
+
+ # 3. 合并检索结果并去重
+ all_chunks = abstract_chunks + original_chunks
+ unique_chunks = list(set(all_chunks))
+
+ print(f"[日志] 混合检索完成,总共获得{len(unique_chunks)}个唯一文本块")
+
+ # 4. 构建答案生成提示词
+ context = "\n".join(unique_chunks)
+ answer_prompt = f"""
+基于以下检索到的相关信息,请回答用户的原始问题。
+
+检索到的相关信息:
+{context}
+
+用户原始问题:{original_query}
+
+注意:系统使用了抽象化查询转换技术来扩大检索范围。
+- 原始查询:{original_query}
+- 抽象化查询:{abstract_query}
+- 抽象化原因:{abstraction_reason}
+
+请提供一个准确、全面的回答,确保:
+1. 直接回答用户的原始问题
+2. 充分利用检索到的相关信息
+3. 如果信息不足,请明确指出
+4. 保持回答的准确性和相关性
+
+回答:
+"""
+
+ # 5. 生成最终答案
+ final_answer = ollama_qa(answer_prompt)
+
+ print("[日志] 混合检索和答案生成完成")
+ return final_answer
+
+
# 主程序入口
if __name__ == "__main__":
# 日志:程序启动
print("[日志] 程序启动,准备接受用户输入。")
+ print("[日志] 使用抽象化查询转换(Take a Step Back)")
+
# 1. 用户输入Query
query = input("请输入您的问题:")
# 日志:打印用户输入的Query
print(f"[日志] 用户输入的问题为:{query}")
+ # 2. 抽象化查询转换
+ abstract_query, abstraction_reason = abstractify_query(query)
+ # 3. 混合检索和答案生成
+ final_answer = hybrid_retrieve_and_answer(query, abstract_query, abstraction_reason)
# 日志:打印答案生成完成
print("[日志] 答案生成完成。")
+ # 4. 输出最终答案
+ print("\n【最终答案】\n", final_answer)
4.6. 检索-生成一体化设计 #
在RAG(检索增强生成)系统落地企业私有知识库时,常常会遇到检索不准、答案无关等实际难题。要想有效提升问答系统的表现,建议从系统设计阶段就进行如下优化:
首先,务必根据实际业务场景,提前梳理并区分不同类型的用户问题。例如,在企业内部的人事政策问答场景中,员工可能会咨询“年假如何申请”“产假政策是什么”“调岗流程有哪些”等多种问题。针对这些不同类别的问题,建议分别建立专属的知识库,并为每类知识库定制最合适的检索方式和query重写策略。
这样一来,当系统通过意图识别模块判断出用户的具体需求后,就能自动采用最优的检索逻辑。例如,针对“假期政策”类问题,知识库可以按照“假期类型+适用对象+流程说明”进行结构化整理。此时,检索时只需提取出“假期类型”(如年假、病假、产假等)作为关键词,就能大幅提升相关内容的命中率。
但实际对话中,员工的提问往往非常口语化,比如“我下个月要结婚,能请几天假?”、“家里人生病了,公司有相关假期吗?”等。这些问题并不会直接出现“婚假”“病假”这样的标准术语。如果直接用原始提问去检索知识库,极有可能得不到准确答案。 为了解决这一问题,建议在知识库搭建阶段就同步设计好query重写机制。可以借助大模型的语义理解能力,先让模型识别出用户提问中隐含的“假期类型”,再用标准术语作为检索关键词。例如,模型可以将“结婚请假”自动归类为“婚假”,将“家人生病请假”归类为“病假”,然后用这些标准词汇去检索知识库。
当前主流大模型(如豆包、Deepseek、通义千问等)在预训练阶段已经积累了丰富的常识和语义理解能力,完全可以胜任上述任务。只需设计合适的提示词,让模型先抽取出标准术语,再用其进行检索,就能显著提升问答的准确率和相关性。 综上所述,知识库的结构设计与query重写策略应当协同规划,不能割裂开来。只有在知识库建设时就同步考虑检索方式和query重写机制,才能确保RAG系统在实际应用中的高效与稳定。这种“检索-生成一体化设计”理念,是企业智能问答系统成功的关键。
4.6.1. output_slot.py #
output_slot.py
+# 企业人事政策问答RAG主流程
from sentence_transformers import SentenceTransformer
import chromadb
from llm.local import ollama_qa
model = SentenceTransformer("all-MiniLM-L6-v2")
client = chromadb.PersistentClient(path="./chroma_db")
collection = client.get_or_create_collection("rag_collection")
+# 用大模型先识别假期类型(query重写),再检索
+def rewrite_query_with_leave_type(query):
+ # 这里用ollama_qa模拟大模型意图识别,实际可替换为更强的NLU
+ prompt = (
+ "请从下列员工提问中识别出最相关的假期类型(如年假、病假、婚假、产假等),"
+ "只输出假期类型标准词汇,不要输出其他内容。\n"
+ f"员工提问:{query}\n"
+ "假期类型:"
+ )
+ leave_type = ollama_qa(prompt)
+ print(f"[日志] 识别到假期类型:{leave_type}")
+ return leave_type.strip() if leave_type else query
+
+
def get_query_embedding(query):
print("[日志] 正在将Query转为向量...")
return model.encode(query).tolist()
def retrieve_related_chunks(query_embedding, n_results=3):
print(f"[日志] 正在进行向量检索,返回最相关的{n_results}个文本块...")
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
related_chunks = results.get("documents")
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
print(f"[日志] 成功检索到{len(related_chunks[0])}个相关文本块。")
return related_chunks[0]
if __name__ == "__main__":
+ print("[企业人事政策智能问答系统] 启动")
+ # query = input("请输入您的问题(如:我下个月要结婚,能请几天假?):")
+ query = "我下个月要结婚,能请几天假?"
print(f"[日志] 用户输入的问题为:{query}")
+ # 1. query重写:识别假期类型
+ leave_type = rewrite_query_with_leave_type(query)
+ # 2. 用假期类型标准词汇检索
+ query_embedding = get_query_embedding(leave_type)
print("[日志] Query向量化完成。")
related_chunks = retrieve_related_chunks(query_embedding, n_results=3)
print("[日志] 向量检索完成。")
+ # 3. 构建Prompt,将检索到的相关内容拼接为上下文
context = "\n".join(related_chunks)
+ prompt = f"已知信息:\n{context}\n\n请根据上述内容回答员工问题:{query}"
print("prompt:", prompt)
print("[日志] Prompt构建完成,准备调用大模型生成答案。")
+ # 4. 调用大模型生成答案
answer = ollama_qa(prompt)
print("[日志] 答案生成完成。")
print("\n【答案】\n", answer)
4.6.2. input_slot.py #
input_slot.py
+# 企业人事政策知识库入库脚本
import os
from vectorstore.db import save_text_to_db
# 导入各类文件解析函数
from parser.pdf import extract_pdf_text
from parser.word import extract_text_from_word
from parser.excel import extract_text_from_excel
from parser.ppt import extract_ppt_text
from parser.htm import extract_text_from_html
from parser.xmls import extract_xml_text
from parser.csvs import read_csv_to_text
from splitter.text_splitter import RecursiveCharacterTextSplitter
import logging
logging.basicConfig(
level=logging.INFO, format="%(asctime)s [%(levelname)s] %(message)s"
)
def extract_text_auto(file_path):
ext = os.path.splitext(file_path)[-1].lower()
if ext == ".pdf":
logging.info(f"检测到PDF文件,开始提取文本: {file_path}")
return extract_pdf_text(file_path)
elif ext in [".docx", ".doc"]:
logging.info(f"检测到Word文件,开始提取文本: {file_path}")
return extract_text_from_word(file_path)
elif ext in [".xlsx", ".xls"]:
logging.info(f"检测到Excel文件,开始提取文本: {file_path}")
return extract_text_from_excel(file_path)
elif ext in [".pptx", ".ppt"]:
logging.info(f"检测到PPT文件,开始提取文本: {file_path}")
return extract_ppt_text(file_path)
elif ext in [".html", ".htm"]:
logging.info(f"检测到HTML文件,开始提取文本: {file_path}")
return extract_text_from_html(file_path)
elif ext == ".xml":
logging.info(f"检测到XML文件,开始提取文本: {file_path}")
return extract_xml_text(file_path)
elif ext == ".csv":
logging.info(f"检测到CSV文件,开始提取文本: {file_path}")
return read_csv_to_text(file_path)
elif ext in [".md", ".txt", ".jsonl"]:
logging.info(f"检测到文本/Markdown/JSONL文件,开始读取: {file_path}")
with open(file_path, "r", encoding="utf-8") as f:
return f.read()
else:
logging.error(f"不支持的文件类型: {ext}")
raise ValueError("不支持的文件类型: " + ext)
def doc_to_vectorstore(file_path, collection_name="rag_collection"):
# 1. 非结构化文本加载
logging.info(f"开始提取文件内容: {file_path}")
text = extract_text_auto(file_path)
logging.info(f"文件内容提取完成,长度为{len(text)}个字符")
# 2. 文本分块
logging.info("开始进行文本分块")
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=30)
chunks = splitter.split_text(text)
logging.info(f"文本分块完成,共分为{len(chunks)}块")
# 3. 嵌入并保存到向量数据库
for idx, chunk in enumerate(chunks):
logging.info(f"正在保存第{idx+1}/{len(chunks)}块到向量数据库")
save_text_to_db(chunk, collection_name=collection_name)
+ print(f"【入库完成】文件 {file_path} 已完成入库,共分块 {len(chunks)} 个。")
logging.info(f"文件 {file_path} 已全部分块并入库完成")
+ print(
+ "【提示】建议将人事政策类知识库按“假期类型+适用对象+流程说明”结构化整理,以便后续高效检索。"
+ )
if __name__ == "__main__":
+ print("【企业人事政策知识库入库】")
+ file_path = "vocation.jsonl"
doc_to_vectorstore(file_path)
4.7. 上下文对话 #
在实际的智能问答系统中,用户与AI往往会经历多轮对话,可能是三五轮,也可能是十几轮。每一轮的交流都为后续问题提供了丰富的上下文信息。事实上,绝大多数检索型问答场景下,系统都不能仅凭用户的最后一句提问直接检索知识库,而是需要结合整个对话历史,综合分析后生成更精准的检索query。
不同类型的问题,所需的query归纳方式和提示词也各不相同。例如,有些问题需要AI根据全部历史对话内容,提炼出一个完整的检索意图;而有些则需要识别出问题的类别或主题,再据此生成合适的检索表达。
举个例子:假如用户与系统已经就某个产品进行了多轮沟通,最后突然问“保修期多长?”如果只用这句话去检索,往往得不到有用的答案。此时,系统应当结合之前的对话内容,推断出用户具体指的是哪款产品、购买时间等关键信息,然后生成如“2022年购买的X产品保修期多长”这样的完整query,才能实现高效检索。
再比如,用户问“哪个保修时间更长?”这类问题通常涉及多个对象。系统需要回溯对话,识别出所有被提及的产品,并分别生成针对每个产品的检索query,如“产品A保修期多长”“产品B保修期多长”,然后分别检索并对比结果,最终给出综合性回答。
近年来,业界提出了“Agentic RAG”理念,即在传统RAG流程前增加智能体(Agent)环节。Agent负责分析用户的最新问题及全部上下文,制定检索计划:需要生成多少条query?每条query的内容和顺序如何?是否需要分别检索不同的知识库?只有经过这样的智能规划,才能应对真实业务中复杂多变的提问场景。
常见的query归纳类型包括:
- 上下文依赖型:需要结合历史对话补全关键信息。
- 对比型:涉及多个对象,需要分别检索并对比。
- 模糊指代型:如“都支持无线充电吗?”需识别“都”指代的具体对象。
- 多意图型:一句话中包含多个问题,如“有红色吗?多大码?什么时候能到货?”
- 反问型:如“这个不会也要等一个月吧?”实际意图是询问具体等待周期。
- 条件型:如“如果我明天购买,能享受什么优惠?”需要将条件转化为检索参数。
当然,实际业务中还会遇到更多特殊场景。每个行业、每个企业的知识库和用户需求都不尽相同,因此,query归纳与改写机制必须灵活可扩展,才能保证问答系统的高效与准确。
4.7.1 query归纳类型 #
4.7.1.1. 上下文依赖型 #
历史对话:
用户:我最近买了个智能手表。
AI:请问您购买的是哪个品牌或型号?
用户:是Alpha智能手表,去年买的。
AI:请问有什么可以帮您解答的问题吗?用户最新问题:
保修期还有多久?(需要结合历史对话,补全“Alpha智能手表”“2022年购买”等关键信息)
4.7.1.2. 对比型 #
历史对话:
用户:我在看Beta蓝牙耳机和Gamma智能音箱,想了解一下售后政策。
AI:Beta蓝牙耳机和Gamma智能音箱的售后政策您想了解哪些方面?
用户:主要是保修时间。用户最新问题:
哪个产品保修期更长?(涉及多个对象,需要分别检索并对比)
4.7.1.3. 模糊指代型 #
历史对话:
用户:我买了你们家的笔记本电脑和平板电脑。
AI:请问是Delta笔记本电脑和Epsilon平板电脑吗?
用户:对的。
AI:请问您想咨询哪方面的问题?用户最新问题:
它们都支持无线充电吗?(“它们”指代多个产品,需要识别具体对象)
4.7.1.4. 多意图型 #
历史对话:
用户:我想买Zeta无线充电器。
AI:请问您对Zeta无线充电器有哪些具体需求?用户最新问题:
有白色款吗?保修多久?坏了怎么售后?(一句话中包含多个问题:颜色、保修、售后流程)
4.7.1.5. 反问型 #
历史对话:
用户:我上次买的Epsilon平板电脑,售后流程很麻烦。
AI:很抱歉给您带来不便,请问这次您遇到什么问题了吗?
用户:这次是屏幕坏了,想申请售后。用户最新问题:
不会又要寄修等一个月吧?(实际意图是询问Epsilon平板电脑的售后周期)
4.7.1.6. 条件型 #
历史对话:
用户:我准备最近买一台Delta笔记本电脑。
AI:感谢您的关注,请问您还有其他疑问吗?用户最新问题:
如果我明天购买,有什么售后保障?(需要将“明天购买”转化为检索参数,关注售后政策)
4.7.2 代码实现 #
4.7.2.1 产品政策 #
4.7.2.1.2 input_context.py #
input_context.py
# 导入os模块用于文件路径处理
import os
# 从vectorstore.db模块导入保存文本到数据库的函数
from vectorstore.db import save_text_to_db
# 导入各类文件解析函数
from parser.pdf import extract_pdf_text
from parser.word import extract_text_from_word
from parser.excel import extract_text_from_excel
from parser.ppt import extract_ppt_text
from parser.htm import extract_text_from_html
from parser.xmls import extract_xml_text
from parser.csvs import read_csv_to_text
# 导入文本分块器
from splitter.text_splitter import RecursiveCharacterTextSplitter
# 导入logging模块用于日志记录
import logging
# 配置日志格式和级别
logging.basicConfig(
level=logging.INFO, format="%(asctime)s [%(levelname)s] %(message)s"
)
# 自动根据文件类型提取文本内容的函数
def extract_text_auto(file_path):
# 获取文件扩展名并转为小写
ext = os.path.splitext(file_path)[-1].lower()
# 根据不同文件类型调用相应的解析函数
if ext == ".pdf":
logging.info(f"检测到PDF文件,开始提取文本: {file_path}")
return extract_pdf_text(file_path)
elif ext in [".docx", ".doc"]:
logging.info(f"检测到Word文件,开始提取文本: {file_path}")
return extract_text_from_word(file_path)
elif ext in [".xlsx", ".xls"]:
logging.info(f"检测到Excel文件,开始提取文本: {file_path}")
return extract_text_from_excel(file_path)
elif ext in [".pptx", ".ppt"]:
logging.info(f"检测到PPT文件,开始提取文本: {file_path}")
return extract_ppt_text(file_path)
elif ext in [".html", ".htm"]:
logging.info(f"检测到HTML文件,开始提取文本: {file_path}")
return extract_text_from_html(file_path)
elif ext == ".xml":
logging.info(f"检测到XML文件,开始提取文本: {file_path}")
return extract_xml_text(file_path)
elif ext == ".csv":
logging.info(f"检测到CSV文件,开始提取文本: {file_path}")
return read_csv_to_text(file_path)
elif ext in [".md", ".txt", ".jsonl"]:
logging.info(f"检测到文本/Markdown/JSONL文件,开始读取: {file_path}")
with open(file_path, "r", encoding="utf-8") as f:
return f.read()
else:
# 不支持的文件类型,抛出异常
logging.error(f"不支持的文件类型: {ext}")
raise ValueError("不支持的文件类型: " + ext)
# 文档入库主流程函数
def doc_to_vectorstore(file_path, collection_name="rag_collection"):
# 1. 非结构化文本加载
logging.info(f"开始提取文件内容: {file_path}")
text = extract_text_auto(file_path)
logging.info(f"文件内容提取完成,长度为{len(text)}个字符")
# 2. 文本分块
logging.info("开始进行文本分块")
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=30)
chunks = splitter.split_text(text)
logging.info(f"文本分块完成,共分为{len(chunks)}块")
# 3. 嵌入并保存到向量数据库
for idx, chunk in enumerate(chunks):
logging.info(f"正在保存第{idx+1}/{len(chunks)}块到向量数据库")
save_text_to_db(chunk, collection_name=collection_name)
# 入库完成提示
print(f"文件 {file_path} 已完成入库,共分块 {len(chunks)} 个。")
logging.info(f"文件 {file_path} 已全部分块并入库完成")
+ print(
+ "【提示】建议知识库内容结构化、细化场景标签,便于后续多轮对话上下文归纳与Agentic RAG检索。"
+ )
# 示例用法
if __name__ == "__main__":
+ print("【多轮对话上下文知识库入库】")
+ file_path = "product_policy.txt"
doc_to_vectorstore(file_path)
4.7.2.1.3. output_context.py #
output_context.py
# 导入sentence_transformers库中的SentenceTransformer类
from sentence_transformers import SentenceTransformer
# 导入chromadb库
import chromadb
# 从本地llm.local模块导入ollama_qa函数
from llm.local import ollama_qa
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的Chroma客户端,数据将保存在本地的./chroma_db目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
+# 智能归纳多轮对话上下文,生成检索query列表(Agentic RAG核心)
+def summarize_queries_from_context(history, latest_question):
+ """
+ 输入:history为历史对话(字符串列表),latest_question为用户最新问题
+ 输出:归纳后的检索query列表
+ """
+ # 构建提示词,要求大模型根据全部上下文归纳检索意图
+ prompt = (
+ "请根据以下多轮对话内容,归纳出1到多条适合知识库检索的query,每条query单独输出。"
+ "\n历史对话:\n" + "\n".join(history) + f"\n用户最新问题:{latest_question}\n"
+ "请输出所有应检索的query,每行一条。"
+ )
+ queries_text = ollama_qa(prompt)
+ queries = [q.strip() for q in queries_text.split("\n") if q.strip()]
+ print(f"[日志] 智能归纳出{len(queries)}条检索query:{queries}")
+ return queries
+
+
# 定义函数:将query转为embedding向量
def get_query_embedding(query):
print("[日志] 正在将Query转为向量...")
return model.encode(query).tolist()
# 定义函数:向量检索,返回最相关的文本块列表
def retrieve_related_chunks(query_embedding, n_results=3):
print(f"[日志] 正在进行向量检索,返回最相关的{n_results}个文本块...")
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
related_chunks = results.get("documents")
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
print(f"[日志] 成功检索到{len(related_chunks[0])}个相关文本块。")
return related_chunks[0]
# 主程序入口
if __name__ == "__main__":
+ print("[多轮对话上下文智能问答系统] 启动")
+ history = [
+ "用户:我最近买了个智能手表。",
+ "AI:请问您购买的是哪个品牌或型号?",
+ "用户:是Alpha智能手表,去年买的。",
+ "AI:请问有什么可以帮您解答的问题吗?",
+ ]
+ latest_question = "保修期还有多久?"
+
+ # 1. 智能归纳多轮对话上下文,生成检索query列表
+ queries = summarize_queries_from_context(history, latest_question)
+ all_chunks = []
+ # 2. 针对每条归纳query分别检索
+ for q in queries:
+ query_embedding = get_query_embedding(q)
+ chunks = retrieve_related_chunks(query_embedding, n_results=3)
+ all_chunks.extend(chunks)
+ print("[日志] 所有相关文本块已检索完毕。")
+
+ # 3. 构建Prompt,将所有检索内容拼接为上下文
+ context = "\n".join(all_chunks)
+ final_prompt = (
+ f"已知信息:\n{context}\n\n请根据上述内容回答用户问题:{latest_question}"
+ )
+ print("prompt:", final_prompt)
print("[日志] Prompt构建完成,准备调用大模型生成答案。")
+ # 4. 调用大模型生成答案
+ answer = ollama_qa(final_prompt)
print("[日志] 答案生成完成。")
print("\n【答案】\n", answer)
+
+
+# 1. 上下文依赖型
+history_context_dependent = [
+ "用户:我最近买了个智能手表。",
+ "AI:请问您购买的是哪个品牌或型号?",
+ "用户:是Alpha智能手表,去年买的。",
+ "AI:请问有什么可以帮您解答的问题吗?",
+]
+latest_question_context_dependent = "保修期还有多久?"
+
+# 2. 对比型
+history_comparative = [
+ "用户:我在看Beta蓝牙耳机和Gamma智能音箱,想了解一下售后政策。",
+ "AI:Beta蓝牙耳机和Gamma智能音箱的售后政策您想了解哪些方面?",
+ "用户:主要是保修时间。",
+]
+latest_question_comparative = "哪个产品保修期更长?"
+
+# 3. 模糊指代型
+history_ambiguous_reference = [
+ "用户:我买了你们家的笔记本电脑和平板电脑。",
+ "AI:请问是Delta笔记本电脑和Epsilon平板电脑吗?",
+ "用户:对的。",
+ "AI:请问您想咨询哪方面的问题?",
+]
+latest_question_ambiguous_reference = "它们都支持无线充电吗?"
+
+# 4. 多意图型
+history_multi_intent = [
+ "用户:我想买Zeta无线充电器。",
+ "AI:请问您对Zeta无线充电器有哪些具体需求?",
+]
+latest_question_multi_intent = "有白色款吗?保修多久?坏了怎么售后?"
+
+# 5. 反问型
+history_rhetorical = [
+ "用户:我上次买的Epsilon平板电脑,售后流程很麻烦。",
+ "AI:很抱歉给您带来不便,请问这次您遇到什么问题了吗?",
+ "用户:这次是屏幕坏了,想申请售后。",
+]
+latest_question_rhetorical = "不会又要寄修等一个月吧?"
+
+# 6. 条件型
+history_conditional = [
+ "用户:我准备最近买一台Delta笔记本电脑。",
+ "AI:感谢您的关注,请问您还有其他疑问吗?",
+]
+latest_question_conditional = "如果我明天购买,有什么售后保障?"
4.8. 行业场景改写 #
实际上,不同行业和具体应用场景往往会衍生出许多独有的检索需求和query处理技巧。前面提到的六种query归纳方式只是通用范式,远不能涵盖所有实际情况。每个领域都可能有几十种甚至更多的特殊query改写策略,需要结合业务特点不断探索和总结。
以教育领域为例,题目检索是一个极具代表性的复杂场景。表面上看,不同题目的描述可能千差万别,但本质考查的知识点和解题逻辑却高度一致。例如,一道题描述工人挖桥洞,另一道题讲李白去买酒,虽然故事背景完全不同,但如果抽象出核心要素,会发现它们其实是同一类运动学问题。对于人类来说,这种“换汤不换药”的题目很容易识别,但对于基于文本相似度的检索系统来说,直接比对原文往往得分很低,难以实现有效匹配。
为了解决这类问题,教育行业常用的方法是“抽取题干”。也就是说,通过设计合适的提示词或算法,将题目中的人物、情境、故事等表层信息剥离,只保留关键的数学关系和求解目标。这样处理后,原本看似完全不同的两道题,其抽象后的表达就会高度相似,大大提升了检索的准确性和泛化能力。
而在其他行业,query的改写方式又会有很大不同。比如有的领域更注重业务流程,有的则需要理解专业术语或行业惯例。每个场景都需要结合实际需求,持续积累最佳实践,并通过大量实验不断优化query归纳与改写策略。只有这样,才能让RAG系统在各类复杂环境下都能发挥出最佳效果。
4.8.1 industry_qa #
4.8.2. output_stage.py #
output_stage.py
# 导入sentence_transformers库中的SentenceTransformer类
from sentence_transformers import SentenceTransformer
# 导入chromadb库
import chromadb
# 从本地llm.local模块导入ollama_qa函数
from llm.local import ollama_qa
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的Chroma客户端,数据将保存在本地的./chroma_db目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
+# 教育行业题干抽取函数
+def extract_abstract_stem(question):
+ """
+ 输入原始题目,输出抽象题干
+ """
+ prompt = (
+ "请将下面的数学或物理题目进行题干抽象,去除人物、动物、故事背景等情节,只保留核心数量关系和求解目标,输出标准题干:\n"
+ f"题目:{question}\n题干:"
+ )
+ abstract_stem = ollama_qa(prompt)
+ print(f"[日志] 抽取到的题干:{abstract_stem.strip()}")
+ return abstract_stem.strip()
+
+
# 定义函数:将query转为embedding向量
def get_query_embedding(query):
print("[日志] 正在将Query转为向量...")
return model.encode(query).tolist()
# 定义函数:向量检索,返回最相关的文本块列表
def retrieve_related_chunks(query_embedding, n_results=3):
print(f"[日志] 正在进行向量检索,返回最相关的{n_results}个文本块...")
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
related_chunks = results.get("documents")
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
print(f"[日志] 成功检索到{len(related_chunks[0])}个相关文本块。")
return related_chunks[0]
if __name__ == "__main__":
+ print("[行业差异化智能问答系统] 启动")
+ print(
+ "【提示】教育行业建议对题目进行题干抽象,去除故事背景,仅保留核心知识点和解题目标。其他行业可结合业务流程、专业术语等持续优化query归纳与改写策略。"
+ )
+ # query = input("请输入您的问题(可为抽象题干或行业特定表达):")
+ query = "王阿姨去市场买菜,从家到市场的距离是10公里。刚出发时,王阿姨骑电动车的速度是v千米/小时,骑到一半时电量不足,速度降为v-5千米/小时。已知她总共用了1小时到达市场,请问王阿姨出发时的速度v是多少千米/小时?"
print(f"[日志] 用户输入的问题为:{query}")
+ # 判断是否为教育题目(简单用关键词判断,可扩展为更复杂的分类)
+ is_education = any(
+ word in query for word in ["题目", "速度", "距离", "用时", "收集", "求", "解"]
+ )
+ if is_education:
+ print("[日志] 检测到教育行业题目,先进行题干抽取...")
+ query_for_retrieval = extract_abstract_stem(query)
+ else:
+ query_for_retrieval = query
+
+ query_embedding = get_query_embedding(query_for_retrieval)
print("[日志] Query向量化完成。")
related_chunks = retrieve_related_chunks(query_embedding, n_results=3)
print("[日志] 向量检索完成。")
context = "\n".join(related_chunks)
prompt = f"已知信息:\n{context}\n\n请根据上述内容回答用户问题:{query}"
print("prompt:", prompt)
print("[日志] Prompt构建完成,准备调用大模型生成答案。")
answer = ollama_qa(prompt)
print("[日志] 答案生成完成。")
print("\n【答案】\n", answer)
4.8.3. input_stage.py #
input_stage.py
# 导入os模块用于文件路径处理
import os
# 从vectorstore.db模块导入保存文本到数据库的函数
from vectorstore.db import save_text_to_db
# 导入各类文件解析函数
from parser.pdf import extract_pdf_text
from parser.word import extract_text_from_word
from parser.excel import extract_text_from_excel
from parser.ppt import extract_ppt_text
from parser.htm import extract_text_from_html
from parser.xmls import extract_xml_text
from parser.csvs import read_csv_to_text
# 导入文本分块器
from splitter.text_splitter import RecursiveCharacterTextSplitter
# 导入logging模块用于日志记录
import logging
# 配置日志格式和级别
logging.basicConfig(
level=logging.INFO, format="%(asctime)s [%(levelname)s] %(message)s"
)
# 自动根据文件类型提取文本内容的函数
def extract_text_auto(file_path):
# 获取文件扩展名并转为小写
ext = os.path.splitext(file_path)[-1].lower()
# 根据不同文件类型调用相应的解析函数
if ext == ".pdf":
logging.info(f"检测到PDF文件,开始提取文本: {file_path}")
return extract_pdf_text(file_path)
elif ext in [".docx", ".doc"]:
logging.info(f"检测到Word文件,开始提取文本: {file_path}")
return extract_text_from_word(file_path)
elif ext in [".xlsx", ".xls"]:
logging.info(f"检测到Excel文件,开始提取文本: {file_path}")
return extract_text_from_excel(file_path)
elif ext in [".pptx", ".ppt"]:
logging.info(f"检测到PPT文件,开始提取文本: {file_path}")
return extract_ppt_text(file_path)
elif ext in [".html", ".htm"]:
logging.info(f"检测到HTML文件,开始提取文本: {file_path}")
return extract_text_from_html(file_path)
elif ext == ".xml":
logging.info(f"检测到XML文件,开始提取文本: {file_path}")
return extract_xml_text(file_path)
elif ext == ".csv":
logging.info(f"检测到CSV文件,开始提取文本: {file_path}")
return read_csv_to_text(file_path)
elif ext in [".md", ".txt", ".jsonl"]:
logging.info(f"检测到文本/Markdown/JSONL文件,开始读取: {file_path}")
with open(file_path, "r", encoding="utf-8") as f:
return f.read()
else:
# 不支持的文件类型,抛出异常
logging.error(f"不支持的文件类型: {ext}")
raise ValueError("不支持的文件类型: " + ext)
# 文档入库主流程函数
def doc_to_vectorstore(file_path, collection_name="rag_collection"):
# 1. 非结构化文本加载
logging.info(f"开始提取文件内容: {file_path}")
text = extract_text_auto(file_path)
logging.info(f"文件内容提取完成,长度为{len(text)}个字符")
# 2. 文本分块
logging.info("开始进行文本分块")
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=30)
chunks = splitter.split_text(text)
logging.info(f"文本分块完成,共分为{len(chunks)}块")
# 3. 嵌入并保存到向量数据库
for idx, chunk in enumerate(chunks):
logging.info(f"正在保存第{idx+1}/{len(chunks)}块到向量数据库")
save_text_to_db(chunk, collection_name=collection_name)
# 入库完成提示
print(f"文件 {file_path} 已完成入库,共分块 {len(chunks)} 个。")
logging.info(f"文件 {file_path} 已全部分块并入库完成")
+ print(
+ "【提示】每个行业和场景都可能有独特的query归纳与改写需求。教育行业建议抽象题干,去除表层情节,仅保留核心知识点和解题目标。其他行业可结合业务流程、术语等持续积累最佳实践,不断优化知识库结构和检索策略。"
+ )
# 示例用法
if __name__ == "__main__":
+ print("【行业差异化知识库入库】")
# 提示用户输入文件路径
+ file_path = "industry_qa.txt"
# 执行文档入库流程
doc_to_vectorstore(file_path)
4.9. Text2SQL #
在实际的智能问答系统中,用户的查询往往不仅仅局限于知识库检索,还可能涉及结构化数据库的查询需求。近年来,text-to-SQL(自然语言转SQL)技术逐渐成为RAG系统中的重要一环。其核心思想是将用户的自然语言请求自动转化为SQL语句,从而直接在结构化数据库中检索所需信息。这种方式在许多行业场景下都非常常见,尤其是在需要精确筛选和多条件组合查询的业务中。
举个全新的例子,比如在招聘管理系统中,用户可能会提出如下需求:“请帮我查找所有三年以上Java开发经验、期望薪资低于2万元、并且愿意接受远程办公的候选人。”
这类问题如果直接用向量检索,往往难以获得准确结果,因为它涉及多个明确的结构化条件。此时,系统需要将用户的意图解析为对应的槽位(如岗位、经验年限、薪资上限、办公方式等),并动态生成SQL语句进行数据库查询。 在实际对话过程中,用户的需求往往是逐步补充和修正的。例如,用户一开始只要求“有三年以上Java经验的候选人”,随后又补充“期望薪资不超过2万”,再后来又加上“必须能远程办公”。每次补充条件时,系统都需要维护一套对话状态管理机制,动态更新槽位信息,并根据最新的槽位组合生成新的SQL查询。
更复杂的情况还包括条件冲突的处理。例如,用户先要求“期望薪资不超过2万”,后又说“有没有薪资高于3万的?”这时系统需要识别到前后条件的矛盾,并与用户确认其真实意图,是要替换条件还是进行多轮筛选。 因此,RAG系统在实际落地时,往往需要结合槽位填充、状态管理、冲突检测等机制,灵活应对用户的多轮、动态、结构化查询需求。只有这样,才能真正实现自然语言到结构化数据的无缝衔接,满足复杂业务场景下的智能检索与推荐。
4.9.1 结构化槽位 #
结构化槽位(Structured Slots)是对用户自然语言输入中关键信息的标准化抽取和归纳。
在对话系统、智能问答、text-to-SQL等场景中,结构化槽位通常指的是将用户的意图和条件,映射为一组有明确字段名和值的“键值对”,这些字段可以直接用于数据库查询、业务逻辑处理或下游任务。
举例说明:
假设用户输入:
“帮我找三年以上Java开发经验、期望薪资低于2万、能远程办公的候选人。”
经过槽位抽取后,得到的结构化槽位可能是:
{
"skill": "Java",
"experience": 3,
"salary": 20000,
"remote": "是"
}- skill:技能要求
- experience:工作年限
- salary:期望薪资上限
- remote:是否支持远程办公
这些槽位就是结构化的,因为它们有明确的字段名和值,可以直接拼接成SQL语句的WHERE条件,或用于其他结构化数据处理。
4.9.2 candidates.csv #
4.9.3. input_sql.py #
input_sql.py
# 导入os模块用于文件路径处理
import os
# 从vectorstore.db模块导入保存文本到数据库的函数
from vectorstore.db import save_text_to_db
# 导入各类文件解析函数
from parser.csvs import read_csv_to_text
from splitter.text_splitter import RecursiveCharacterTextSplitter
import logging
logging.basicConfig(
level=logging.INFO, format="%(asctime)s [%(levelname)s] %(message)s"
)
def extract_text_auto(file_path):
ext = os.path.splitext(file_path)[-1].lower()
+ if ext == ".csv":
logging.info(f"检测到CSV文件,开始提取文本: {file_path}")
return read_csv_to_text(file_path)
elif ext in [".md", ".txt", ".jsonl"]:
logging.info(f"检测到文本/Markdown/JSONL文件,开始读取: {file_path}")
with open(file_path, "r", encoding="utf-8") as f:
return f.read()
else:
logging.error(f"不支持的文件类型: {ext}")
raise ValueError("不支持的文件类型: " + ext)
def doc_to_vectorstore(file_path, collection_name="rag_collection"):
logging.info(f"开始提取文件内容: {file_path}")
text = extract_text_auto(file_path)
logging.info(f"文件内容提取完成,长度为{len(text)}个字符")
logging.info("开始进行文本分块")
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=30)
chunks = splitter.split_text(text)
logging.info(f"文本分块完成,共分为{len(chunks)}块")
for idx, chunk in enumerate(chunks):
logging.info(f"正在保存第{idx+1}/{len(chunks)}块到向量数据库")
save_text_to_db(chunk, collection_name=collection_name)
print(f"文件 {file_path} 已完成入库,共分块 {len(chunks)} 个。")
logging.info(f"文件 {file_path} 已全部分块并入库完成")
+ print(
+ "【提示】本知识库适用于text-to-SQL和结构化多条件筛选场景,建议配合招聘、金融等结构化数据表格使用。"
+ )
if __name__ == "__main__":
+ print("【结构化数据知识库入库】")
+ file_path = "candidates.csv"
doc_to_vectorstore(file_path)
4.9.4. output_sql.py #
output_sql.py
# 导入sentence_transformers库中的SentenceTransformer类
from sentence_transformers import SentenceTransformer
# 导入chromadb库
import chromadb
# 从本地llm.local模块导入ollama_qa函数
from llm.local import ollama_qa
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的Chroma客户端,数据将保存在本地的./chroma_db目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
+# 槽位状态管理(简化示例)
+class SlotState:
+ def __init__(self):
+ self.slots = {}
+
+ def update(self, key, value):
+ self.slots[key] = value
+
+ def remove(self, key):
+ if key in self.slots:
+ del self.slots[key]
+
+ def to_sql_where(self):
+ # 简单拼接SQL WHERE子句
+ conds = []
+ for k, v in self.slots.items():
+ if k == "experience":
+ conds.append(f"experience >= {v}")
+ elif k == "salary":
+ conds.append(f"salary <= {v}")
+ elif k == "remote":
+ conds.append(f"remote = '{v}'")
+ elif k == "skill":
+ conds.append(f"skill LIKE '%{v}%'")
+ return " AND ".join(conds)
+
+
+# 槽位解析(用大模型或规则)
+def parse_slots(user_input):
+ prompt = (
+ "请从下面的招聘筛选需求中抽取结构化槽位,输出JSON格式。\n"
+ "支持字段:skill, experience, salary, remote。\n"
+ f"用户输入:{user_input}\n槽位:"
+ )
+ import json
+
+ slots_json = ollama_qa(prompt)
+ print("slots_json:", slots_json)
+ try:
+ start = slots_json.index("{")
+ end = slots_json.rindex("}") + 1
+ slots_json = slots_json[start:end]
+ slots = json.loads(slots_json)
+ except Exception:
+ slots = {}
+ print(f"[日志] 槽位解析结果:{slots}")
+ return slots
+
+
# 定义函数:将query转为embedding向量
def get_query_embedding(query):
# 日志:打印正在进行query向量化
print("[日志] 正在将Query转为向量...")
# 使用模型对query进行编码,并转为list格式
return model.encode(query).tolist()
# 定义函数:向量检索,返回最相关的文本块列表
def retrieve_related_chunks(query_embedding, n_results=3):
# 日志:打印正在进行向量检索
print(f"[日志] 正在进行向量检索,返回最相关的{n_results}个文本块...")
# 在集合中进行向量检索,返回最相关的n_results个结果
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
# 获取检索到的文档内容
related_chunks = results.get("documents")
# 如果没有检索到相关内容,则提示并退出程序
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
# 日志:打印检索到的文本块数量
print(f"[日志] 成功检索到{len(related_chunks[0])}个相关文本块。")
# 返回最相关的文本块列表
return related_chunks[0]
# 主程序入口
if __name__ == "__main__":
+ print("[结构化招聘智能检索系统] 启动")
+ print(
+ "【提示】支持多轮补充条件,自动解析槽位并动态生成SQL。示例:'三年以上Java经验,薪资不超2万,远程办公'。"
+ )
+ state = SlotState()
+ while True:
+ user_input = input("请输入招聘筛选条件(回车结束):")
+ if not user_input.strip():
+ break
+ slots = parse_slots(user_input)
+ for k, v in slots.items():
+ state.update(k, v)
+ sql_where = state.to_sql_where()
+ print(f"[日志] 当前SQL筛选条件:{sql_where}")
+ # 这里可扩展为真实SQL查询,示例仅做展示
+ print("[日志] 最终筛选条件:", state.slots)
+ print("【说明】如需冲突检测、槽位替换等高级功能,可在此基础上扩展。")
4.10 混合检索 #
在信息检索领域,单一检索方法往往难以应对复杂多变的查询需求。混合检索技术通过结合文本匹配的稀疏检索和语义理解的密集检索,构建了一个更加鲁棒和全面的检索框架。这种融合策略不仅能够处理查询和文档的多样性,还能有效应对检索过程中的不确定性,显著提升检索模块的整体性能。
4.10.1 技术原理与优势 #
混合检索的核心思想在于取长补短,将两种不同检索方法的优势进行有机结合:
- 稀疏检索优势:专注于关键词的精确匹配,对特定术语和专有名词具有较高的识别精度
- 密集检索优势:基于语义相似度进行匹配,能够理解查询的深层含义和上下文关系
- 融合效果:通过协同工作,既保证了检索的精确性,又增强了语义理解的深度
4.10.2 技术架构与流程 #
混合检索的技术架构包含以下关键步骤:
- 双路并行检索:同时执行稀疏检索(BM25)和密集检索(Embedding)
- 结果融合排序:对两种方法返回的文档进行加权融合
- 最终文档选择:基于融合分数选择最优的上下文文档
4.10.3 核心算法 #
混合检索的核心在于融合分数的计算,采用加权导数排名算法:
算法公式:
融合分数 = 1 / (k + rank)其中:
rank:文档在检索结果中的排名位置k:经验常数(通常取60),用于控制分数范围
计算逻辑:
- 排名越靠前的文档,其导数越大,融合分数越高
- 体现了"相似度越高,权重越大"的设计理念
4.10.4 应用示例 #
假设我们有一个查询,通过两种检索方法分别得到以下结果:
稀疏检索结果(按相似度排序):
- 文档A(排名1):分数 = 1/(60+1) = 0.0164
- 文档B(排名2):分数 = 1/(60+2) = 0.0161
- 文档C(排名3):分数 = 1/(60+3) = 0.0159
密集检索结果(按相似度排序):
- 文档C(排名1):分数 = 1/(60+1) = 0.0164
- 文档B(排名2):分数 = 1/(60+2) = 0.0161
- 文档A(排名3):分数 = 1/(60+3) = 0.0159
融合计算(假设密集检索权重0.7,稀疏检索权重0.3):
- 文档A最终分数 = 0.0164×0.3 + 0.0159×0.7 = 0.0160
- 文档B最终分数 = 0.0161×0.3 + 0.0161×0.7 = 0.0161
- 文档C最终分数 = 0.0159×0.3 + 0.0164×0.7 = 0.0162
最终排序:文档C > 文档B > 文档A
4.10.5 技术特点与优势 #
- 鲁棒性强:通过多方法融合,降低单一方法的局限性
- 适应性好:可根据具体应用场景调整权重分配
- 精度提升:结合关键词匹配和语义理解,提高检索准确性
- 扩展性强:框架支持更多检索方法的集成
4.10.6 代码实现 #
4.10.6.1 top_indices #
import numpy as np
n_results = 2
# bm25_scores 这是一个NumPy数组,形状为 (N,),其中N是文档数量,每个元素表示对应文档的BM25相关性分数(值越大表示越相关)。
bm25_scores = np.array([2.1, 0.5, 3.3, 1.8])
# argsort() 返回的是数组值从小到大排序后的原始索引(不是值本身)。
# 对 [2.1, 0.5, 3.3, 1.8] 排序后得到值顺序 [0.5, 1.8, 2.1, 3.3],对应的原始索引是 [1, 3, 0, 2]
sorted_indices = np.argsort(bm25_scores)
print(sorted_indices)
# [start:stop:step] 当 step 设为 -1 时,表示从后向前按步长1遍历序列,因此会反转整个序列。
# 对排序后的索引进行逆序操作,将结果从升序变为降序(即分数从高到低)。
# 上一步的 [1, 3, 0, 2] 逆序后变为 [2, 0, 3, 1](对应分数 [3.3, 2.1, 1.8, 0.5])。
reverse_indices = sorted_indices[::-1]
print(reverse_indices)
# 对逆序后的索引进行切片操作,只保留前n_results个索引。
# 上一步的 [2, 0, 3, 1] 切片后变为 [2, 0](对应分数 [3.3, 2.1])。
top_indices = reverse_indices[:n_results]
# 打印最终结果,即分数最高的前n_results个文档的索引。
print(top_indices)
4.10.6.2 mixed_retrieval.py #
mixed_retrieval.py
# 导入sentence_transformers库中的SentenceTransformer类
from sentence_transformers import SentenceTransformer
# 导入chromadb库
import chromadb
# 导入numpy库,用于数值计算
import numpy as np
# 导入rank_bm25库,用于BM25稀疏检索
from rank_bm25 import BM25Okapi
# 导入jieba库,用于中文分词
import jieba
# 从本地llm.local模块导入ollama_qa函数
from llm.local import ollama_qa
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的Chroma客户端,数据将保存在本地的./chroma_db目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
# 定义函数:获取知识库中的所有文档用于BM25检索
def get_all_documents():
"""
获取知识库中的所有文档,用于构建BM25索引
"""
# 打印日志,提示正在获取文档
print("[日志] 正在获取知识库中的所有文档...")
# 获取集合中的所有文档
results = collection.get()
# 从结果中提取文档列表
documents = results.get("documents", [])
# 如果文档为空,提示并退出
if not documents:
print("知识库中没有文档,请先入库!")
exit(1)
# 打印日志,显示文档数量
print(f"[日志] 成功获取{len(documents)}个文档")
# 返回文档列表
return documents
# 定义函数:构建BM25索引
def build_bm25_index(documents):
"""
构建BM25稀疏检索索引
稀疏检索优势:专注于关键词的精确匹配,对特定术语和专有名词具有较高的识别精度
"""
# 打印日志,提示正在构建BM25索引
print("[日志] 正在构建BM25索引...")
# 建立倒排索引:将所有文档分词后,记录每个词出现在哪些文档、出现多少次。
# 高效检索:用户输入Query后,快速查找包含这些词的文档,并用BM25公式打分排序。
# 初始化分词后的文档列表
tokenized_docs = []
# 遍历每个文档
for doc in documents:
# 使用jieba进行中文分词
tokens = list(jieba.cut(doc))
# 添加分词结果到列表
tokenized_docs.append(tokens)
# 构建BM25索引对象
bm25 = BM25Okapi(tokenized_docs)
# 打印日志,提示BM25索引构建完成
print("[日志] BM25索引构建完成")
# 返回BM25索引对象和分词后的文档
return bm25, tokenized_docs
# 定义函数:BM25稀疏检索
def bm25_retrieval(query, bm25, documents, n_results=5):
"""
执行BM25稀疏检索
"""
# 打印日志,提示正在进行BM25检索
print("[日志] 正在进行BM25稀疏检索...")
# 对查询进行分词
query_tokens = list(jieba.cut(query))
# 计算BM25分数
bm25_scores = bm25.get_scores(query_tokens)
# 对BM25检索结果的分数进行排序,并选出分数最高的前n_results个文档的索引
# bm25_scores = np.array([2.1, 0.5, 3.3, 1.8])
# argsort() 返回的是数组值从小到大排序后的原始索引(不是值本身)。
# 使用[::-1]反转数组,使分数最高的排在前面
# 使用[:n_results]选择前n_results个索引
top_indices = np.argsort(bm25_scores)[::-1][:n_results]
# 初始化检索结果列表
bm25_results = []
# 遍历top索引
for i, idx in enumerate(top_indices):
# 只返回有相关性的文档
if (
bm25_scores[idx] > 0
and documents is not None
and idx < len(documents)
and documents[idx] is not None
):
# 添加检索结果到列表
bm25_results.append(
{"document": documents[idx], "score": bm25_scores[idx], "rank": i + 1}
)
# 打印日志,显示检索到的文档数量
print(f"[日志] BM25检索完成,获得{len(bm25_results)}个相关文档")
# 返回检索结果
return bm25_results
# 定义函数:密集检索(向量检索)
def dense_retrieval(query, n_results=5):
"""
执行密集检索(向量检索)
密集检索优势:基于语义相似度进行匹配,能够理解查询的深层含义和上下文关系
"""
# 打印日志,提示正在进行密集检索
print("[日志] 正在进行密集检索...")
# 将查询向量化
query_embedding = model.encode(query).tolist()
# 执行向量检索
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
# 获取检索到的文档和距离
documents = results.get("documents", [[]])
distances = results.get("distances", [[]])
# 如果没有检索到文档,提示并返回空列表
if not documents or not documents[0] or not distances or not distances[0]:
print("密集检索未找到相关文档!")
return []
# 取出文档和距离
documents = documents[0]
distances = distances[0]
# 初始化密集检索结果列表
dense_results = []
# 遍历文档和距离
for i, (doc, distance) in enumerate(zip(documents, distances)):
# 确保文档不为空
if doc is not None:
# 添加检索结果到列表,分数为距离的倒数
dense_results.append(
{
"document": doc,
# 向量距离(distance)转换为相似度分数(score),使得距离越小,相似度分数越高。这是一种常见的归一化方法
# 用于将距离度量(如欧氏距离[0, +∞)、余弦距离[0, 1])转化为更直观的相似度分数(值越大越相似)
# 分母加1防止距离为0时除零错误(distance=0 → score=1.0)
# 目的:将距离转换为统一的相似度分数,便于后续与BM25等稀疏检索分数融合(如加权平均)
"score": 1.0 / (1.0 + distance), # 将距离转换为相似度分数
"rank": i + 1,
}
)
# 打印日志,显示检索到的文档数量
print(f"[日志] 密集检索完成,获得{len(dense_results)}个相关文档")
# 返回密集检索结果
return dense_results
# 定义函数:计算加权导数排名分数
def calculate_weighted_reciprocal_rank(rank, k=60):
"""
计算加权导数排名分数
算法公式:融合分数 = 1 / (k + rank)
参数:
- rank: 文档在检索结果中的排名位置
- k: 经验常数(通常取60),用于控制分数范围
计算逻辑:排名越靠前的文档,其导数越大,融合分数越高
"""
# 返回加权导数排名分数
return 1.0 / (k + rank)
# 定义函数:融合检索结果
def fuse_retrieval_results(
bm25_results, dense_results, dense_weight=0.7, sparse_weight=0.3
):
"""
融合稀疏检索和密集检索的结果
融合效果:通过协同工作,既保证了检索的精确性,又增强了语义理解的深度
"""
# 打印日志,提示正在融合检索结果
print("[日志] 正在融合检索结果...")
# 创建文档到分数的映射字典
document_scores = {}
# 处理BM25稀疏检索结果
for result in bm25_results:
doc = result["document"]
rank = result["rank"]
# 计算稀疏检索分数并加权
score = calculate_weighted_reciprocal_rank(rank) * sparse_weight
# 累加分数
document_scores[doc] = document_scores.get(doc, 0) + score
# 处理密集检索结果
for result in dense_results:
doc = result["document"]
rank = result["rank"]
# 计算密集检索分数并加权
score = calculate_weighted_reciprocal_rank(rank) * dense_weight
# 累加分数
document_scores[doc] = document_scores.get(doc, 0) + score
# 按融合分数降序排序
sorted_documents = sorted(document_scores.items(), key=lambda x: x[1], reverse=True)
# 打印日志,显示融合文档数量
print(f"[日志] 融合完成,共融合{len(sorted_documents)}个文档")
# 返回排序后的文档列表
return [doc for doc, score in sorted_documents]
# 定义函数:混合检索主函数
def hybrid_retrieval(query, n_results=5, dense_weight=0.7, sparse_weight=0.3):
"""
执行混合检索
技术架构:双路并行检索 → 结果融合排序 → 最终文档选择
"""
# 打印日志,提示开始混合检索
print("[日志] 开始执行混合检索...")
# 获取所有文档并构建BM25索引
all_documents = get_all_documents()
bm25_index, tokenized_docs = build_bm25_index(all_documents)
# 执行双路并行检索
print("[日志] 执行双路并行检索...")
bm25_results = bm25_retrieval(query, bm25_index, all_documents, n_results)
dense_results = dense_retrieval(query, n_results)
# 融合检索结果并排序
fused_documents = fuse_retrieval_results(
bm25_results, dense_results, dense_weight, sparse_weight
)
# 选择前n个文档作为最终结果
final_documents = fused_documents[:n_results]
# 打印日志,显示最终选择的文档数量
print(f"[日志] 混合检索完成,最终选择{len(final_documents)}个文档")
# 返回最终文档列表
return final_documents
# 定义函数:生成最终答案
def generate_answer(query, retrieved_documents):
"""
基于检索到的文档生成最终答案
"""
# 打印日志,提示正在生成最终答案
print("[日志] 正在生成最终答案...")
# 构建上下文,将检索到的文档拼接为字符串
context = "\n".join(retrieved_documents)
# 构建提示词,包含检索信息和用户查询
prompt = f"""
基于以下通过混合检索技术获取的相关信息,请回答用户的查询。
检索到的相关信息:
{context}
用户查询:{query}
注意:系统使用了混合检索技术,结合了稀疏检索(关键词匹配)和密集检索(语义理解)的优势。
请提供一个准确、全面的回答,确保:
1. 直接回答用户的查询
2. 充分利用检索到的相关信息
3. 如果信息不足,请明确指出
4. 保持回答的准确性和相关性
回答:
"""
# 调用大语言模型生成答案
answer = ollama_qa(prompt)
# 打印日志,提示答案生成完成
print("[日志] 答案生成完成")
# 返回最终答案
return answer
# 主程序入口
if __name__ == "__main__":
# 打印日志,提示程序启动
print("[日志] 程序启动,准备接受用户输入。")
print("[日志] 使用混合检索技术:稀疏与密集检索的协同优化")
# 用户输入查询问题
query = input("请输入您的问题:")
# 打印日志,显示用户输入的问题
print(f"[日志] 用户输入的问题为:{query}")
# 执行混合检索,获取相关文档
retrieved_documents = hybrid_retrieval(
query, n_results=5, dense_weight=0.7, sparse_weight=0.3
)
# 打印日志,提示混合检索完成
print("[日志] 混合检索完成。")
# 生成最终答案
final_answer = generate_answer(query, retrieved_documents)
# 打印日志,提示答案生成完成
print("[日志] 答案生成完成。")
# 输出最终答案
print("\n【最终答案】\n", final_answer)
4.10.7 执行流程 #
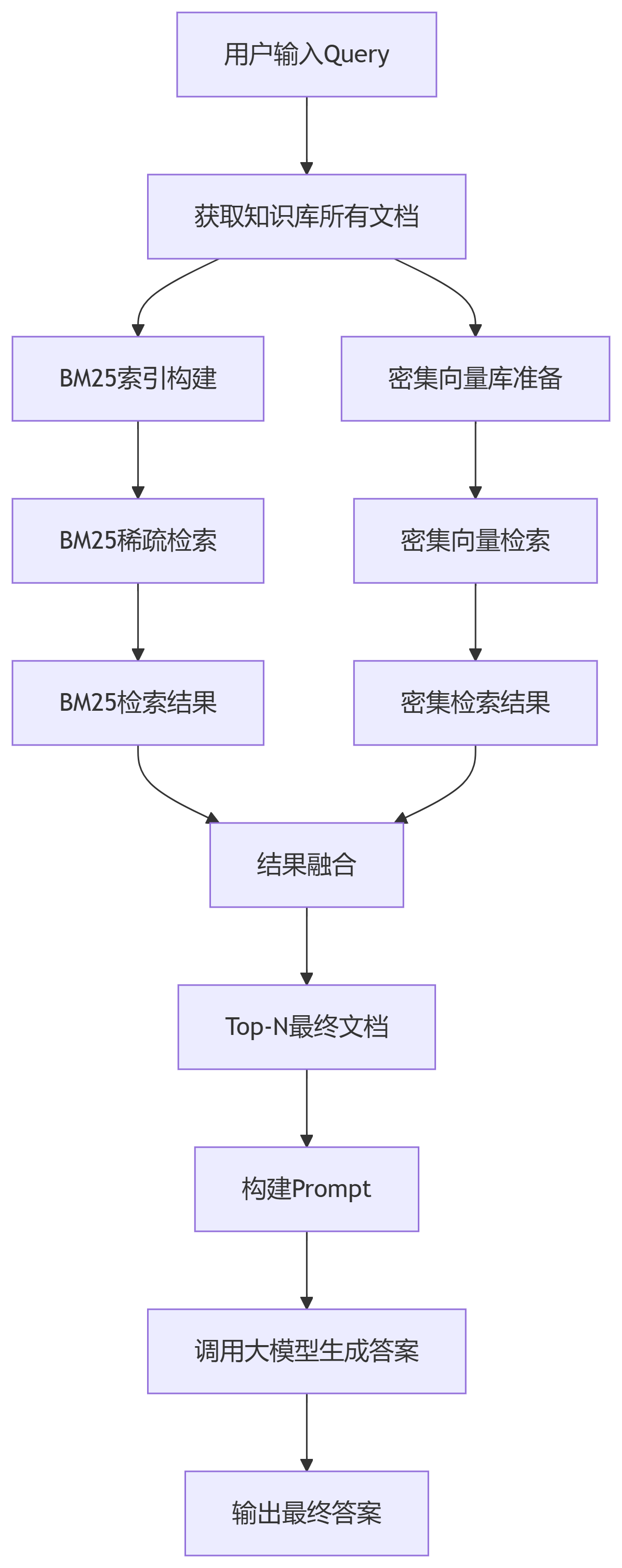
用户输入Query
用户输入自然语言问题。获取知识库所有文档
从Chroma向量数据库中获取所有已入库的文档。BM25索引构建
对所有文档进行分词,构建BM25稀疏检索索引(适合关键词精确匹配)。密集向量库准备
所有文档已在Chroma中有向量表示,准备进行向量检索。BM25稀疏检索
用BM25算法对Query进行关键词检索,获得相关文档及分数。密集向量检索
用句向量模型将Query向量化,在向量库中检索最相关的文档。BM25检索结果
得到BM25的Top-N文档及分数。密集检索结果
得到向量检索的Top-N文档及分数。结果融合
按设定权重(如稀疏0.3+密集0.7)将两路检索结果融合排序,兼顾关键词和语义。Top-N最终文档
选出融合分数最高的Top-N文档,作为最终上下文。构建Prompt
将Top-N文档拼接为上下文,和Query一起构建大模型输入Prompt。调用大模型生成答案
用本地或远程大模型(如ollama_qa)生成最终答案。输出最终答案
将答案返回给用户。
4.11 文档重排序 #
在RAG系统中,检索模块通常会返回大量基于相似度计算的候选文档。然而,这些文档的质量和相关性往往参差不齐,直接将其全部作为上下文信息输入大语言模型会带来诸多问题。因此,文档重排序技术应运而生,成为检索后增强的关键环节。
4.11.1 相似度与相关性的差异 #
传统检索方法主要依赖embedding模型的相似度计算,但这种方法存在固有局限性:
- 相似度陷阱:某些文档在向量空间中相似度很高,但实际内容与查询问题关联度较低
- 语义偏差:embedding模型可能将语义相近但主题不同的文档归为一类
- 噪声干扰:检索结果中往往包含大量不相关或低质量的内容
4.11.2 上下文长度控制 #
过多的检索文档会带来以下问题:
- 模型负担:大语言模型处理长文本时准确率下降
- 生成延迟:上下文长度增加导致推理速度变慢
- 信息污染:不相关内容可能干扰模型生成准确答案
4.11.3 Cross-Encoder架构 #
重排序采用交叉编码器(Cross-Encoder)架构:
技术特点:
- 联合编码:将查询和候选文档作为一对输入进行联合编码
- 相关性评分:直接输出查询-文档对的相关性分数
- 精确排序:基于相关性分数对文档进行精确排序
架构优势:
- 能够捕捉查询与文档之间的深层语义关系
- 提供更准确的相关性评估
- 支持细粒度的文档质量区分
4.11.4 重排序的技术流程 #
数据处理阶段
- 文档对构建:将用户查询与每个候选文档组成匹配对
- 文本预处理:对查询和文档进行标准化处理
- 长度控制:确保输入长度符合模型要求
模型推理阶段
- 分词处理:使用模型专用分词器进行token化
- 特征提取:通过Transformer编码器提取深层特征
- 相关性计算:输出查询-文档对的相关性分数
结果排序阶段
- 分数归一化:对相关性分数进行标准化处理
- 文档排序:按分数降序排列候选文档
- 质量筛选:选择分数最高的文档作为最终上下文
4.11.5 代码实现 #
rerank.py
# 导入sentence_transformers库中的SentenceTransformer类
+from sentence_transformers import SentenceTransformer, CrossEncoder
# 导入chromadb库
import chromadb
+# 导入numpy用于数值计算
+import numpy as np
+
# 从本地llm.local模块导入ollama_qa函数
from llm.local import ollama_qa
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
model = SentenceTransformer("all-MiniLM-L6-v2")
+# 加载重排序模型(使用BGE Reranker或类似的Cross-Encoder模型)
+# 注意:这里使用一个通用的Cross-Encoder模型,实际使用时可以替换为BGE Reranker
+rerank_model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
+
# 创建持久化的Chroma客户端,数据将保存在本地的./chroma_db目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
# 定义函数:将query转为embedding向量
def get_query_embedding(query):
# 日志:打印正在进行query向量化
print("[日志] 正在将Query转为向量...")
# 使用模型对query进行编码,并转为list格式
return model.encode(query).tolist()
# 定义函数:向量检索,返回最相关的文本块列表
+def retrieve_related_chunks(query_embedding, n_results=10):
# 日志:打印正在进行向量检索
print(f"[日志] 正在进行向量检索,返回最相关的{n_results}个文本块...")
# 在集合中进行向量检索,返回最相关的n_results个结果
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
# 获取检索到的文档内容
related_chunks = results.get("documents")
# 如果没有检索到相关内容,则提示并退出程序
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
# 日志:打印检索到的文本块数量
print(f"[日志] 成功检索到{len(related_chunks[0])}个相关文本块。")
# 返回最相关的文本块列表
return related_chunks[0]
+# 定义函数:构建查询-文档对
+def build_query_document_pairs(query, documents):
+ """
+ 构建查询和候选文档的匹配对
+ 数据处理阶段:文档对构建:将用户查询与每个候选文档组成匹配对
+ """
+ print("[日志] 正在构建查询-文档对...")
+
+ pairs = []
+ for doc in documents:
+ # 构建查询-文档对,格式为 [query, document]
+ pair = [query, doc]
+ pairs.append(pair)
+
+ print(f"[日志] 成功构建{len(pairs)}个查询-文档对")
+ return pairs
+
+
+# 定义函数:文本预处理
+def preprocess_text(text, max_length=512):
+ """
+ 对文本进行预处理
+ 数据处理阶段:文本预处理:对查询和文档进行标准化处理
+ """
+ # 去除多余的空白字符
+ text = " ".join(text.split())
+
+ # 限制文本长度
+ if len(text) > max_length:
+ text = text[:max_length] + "..."
+
+ return text
+
+
+# 定义函数:Cross-Encoder重排序
+def cross_encoder_rerank(query, documents, top_k=5):
+ """
+ 使用Cross-Encoder进行文档重排序
+ 重排序采用交叉编码器(Cross-Encoder)架构,与传统的双塔编码器(Bi-Encoder)不同
+
+ 技术特点:
+ - 联合编码:将查询和候选文档作为一对输入进行联合编码
+ - 相关性评分:直接输出查询-文档对的相关性分数
+ - 精确排序:基于相关性分数对文档进行精确排序
+ """
+ print("[日志] 开始Cross-Encoder重排序...")
+
+ # 1. 文本预处理
+ print("[日志] 正在进行文本预处理...")
+ processed_query = preprocess_text(query)
+ processed_docs = [preprocess_text(doc) for doc in documents]
+
+ # 2. 构建查询-文档对
+ query_doc_pairs = build_query_document_pairs(processed_query, processed_docs)
+
+ # 3. 模型推理阶段
+ print("[日志] 正在进行模型推理...")
+ print("[日志] 分词处理:使用模型专用分词器进行token化")
+ print("[日志] 特征提取:通过Transformer编码器提取深层特征")
+ print("[日志] 相关性计算:输出查询-文档对的相关性分数")
+
+ # 使用Cross-Encoder计算相关性分数
+ scores = rerank_model.predict(query_doc_pairs)
+
+ # 4. 结果排序阶段
+ print("[日志] 正在进行结果排序...")
+
+ # 将文档和分数组合,并转换tensor为float
+ doc_score_pairs = list(zip(documents, [float(score) for score in scores]))
+
+ # 按分数降序排序
+ sorted_docs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
+
+ # 选择top-k文档
+ top_docs = [doc for doc, score in sorted_docs[:top_k]]
+
+ print(f"[日志] 重排序完成,选择了{len(top_docs)}个最相关文档")
+
+ # 打印重排序结果
+ for i, (doc, score) in enumerate(sorted_docs[:top_k]):
+ print(f"[日志] 排名{i+1}: 分数={score:.4f}, 文档长度={len(doc)}字符")
+
+ return top_docs
+
+
+# 定义函数:传统检索与重排序对比
+def compare_retrieval_methods(query, query_embedding):
+ """
+ 对比传统检索和重排序的效果
+ 展示重排序技术如何解决相似度陷阱问题
+ """
+ print("[日志] 正在进行检索方法对比...")
+
+ # 1. 传统向量检索(返回更多候选文档)
+ print("[日志] 步骤1: 执行传统向量检索...")
+ candidate_docs = retrieve_related_chunks(query_embedding, n_results=10)
+
+ print(f"[日志] 传统检索获得{len(candidate_docs)}个候选文档")
+
+ # 2. Cross-Encoder重排序
+ print("[日志] 步骤2: 执行Cross-Encoder重排序...")
+ reranked_docs = cross_encoder_rerank(query, candidate_docs, top_k=5)
+
+ print(f"[日志] 重排序后选择{len(reranked_docs)}个最相关文档")
+
+ return reranked_docs
+
+
+# 定义函数:生成最终答案
+def generate_answer_with_reranked_context(query, reranked_documents):
+ """
+ 基于重排序后的文档生成最终答案
+ 重排序的技术优势:
+ - 相关性增强:筛选出与查询最相关的文档
+ - 噪声消除:过滤掉低质量和不相关内容
+ - 精度优化:提高大语言模型生成答案的准确性
+ """
+ print("[日志] 正在基于重排序结果生成答案...")
+
+ # 构建上下文
+ context = "\n".join(reranked_documents)
+
+ # 构建提示词
+ prompt = f"""
+基于以下通过文档重排序技术筛选出的最相关信息,请回答用户的查询。
+
+重排序后的相关信息:
+{context}
+
+用户查询:{query}
+
+注意:系统使用了Cross-Encoder重排序技术,能够更准确地评估查询与文档之间的相关性,有效避免相似度陷阱问题。
+
+请提供一个准确、全面的回答,确保:
+1. 直接回答用户的查询
+2. 充分利用重排序筛选出的相关信息
+3. 如果信息不足,请明确指出
+4. 保持回答的准确性和相关性
+
+回答:
+"""
+
+ # 调用大语言模型生成答案
+ answer = ollama_qa(prompt)
+
+ print("[日志] 答案生成完成")
+ return answer
+
+
# 主程序入口
if __name__ == "__main__":
# 日志:程序启动
print("[日志] 程序启动,准备接受用户输入。")
+ print("[日志] 使用文档重排序技术:检索后增强的核心策略")
+
# 1. 用户输入Query
query = input("请输入您的问题:")
# 日志:打印用户输入的Query
print(f"[日志] 用户输入的问题为:{query}")
# 2. Query向量化
query_embedding = get_query_embedding(query)
# 日志:打印Query向量化完成
print("[日志] Query向量化完成。")
+ # 3. 传统检索与重排序对比
+ reranked_documents = compare_retrieval_methods(query, query_embedding)
+ # 日志:打印重排序完成
+ print("[日志] 重排序完成。")
+ # 4. 基于重排序结果生成答案
+ final_answer = generate_answer_with_reranked_context(query, reranked_documents)
# 日志:打印答案生成完成
print("[日志] 答案生成完成。")
+ # 5. 输出最终答案
+ print("\n【最终答案】\n", final_answer)
4.11.6 执行流程 #
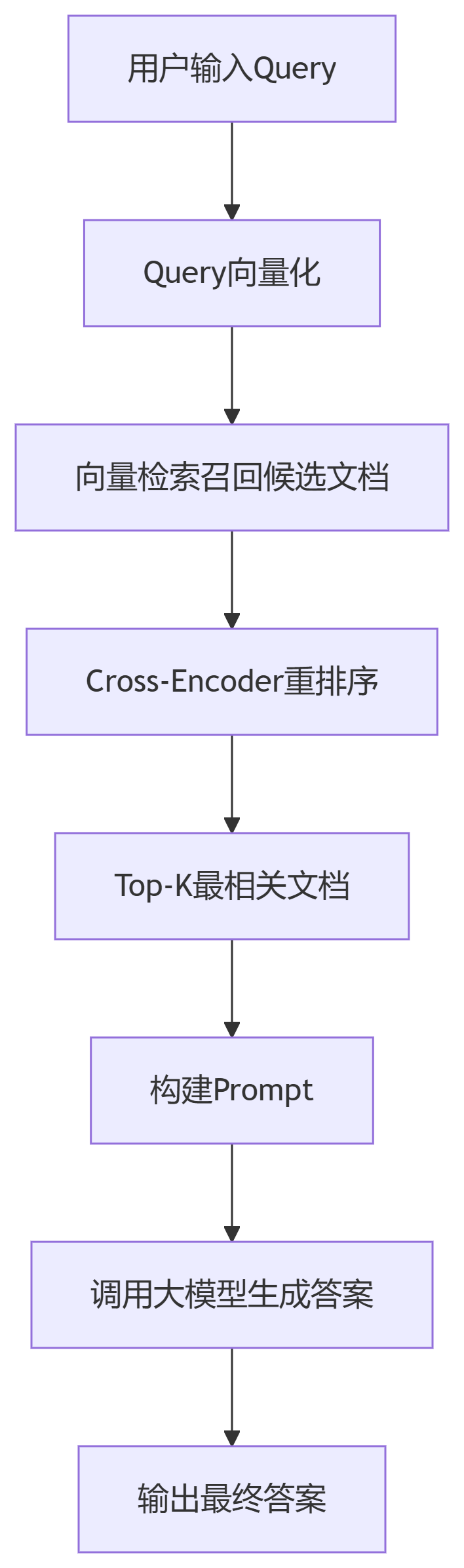
用户输入Query
用户输入自然语言问题。获取知识库所有文档
从Chroma向量数据库中获取所有已入库的文档。BM25索引构建
对所有文档进行分词,构建BM25稀疏检索索引(适合关键词精确匹配)。密集向量库准备
所有文档已在Chroma中有向量表示,准备进行向量检索。BM25稀疏检索
用BM25算法对Query进行关键词检索,获得相关文档及分数。密集向量检索
用句向量模型将Query向量化,在向量库中检索最相关的文档。BM25检索结果
得到BM25的Top-N文档及分数。密集检索结果
得到向量检索的Top-N文档及分数。结果融合
按设定权重(如稀疏0.3+密集0.7)将两路检索结果融合排序,兼顾关键词和语义。Top-N最终文档
选出融合分数最高的Top-N文档,作为最终上下文。构建Prompt
将Top-N文档拼接为上下文,和Query一起构建大模型输入Prompt。调用大模型生成答案
用本地或远程大模型(如ollama_qa)生成最终答案。输出最终答案
将答案返回给用户。
5. 知识库索引优化策略 #
现在让我们转向知识库索引的优化视角。多维度检索技术通过为同一文档构建多种类型的向量表示,从而显著提升检索效果。
5.1 为什么需要多维度检索? #
用户提出的问题往往涉及不同层面的信息需求——可能是具体的事实查询、抽象概念的理解,或是简单的关键词匹配。而传统知识库往往缺乏这种层次化的区分。因此,我们通过对同一文档进行多角度的向量化处理,能够更好地匹配各种类型的问题,从而提升检索精度。
多维度检索属于检索前的预处理优化,接下来我们详细介绍三种核心方法。
5.1.1 方法一:层次化文档索引 #
这种方法基于文档粒度的层次化处理。具体流程如下:
假设我们有一个300字符的大文档块,首先将其分解为三个100字符的小块。然后对每个小块进行向量化处理,得到不同的embedding向量。这些向量虽然对应相同的原始文档,但各自承载了不同片段的语义信息。
检索时,系统使用小块的embedding进行相似度计算,但返回的是对应的大文档块内容。这种设计的优势在于:开源embedding模型对短文本的语义提取效果更佳,更容易与用户问题产生匹配。
5.1.2 法二:摘要化索引 #
这种方法通过生成文档摘要来建立索引。具体步骤:
对于300字符的大文档块,利用大语言模型生成其摘要内容,然后对摘要进行向量化。检索时,系统使用摘要的embedding进行匹配,但返回原始的大文档块内容。
这种方法的核心理念是:用户有时需要的是概括性的经验或抽象信息,而非详细的具体内容。通过摘要索引,能够更好地匹配这类信息需求。
5.1.3 方法三:问题化索引 #
这种方法通过生成假设性问题来建立索引。具体实现:
对于给定的文档块,利用大语言模型生成若干个假设性问题,确保这些问题的答案都能在原文中找到。然后对这些假设性问题进行向量化处理。
检索时,系统使用假设性问题的embedding与用户问题进行匹配,返回对应的原始文档内容。这种方法的优势在于:问题与问题之间的语义匹配更加直接和准确。
值得注意的是,这种问题化思路在评估指标中也有应用,特别是在计算答案相关性时,通过生成假设性问题来评估生成答案的匹配程度。
5.2 技术优势 #
这三种多维度检索方法都遵循相同的核心原则:检索时使用转换后的索引进行匹配,但返回原始的完整文档内容。这种方法能够:
- 提升泛化能力:适应不同类型和角度的问题
- 增强语义匹配:找到更相关的上下文信息
- 改善答案质量:为大语言模型提供更精准的输入
5.3 代码实现 #
5.3.1. db.py #
vectorstore/db.py
# 导入 chromadb 库
import chromadb
# 导入 sentence_transformers 库中的 SentenceTransformer 类
from sentence_transformers import SentenceTransformer
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
# 首次调用时会触发下载和安装过程保存到缓存目录(默认 ~/.cache/sentence_transformers)
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的 Chroma 客户端,数据将保存在本地的 ./chroma_db 目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 定义将文本保存到 ChromaDB 的函数
+def save_text_to_db(text, collection_name="rag_collection", metadata=None):
"""
将文本保存到ChromaDB指定集合中,使用sentence_transformers生成embedding。
:param text: 要保存的文本
:param collection_name: 集合名称,默认rag_collection
+ :param metadata: 元数据字典,用于存储额外信息
"""
# 获取指定名称的集合,如果不存在则创建
collection = client.get_or_create_collection(collection_name)
# 使用文本内容的哈希值作为唯一id
text_id = str(abs(hash(text)))
# 生成文本的向量表示(embedding),并转换为列表格式
embedding = model.encode([text])[0].tolist()
+
+ # 设置默认元数据
+ if metadata is None:
+ metadata = {"source": "user_input"}
+ else:
+ # 确保包含source字段
+ if "source" not in metadata:
+ metadata["source"] = "user_input"
+
# 向集合中添加文本、元数据、id和embedding
collection.add(
documents=[text],
+ metadatas=[metadata],
ids=[text_id],
embeddings=[embedding],
)
# 打印保存成功的信息及文本id
print(f"文本已保存到ChromaDB,id={text_id}")
# 返回文本id
return text_id
# 主程序入口示例
if __name__ == "__main__":
# 调用函数,将测试文本保存到数据库
tid = save_text_to_db("这是一个测试文本")
5.3.2 index_ouput.py #
index_ouput.py
# 导入句子嵌入模型
from sentence_transformers import SentenceTransformer
# 导入向量数据库
import chromadb
# 导入大语言模型接口
from llm.local import ollama_qa
# 加载句子嵌入模型
model = SentenceTransformer("all-MiniLM-L6-v2")
print("句子嵌入模型加载完成")
# 创建持久化Chroma客户端
client = chromadb.PersistentClient(path="./chroma_db")
print("Chroma数据库客户端创建完成")
# 获取或创建向量集合
collection = client.get_or_create_collection("rag_collection")
print("向量集合初始化完成")
+# 将查询文本转换为向量表示
def get_query_embedding(query):
+ print(f"正在将查询转换为向量: {query[:30]}...")
+ # 使用模型编码查询文本并转换为列表格式
+ embedding = model.encode(query).tolist()
+ print("查询向量化完成")
+ return embedding
+
+
+# 多维度向量检索函数
+def retrieve_related_chunks_multidimensional(query_embedding, n_results=3):
+ print(f"开始多维度向量检索,返回前 {n_results} 个结果")
+ # 在向量数据库中查询最相关的文档
+ results = collection.query(
+ query_embeddings=[query_embedding],
+ n_results=n_results,
+ include=["documents", "metadatas", "distances"],
+ )
+
+ # 提取查询结果中的文档、元数据和距离信息
+ documents = results.get("documents", [[]])
+ metadatas = results.get("metadatas", [[]])
+ distances = results.get("distances", [[]])
+
+ # 检查是否检索到结果
+ if not documents or not documents[0]:
+ print("未检索到相关内容,请先入库或检查数据库!")
+ exit(1)
+ # 获取第一组结果
+ documents = documents[0]
+ metadatas = metadatas[0] if metadatas else []
+ distances = distances[0] if distances else []
+
+ print(f"检索到 {len(documents)} 个相关文档")
+
+ # 处理多维度索引结果,提取原始文档块
+ original_chunks = []
+ for i, (doc, metadata) in enumerate(zip(documents, metadatas)):
+ print(f"处理第 {i+1} 个检索结果...")
+ # 如果是多维度索引,提取原始文档块
+ if metadata and "original_chunk" in metadata:
+ original_chunk = metadata["original_chunk"]
+ if isinstance(original_chunk, str):
+ print(f"提取原始文档块,长度: {len(original_chunk)} 字符")
+ original_chunks.append(original_chunk)
+ else:
+ print("原始文档块格式异常,使用检索到的文档")
+ original_chunks.append(doc)
+ else:
+ # 传统索引,直接使用检索到的文档
+ print("使用传统索引文档")
+ original_chunks.append(doc)
+
+ # 去重处理,避免返回重复的原始文档块
+ print("开始去重处理...")
+ unique_chunks = []
+ seen_chunks = set()
+ for chunk in original_chunks:
+ # 使用内容哈希值进行去重
+ chunk_hash = hash(chunk)
+ if chunk_hash not in seen_chunks:
+ unique_chunks.append(chunk)
+ seen_chunks.add(chunk_hash)
+
+ print(f"去重后剩余 {len(unique_chunks)} 个唯一文档块")
+ return unique_chunks
+
+
+# 传统向量检索函数(兼容原有接口)
def retrieve_related_chunks(query_embedding, n_results=3):
+ print(f"开始传统向量检索,返回前 {n_results} 个结果")
+ # 在向量数据库中查询最相关的文档
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
# 获取检索到的文档内容
related_chunks = results.get("documents")
+ # 检查是否检索到结果
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
+ print(f"传统检索完成,返回 {len(related_chunks[0])} 个文档块")
# 返回最相关的文本块列表
return related_chunks[0]
+# 程序入口
if __name__ == "__main__":
+ print("=" * 50)
+ print("多维度检索查询程序")
+ print("=" * 50)
+ # 获取用户输入的查询
+ query = input("请输入您的问题:")
+ print(f"用户查询: {query}")
+ # 将查询转换为向量表示
query_embedding = get_query_embedding(query)
+ # 执行多维度向量检索
+ print("开始执行多维度检索...")
+ related_chunks = retrieve_related_chunks_multidimensional(
+ query_embedding, n_results=3
+ )
+ # 构建上下文信息
+ print("构建上下文信息...")
context = "\n".join(related_chunks)
+ print(f"上下文长度: {len(context)} 字符")
+
+ # 构建提示词
prompt = f"已知信息:\n{context}\n\n请根据上述内容回答用户问题:{query}"
+ print("提示词构建完成")
+ # 调用大语言模型生成答案
+ print("正在生成答案...")
answer = ollama_qa(prompt)
+ # 输出最终答案
+ print("\n" + "=" * 50)
+ print("【答案】")
+ print("=" * 50)
+ print(answer)
5.3.3 index_input.py #
index_input.py
# 导入操作系统模块,用于文件路径处理
import os
# 导入向量数据库保存函数
from vectorstore.db import save_text_to_db
# 导入PDF文件解析函数
from parser.pdf import extract_pdf_text
# 导入Word文档解析函数
from parser.word import extract_text_from_word
# 导入Excel文件解析函数
from parser.excel import extract_text_from_excel
# 导入PPT文件解析函数
from parser.ppt import extract_ppt_text
# 导入HTML文件解析函数
from parser.htm import extract_text_from_html
# 导入XML文件解析函数
from parser.xmls import extract_xml_text
# 导入CSV文件解析函数
from parser.csvs import read_csv_to_text
# 导入文本分块器
from splitter.text_splitter import RecursiveCharacterTextSplitter
# 导入大语言模型接口
from llm.local import ollama_qa
# 根据文件类型自动提取文本内容的函数
def extract_text_auto(file_path):
# 获取文件扩展名并转换为小写
ext = os.path.splitext(file_path)[-1].lower()
print(f"检测到文件类型: {ext}")
# 根据文件扩展名调用相应的解析函数
if ext == ".pdf":
print("正在解析PDF文件...")
return extract_pdf_text(file_path)
elif ext in [".docx", ".doc"]:
print("正在解析Word文档...")
return extract_text_from_word(file_path)
elif ext in [".xlsx", ".xls"]:
print("正在解析Excel文件...")
return extract_text_from_excel(file_path)
elif ext in [".pptx", ".ppt"]:
print("正在解析PPT文件...")
return extract_ppt_text(file_path)
elif ext in [".html", ".htm"]:
print("正在解析HTML文件...")
return extract_text_from_html(file_path)
elif ext == ".xml":
print("正在解析XML文件...")
return extract_xml_text(file_path)
elif ext == ".csv":
print("正在解析CSV文件...")
return read_csv_to_text(file_path)
elif ext in [".md", ".txt", ".jsonl"]:
print("正在读取文本文件...")
with open(file_path, "r", encoding="utf-8") as f:
return f.read()
else:
raise ValueError("不支持的文件类型: " + ext)
+# 创建层次化文档索引的函数
+def create_hierarchical_index(chunk, collection_name="rag_collection"):
+ print("开始创建层次化索引...")
+ # 创建小文档块分块器,块大小100字符,重叠10字符
+ small_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=10)
+ # 将大文档块分解为小文档块
+ small_chunks = small_splitter.split_text(chunk)
+ print(f"将大文档块分解为 {len(small_chunks)} 个小文档块")
+
+ # 为每个小文档块创建索引
+ for i, small_chunk in enumerate(small_chunks, 1):
+ print(f"正在保存第 {i}/{len(small_chunks)} 个层次化索引...")
+ save_text_to_db(
+ small_chunk,
+ collection_name=collection_name,
+ metadata={"original_chunk": chunk, "index_type": "hierarchical"},
+ )
+
+
+# 创建摘要化索引的函数
+def create_summary_index(chunk, collection_name="rag_collection"):
+ print("开始创建摘要化索引...")
+ # 构建摘要生成提示词
+ summary_prompt = f"请为以下文档生成一个简洁的摘要(不超过100字):\n\n{chunk}"
+ try:
+ # 使用大语言模型生成摘要
+ print("正在生成文档摘要...")
+ summary = ollama_qa(summary_prompt)
+ print(f"摘要生成完成: {summary[:50]}...")
+ # 保存摘要到向量数据库
+ save_text_to_db(
+ summary,
+ collection_name=collection_name,
+ metadata={"original_chunk": chunk, "index_type": "summary"},
+ )
+ except Exception as e:
+ print(f"摘要生成失败: {e}")
+
+
+# 创建问题化索引的函数
+def create_question_index(chunk, collection_name="rag_collection"):
+ print("开始创建问题化索引...")
+ # 构建问题生成提示词
+ question_prompt = f"请为以下文档生成3个假设性问题,确保这些问题的答案都能在文档中找到:\n\n{chunk}"
+ try:
+ # 使用大语言模型生成假设性问题
+ print("正在生成假设性问题...")
+ questions_response = ollama_qa(question_prompt)
+ # 处理返回的问题,提取包含问号的问题
+ questions = [
+ q.strip() for q in questions_response.split("\n") if q.strip() and "?" in q
+ ]
+ print(f"生成了 {len(questions)} 个假设性问题")
+
+ # 为每个假设性问题创建索引(最多3个)
+ for i, question in enumerate(questions[:3], 1):
+ print(f"正在保存第 {i} 个问题化索引: {question[:30]}...")
+ save_text_to_db(
+ question,
+ collection_name=collection_name,
+ metadata={"original_chunk": chunk, "index_type": "question"},
+ )
+ except Exception as e:
+ print(f"问题生成失败: {e}")
+
+
+# 多维度文档入库主函数
+def doc_to_multidimensional_vectorstore(file_path, collection_name="rag_collection"):
+ print(f"开始处理文件: {file_path}")
+ # 提取文件文本内容
+ text = extract_text_auto(file_path)
+ print(f"文件内容提取完成,总长度: {len(text)} 字符")
+
+ # 创建大文档块分块器,块大小300字符,重叠50字符
+ splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)
+ # 将文本分割为大文档块
+ chunks = splitter.split_text(text)
+ print(f"文本分割完成,共 {len(chunks)} 个大文档块")
+
+ # 对每个大文档块进行多维度索引处理
+ for i, chunk in enumerate(chunks, 1):
+ print(f"\n正在处理第 {i}/{len(chunks)} 个大文档块...")
+ # 创建层次化索引
+ create_hierarchical_index(chunk, collection_name)
+ # 创建摘要化索引
+ create_summary_index(chunk, collection_name)
+ # 创建问题化索引
+ create_question_index(chunk, collection_name)
+
+ print(f"文件 {file_path} 多维度索引入库完成!")
+
+
+# 传统单维度文档入库函数(兼容原有接口)
def doc_to_vectorstore(file_path, collection_name="rag_collection"):
+ print(f"开始传统单维度索引入库: {file_path}")
+ # 提取文件文本内容
text = extract_text_auto(file_path)
+ # 创建文档块分块器,块大小200字符,重叠30字符
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=30)
+ # 将文本分割为文档块
chunks = splitter.split_text(text)
+ print(f"文本分割完成,共 {len(chunks)} 个文档块")
+
+ # 为每个文档块创建索引
+ for i, chunk in enumerate(chunks, 1):
+ print(f"正在保存第 {i}/{len(chunks)} 个文档块...")
save_text_to_db(chunk, collection_name=collection_name)
+
+ print(f"文件 {file_path} 传统索引入库完成!")
+# 程序入口
if __name__ == "__main__":
+ # 设置要处理的文件路径
+ file_path = "example/example.txt"
+ print("=" * 50)
+ print("多维度检索索引入库程序")
+ print("=" * 50)
+ # 执行多维度文档入库流程
+ doc_to_multidimensional_vectorstore(file_path)
6. 迭代式检索增强生成技术 #
迭代式检索增强生成(Iterative RAG)是一种全新的系统性优化方法,其核心思想是通过多次完整的RAG流程迭代来逐步提升答案质量。
6.1 迭代式增强的基本原理 #
与传统的单次RAG流程不同,迭代式增强采用多次迭代的方式,每次迭代都是一次完整的检索-增强-生成过程。这种方法的理论基础在于:每次迭代生成的答案中往往包含有助于后续检索的补充信息,这些信息虽然可能不够准确,但能够引导系统检索到更相关的上下文内容。
迭代式增强既不属于检索前增强,也不属于检索后增强,而是一种系统性的、模块化的增强策略。它将整个RAG流程视为一个可重复使用的模块,通过多个模块的串联迭代来实现性能提升。
6.2 迭代式增强的具体流程 #
让我们以两次迭代为例来说明这个过程:
第一次迭代:
- 接收用户原始问题
- 在知识库中进行检索,获得初始上下文信息
- 大语言模型基于问题和上下文生成初步答案
第二次迭代:
- 将第一次迭代的答案与原始问题合并,形成新的查询
- 使用新查询在知识库中重新检索,获得更精确的上下文信息
- 大语言模型基于原始问题和新上下文生成最终答案
如果需要进行更多次迭代,后续迭代的策略与第二次迭代相同。
6.3 迭代式增强的核心优势 #
- 信息累积效应:每次迭代都能从之前的答案中提取有价值的信息
- 检索精度提升:补充信息有助于检索到更相关的文档
- 答案质量改善:基于更准确的上下文生成更可靠的答案
- 错误修正能力:后续迭代能够纠正前面迭代中的不准确信息
6.4 技术实现要点 #
迭代式增强的关键在于如何有效利用前一次迭代的答案信息。虽然这些信息可能不够准确,但它们为后续检索提供了重要的线索和方向,使得系统能够在知识库中找到更相关的文档片段。
这种方法的本质是通过多次迭代来逐步完善和修正答案,每次迭代都基于前一次的结果进行优化,最终生成更加准确和完整的回答。
通过这种系统性的迭代策略,RAG系统能够显著提升复杂问题的处理能力,特别是在需要多步骤推理或信息整合的场景中表现出色。
6.5 代码实现 #
IterativeRAG.py
# 导入sentence_transformers库中的SentenceTransformer类
from sentence_transformers import SentenceTransformer
# 导入chromadb库
import chromadb
# 从本地llm.local模块导入ollama_qa函数
from llm.local import ollama_qa
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的Chroma客户端,数据将保存在本地的./chroma_db目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
# 定义函数:将query转为embedding向量
def get_query_embedding(query):
# 日志:打印正在进行query向量化
print("[日志] 正在将Query转为向量...")
# 使用模型对query进行编码,并转为list格式
return model.encode(query).tolist()
# 定义函数:向量检索,返回最相关的文本块列表
def retrieve_related_chunks(query_embedding, n_results=3):
# 日志:打印正在进行向量检索
print(f"[日志] 正在进行向量检索,返回最相关的{n_results}个文本块...")
# 在集合中进行向量检索,返回最相关的n_results个结果
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
# 获取检索到的文档内容
related_chunks = results.get("documents")
# 如果没有检索到相关内容,则提示并退出程序
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
# 日志:打印检索到的文本块数量
print(f"[日志] 成功检索到{len(related_chunks[0])}个相关文本块。")
# 返回最相关的文本块列表
return related_chunks[0]
+# 定义函数:单次RAG迭代过程
+def single_rag_iteration(query, iteration_num=1):
+ """执行单次RAG迭代过程"""
+ print(f"\n{'='*50}")
+ print(f"开始第 {iteration_num} 次迭代")
+ print(f"{'='*50}")
+
+ # 1. Query向量化
+ print(f"[第{iteration_num}次迭代] 正在将查询转换为向量...")
query_embedding = get_query_embedding(query)
+ # 2. 向量检索
+ print(f"[第{iteration_num}次迭代] 正在执行向量检索...")
related_chunks = retrieve_related_chunks(query_embedding, n_results=3)
+ # 3. 构建Prompt
context = "\n".join(related_chunks)
prompt = f"已知信息:\n{context}\n\n请根据上述内容回答用户问题:{query}"
+ print(f"[第{iteration_num}次迭代] Prompt构建完成,上下文长度:{len(context)}字符")
+ # 4. 调用大语言模型生成答案
+ print(f"[第{iteration_num}次迭代] 正在生成答案...")
answer = ollama_qa(prompt)
+ print(f"[第{iteration_num}次迭代] 答案生成完成")
+ print(f"[第{iteration_num}次迭代] 生成答案:{answer[:100]}...")
+
+ return answer, related_chunks
+
+
+# 定义函数:构建迭代查询
+def build_iterative_query(original_query, previous_answer):
+ """将原始查询与上一次迭代的答案合并,构建新的查询"""
+ print("正在构建迭代查询...")
+ # 合并原始查询和上一次的答案
+ iterative_query = f"{original_query}\n\n基于上一次的回答:{previous_answer}"
+ print(f"迭代查询构建完成,长度:{len(iterative_query)}字符")
+ return iterative_query
+
+
+# 定义函数:迭代式检索增强生成
+def iterative_rag_generation(original_query, max_iterations=2):
+ """执行迭代式检索增强生成"""
+ print("=" * 60)
+ print("迭代式检索增强生成系统")
+ print("=" * 60)
+ print(f"原始查询:{original_query}")
+ print(f"最大迭代次数:{max_iterations}")
+
+ # 存储每次迭代的结果
+ iteration_results = []
+ current_query = original_query
+
+ # 执行多次迭代
+ for iteration in range(1, max_iterations + 1):
+ print(f"\n开始第 {iteration}/{max_iterations} 次迭代...")
+
+ # 执行单次RAG迭代
+ answer, context_chunks = single_rag_iteration(current_query, iteration)
+
+ # 保存迭代结果
+ iteration_results.append(
+ {
+ "iteration": iteration,
+ "query": current_query,
+ "answer": answer,
+ "context_chunks": context_chunks,
+ }
+ )
+
+ # 如果不是最后一次迭代,构建下一次的查询
+ if iteration < max_iterations:
+ current_query = build_iterative_query(original_query, answer)
+
+ print(f"第 {iteration} 次迭代完成")
+
+ # 输出最终结果
+ print("\n" + "=" * 60)
+ print("迭代式RAG生成完成")
+ print("=" * 60)
+
+ # 显示每次迭代的摘要
+ for result in iteration_results:
+ print(f"\n第 {result['iteration']} 次迭代结果:")
+ print(f"查询:{result['query'][:100]}...")
+ print(f"答案:{result['answer'][:200]}...")
+
+ # 返回最终答案和所有迭代结果
+ final_answer = iteration_results[-1]["answer"]
+ print(f"\n最终答案:{final_answer}")
+
+ return final_answer, iteration_results
+
+
+# 定义函数:分析迭代效果
+def analyze_iteration_effect(iteration_results):
+ """分析迭代效果,比较不同迭代的结果"""
+ print("\n" + "=" * 50)
+ print("迭代效果分析")
+ print("=" * 50)
+
+ for i, result in enumerate(iteration_results):
+ print(f"\n第 {result['iteration']} 次迭代分析:")
+ print(f"- 查询长度:{len(result['query'])} 字符")
+ print(f"- 答案长度:{len(result['answer'])} 字符")
+ print(f"- 上下文块数量:{len(result['context_chunks'])}")
+
+ # 简单的答案质量评估(基于长度和内容)
+ if "不知道" in result["answer"] or "无法" in result["answer"]:
+ quality = "低"
+ elif len(result["answer"]) > 100:
+ quality = "高"
+ else:
+ quality = "中"
+
+ print(f"- 答案质量评估:{quality}")
+
+
+# 主程序入口
+if __name__ == "__main__":
+ # 日志:程序启动
+ print("[日志] 迭代式RAG程序启动,准备接受用户输入。")
+
+ # 1. 用户输入Query
+ query = input("请输入您的问题:")
+
+ # 日志:打印用户输入的Query
+ print(f"[日志] 用户输入的问题为:{query}")
+ # 2. 设置迭代次数
+ try:
+ max_iterations = int(input("请输入迭代次数(建议2-3次):"))
+ if max_iterations < 1 or max_iterations > 5:
+ print("迭代次数超出范围,使用默认值2")
+ max_iterations = 2
+ except ValueError:
+ print("输入无效,使用默认迭代次数2")
+ max_iterations = 2
+
+ # 3. 执行迭代式RAG生成
+ final_answer, iteration_results = iterative_rag_generation(query, max_iterations)
+
+ # 4. 分析迭代效果
+ analyze_iteration_effect(iteration_results)
+
+ # 5. 输出最终答案
+ print("\n" + "=" * 60)
+ print("【最终答案】")
+ print("=" * 60)
+ print(final_answer)
+
+ print(f"\n迭代式RAG生成完成,共执行 {max_iterations} 次迭代。")
6.6 执行过程 #
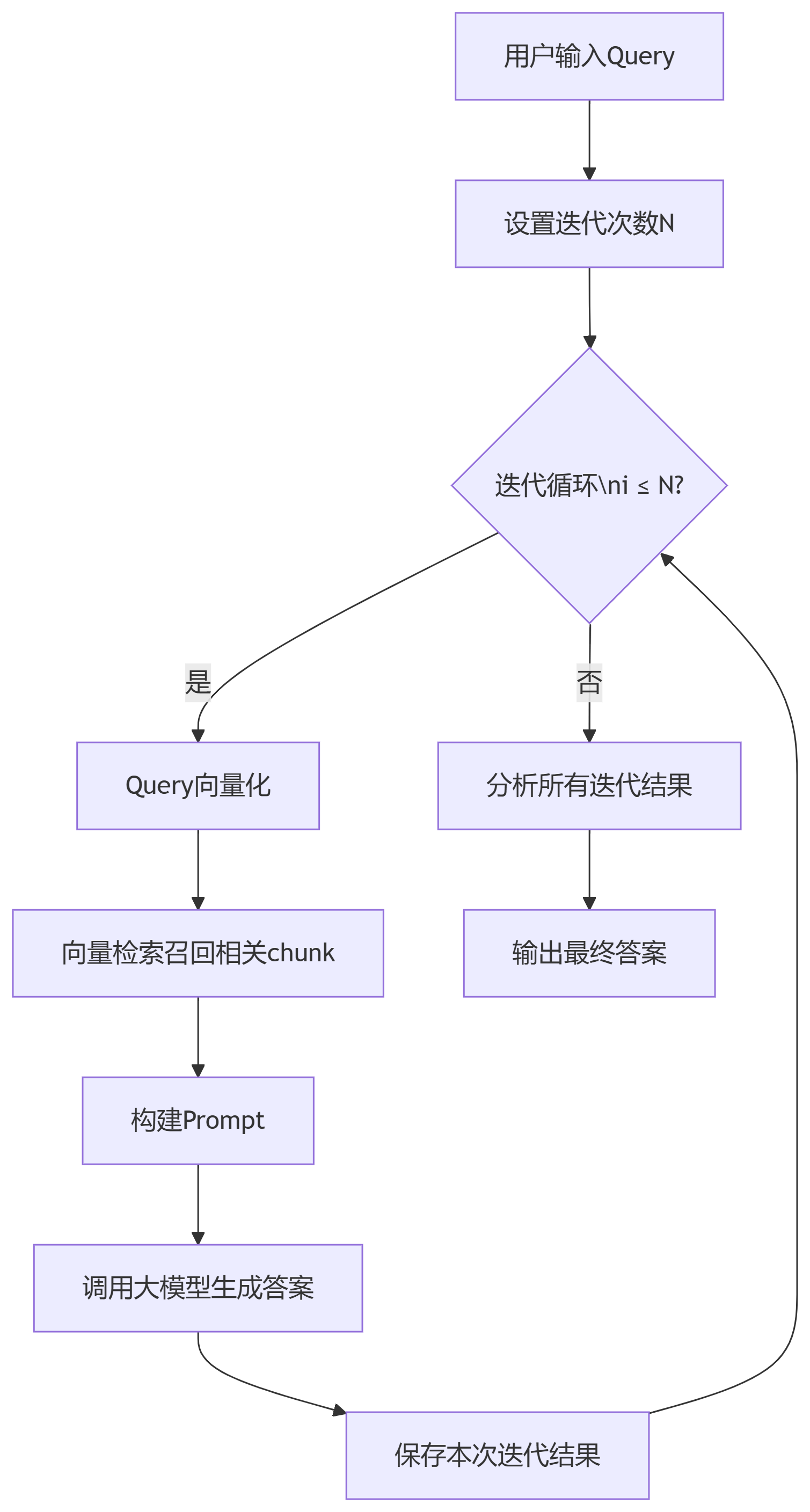
用户输入Query
用户输入一个自然语言问题,作为初始查询。设置迭代次数
用户输入希望执行的迭代次数(建议2-3次,最大5次)。迭代循环
进入迭代RAG主循环,每次迭代包括以下步骤:Query向量化
将当前查询(初始或上一次迭代后的新查询)转为向量。向量检索召回相关chunk
在向量数据库中检索与当前查询最相关的文本块(chunk)。构建Prompt
将检索到的chunk拼接为上下文,与当前查询一起构建大模型输入Prompt。调用大模型生成答案
用大模型(如ollama_qa)生成本次迭代的答案。保存本次迭代结果
记录本次的查询、答案和上下文,为后续分析和下一轮迭代做准备。构建下一轮查询
如果不是最后一次迭代,将“原始查询+上一次答案”合并为新的查询,进入下一轮。
分析所有迭代结果
所有迭代完成后,对每轮的查询、答案、上下文长度等进行分析和质量评估。输出最终答案
输出最后一次迭代生成的答案,并提示共执行了多少次迭代。
7. 智能自判别检索增强 #
在传统的RAG(检索增强生成)系统中,评估环节往往在答案生成完成后才进行,这种后置评估模式存在明显的局限性。Self RAG作为一种前沿的智能判别技术,将评估机制前置到生成流程的各个环节中,实现了真正的智能化质量控制。
7.1 核心技术原理 #
Self RAG的核心思想是在RAG的每个关键节点嵌入智能判别模块,通过实时评估来动态调整策略选择。这种设计打破了传统RAG的线性流程,引入了反馈循环机制,使得系统能够自我优化和迭代改进。
7.2 判别模块设计 #
7.2.1. 文档相关性判别 #
在检索阶段,系统会智能判断返回的文档与用户问题的相关程度。通过预设的判别标准,自动筛选出高相关性的文档,过滤掉无关内容。当检索结果不理想时,系统会触发查询增强策略,如查询重写、假设文档生成等技术手段。
7.2.2. 答案可信度验证 #
在答案生成后,系统会从两个维度进行验证:
- 上下文支持度检查:验证生成的答案是否能在提供的文档中找到依据,避免模型"编造"信息
- 问题解答完整性:评估答案是否真正解决了用户提出的问题
7.3 动态策略选择机制 #
Self RAG采用条件分支逻辑,根据每个判别节点的结果动态选择后续策略:
- 当文档相关性不足时,触发查询增强或重新检索
- 当答案缺乏上下文支持时,进行多次生成尝试或直接返回"无法回答"
- 当答案无法解决问题时,进入下一轮迭代优化
7.4 代码实现 #
SelfRAG.py
+# Self RAG:智能自判别检索增强生成技术
+# 导入句子嵌入模型库
from sentence_transformers import SentenceTransformer
+# 导入Chroma数据库库
import chromadb
+# 导入豆包大模型问答接口
+from llm.doubao import doubao_qa
+# 导入正则表达式库
+import re
+# 加载本地的句子嵌入模型
model = SentenceTransformer("all-MiniLM-L6-v2")
+# 创建持久化的Chroma客户端,指定数据库路径
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
# 定义函数:将query转为embedding向量
def get_query_embedding(query):
# 打印提示信息
+ print("[Self RAG] 正在进行Query向量化...")
# 对输入的query进行向量化并返回
return model.encode(query).tolist()
# 定义函数:向量检索,返回最相关的文本块列表
+def retrieve_related_chunks(query_embedding, n_results=5):
# 打印检索提示信息
+ print(f"[Self RAG] 正在进行向量检索,返回最相关的{n_results}个文本块...")
# 在Chroma集合中进行向量检索
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
# 获取检索到的文档内容
related_chunks = results.get("documents")
# 如果没有检索到内容,提示并返回空列表
if not related_chunks or not related_chunks[0]:
+ print("[Self RAG] 未检索到相关内容,请先入库或检查数据库!")
+ return []
# 打印检索到的文本块数量
+ print(f"[Self RAG] 成功检索到{len(related_chunks[0])}个相关文本块。")
# 返回最相关的文本块列表
return related_chunks[0]
+# 定义函数:文档相关性判别模块
+def judge_document_relevance(query, documents, threshold=0.7):
# 打印相关性判别提示
+ print("[Self RAG] 正在进行文档相关性判别...")
# 构建判别提示词
+ judge_prompt = f"""
+请判断以下文档是否与用户问题相关。请只回答"相关"或"不相关"。
+用户问题:{query}
+文档内容:
+{chr(10).join([f"文档{i+1}: {doc}" for i, doc in enumerate(documents)])}
+请逐个判断每个文档的相关性,格式如下:
+文档1: [相关/不相关]
+文档2: [相关/不相关]
+...
+"""
# 调用大模型进行判别
+ judgment = doubao_qa(judge_prompt)
# 打印判别结果
+ print(f"[Self RAG] 判别结果:{judgment}")
# 解析判别结果
+ relevant_docs = []
+ if judgment:
+ # 按行分割判别结果
+ lines = judgment.strip().split("\n")
+ # 遍历每一行判别结果,筛选出相关文档
+ for i, line in enumerate(lines):
+ if "相关" in line and i < len(documents):
+ relevant_docs.append(documents[i])
# 打印筛选出的相关文档数量
+ print(f"[Self RAG] 筛选出{len(relevant_docs)}个相关文档")
# 返回相关文档列表
+ return relevant_docs
+# 定义函数:查询增强策略
+def query_enhancement(query, iteration=1):
# 打印查询增强提示
+ print(f"[Self RAG] 正在进行第{iteration}轮查询增强...")
# 构建查询增强提示词
+ enhancement_prompt = f"""
+请对以下问题进行查询重写,生成更精确的检索查询。要求:
+1. 保持原问题的核心含义
+2. 添加更多关键词和细节
+3. 使用更具体的表达方式
+原问题:{query}
+请生成3个增强后的查询:
+"""
# 调用大模型生成增强查询
+ enhanced_queries = doubao_qa(enhancement_prompt)
# 打印增强查询结果
+ print(f"[Self RAG] 查询增强结果:{enhanced_queries}")
# 提取增强后的查询
+ queries = []
+ if enhanced_queries:
+ # 按行分割增强查询结果
+ lines = enhanced_queries.strip().split("\n")
+ # 遍历每一行,筛选有效的增强查询
+ for line in lines:
+ if line.strip() and not line.startswith("原问题"):
+ queries.append(line.strip())
# 返回前3个增强查询
+ return queries[:3]
+# 定义函数:答案可信度验证模块
+def verify_answer_credibility(query, context, answer):
# 打印答案验证提示
+ print("[Self RAG] 正在进行答案可信度验证...")
# 构建上下文支持度检查提示词
+ support_check_prompt = f"""
+请判断以下答案是否能在提供的上下文中找到依据。请只回答"有依据"或"无依据"。
+用户问题:{query}
+上下文信息:
+{context}
+生成的答案:
+{answer}
+判断:这个答案是否能在上下文中找到支持依据?
+"""
# 调用大模型进行上下文支持度检查
+ support_result = doubao_qa(support_check_prompt)
# 打印支持度检查结果
+ print(f"[Self RAG] 上下文支持度检查结果:{support_result}")
# 构建问题解答完整性检查提示词
+ completeness_check_prompt = f"""
+请判断以下答案是否完整回答了用户问题。请只回答"完整"或"不完整"。
+用户问题:{query}
+生成的答案:
+{answer}
+判断:这个答案是否完整回答了用户问题?
+"""
# 调用大模型进行完整性检查
+ completeness_result = doubao_qa(completeness_check_prompt)
# 打印完整性检查结果
+ print(f"[Self RAG] 问题解答完整性检查结果:{completeness_result}")
# 判断答案是否有依据和是否完整
+ has_support = support_result and "有依据" in support_result
+ is_complete = completeness_result and "完整" in completeness_result
# 返回支持度和完整性判断结果
+ return has_support, is_complete
+# 定义函数:基于上下文生成答案
+def generate_answer_with_context(query, context):
# 打印生成答案提示
+ print("[Self RAG] 正在基于上下文生成答案...")
# 构建生成答案的提示词
+ prompt = f"""
+请根据以下上下文信息回答用户问题。要求:
+1. 答案必须基于提供的上下文信息
+2. 如果上下文中没有相关信息,请明确说明"无法从提供的信息中找到答案"
+3. 答案要准确、完整、有条理
+上下文信息:
+{context}
+用户问题:{query}
+答案:
+"""
# 调用大模型生成答案
+ answer = doubao_qa(prompt)
# 打印答案生成完成提示
+ print("[Self RAG] 答案生成完成")
# 返回生成的答案
+ return answer
+# 定义Self RAG主流程
+def self_rag_pipeline(query, max_iterations=3):
# 打印流程启动提示
+ print(f"[Self RAG] 开始Self RAG流程,最大迭代次数:{max_iterations}")
# 迭代执行RAG流程
+ for iteration in range(1, max_iterations + 1):
+ # 打印当前迭代轮次
+ print(f"\n[Self RAG] ===== 第{iteration}轮迭代 =====")
+ # 1. Query向量化
+ query_embedding = get_query_embedding(query)
+ # 2. 向量检索
+ related_chunks = retrieve_related_chunks(query_embedding, n_results=5)
+ # 如果未检索到相关内容,尝试查询增强
+ if not related_chunks:
+ print("[Self RAG] 检索失败,尝试查询增强...")
+ enhanced_queries = query_enhancement(query, iteration)
+ if enhanced_queries:
+ # 使用第一个增强查询重新检索
+ enhanced_embedding = get_query_embedding(enhanced_queries[0])
+ related_chunks = retrieve_related_chunks(
+ enhanced_embedding, n_results=5
+ )
+ # 如果仍未检索到,返回失败信息
+ if not related_chunks:
+ return "抱歉,无法找到相关信息来回答您的问题。"
+ # 3. 文档相关性判别
+ relevant_docs = judge_document_relevance(query, related_chunks)
+ # 如果没有相关文档,尝试查询增强或返回失败
+ if not relevant_docs:
+ print("[Self RAG] 没有找到相关文档,尝试查询增强...")
+ if iteration < max_iterations:
+ enhanced_queries = query_enhancement(query, iteration)
+ if enhanced_queries:
+ # 使用增强查询继续下一轮
+ query = enhanced_queries[0]
+ continue
+ else:
+ return "抱歉,无法找到相关信息来回答您的问题。"
+ # 4. 生成答案
+ context = "\n".join(relevant_docs)
+ answer = generate_answer_with_context(query, context)
+ # 5. 答案可信度验证
+ has_support, is_complete = verify_answer_credibility(query, context, answer)
+ # 6. 动态策略选择
+ if has_support and is_complete:
+ # 如果答案有依据且完整,直接返回
+ print("[Self RAG] 答案通过验证,返回最终结果")
+ return answer
+ elif not has_support:
+ # 如果答案缺乏上下文支持,进行多次生成尝试
+ print("[Self RAG] 答案缺乏上下文支持,进行多次生成尝试...")
+ for attempt in range(3):
+ # 打印当前尝试次数
+ print(f"[Self RAG] 第{attempt + 1}次生成尝试...")
+ new_answer = generate_answer_with_context(query, context)
+ new_has_support, new_is_complete = verify_answer_credibility(
+ query, context, new_answer
+ )
+ if new_has_support and new_is_complete:
+ print("[Self RAG] 找到可信答案")
+ return new_answer
+ # 如果多次尝试仍失败,进入下一轮或返回失败
+ if iteration < max_iterations:
+ print("[Self RAG] 答案验证失败,进入下一轮迭代...")
+ enhanced_queries = query_enhancement(query, iteration)
+ if enhanced_queries:
+ query = enhanced_queries[0]
+ continue
+ else:
+ return "抱歉,无法生成可信的答案。"
+ else:
+ # 如果答案不完整,进入下一轮迭代
+ print("[Self RAG] 答案不完整,进入下一轮迭代...")
+ if iteration < max_iterations:
+ enhanced_queries = query_enhancement(query, iteration)
+ if enhanced_queries:
+ query = enhanced_queries[0]
+ continue
# 多轮迭代后仍未生成满意答案,返回失败信息
+ return "抱歉,经过多次迭代仍无法生成满意的答案。"
+# 主程序入口
+if __name__ == "__main__":
# 打印系统启动信息
+ print("[Self RAG] Self RAG智能自判别检索增强生成系统启动")
# 打印系统特点
+ print("[Self RAG] 系统特点:")
+ print("1. 文档相关性智能判别")
+ print("2. 答案可信度实时验证")
+ print("3. 动态策略选择机制")
+ print("4. 多轮迭代优化")
# 用户输入Query
+ query = input("\n请输入您的问题:")
# 打印用户输入的问题
+ print(f"[Self RAG] 用户问题:{query}")
# 执行Self RAG流程
+ final_answer = self_rag_pipeline(query, max_iterations=3)
# 打印最终答案
+ print(f"\n[Self RAG] ===== 最终答案 =====")
+ print(final_answer)
7.5 流程图 #
系统架构图
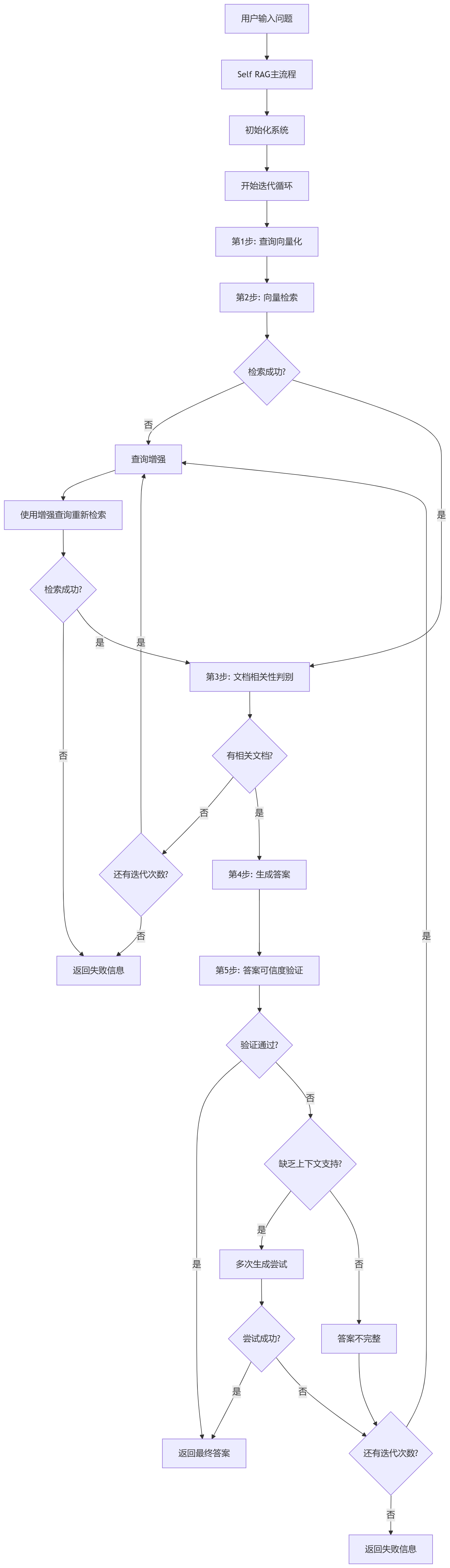
详细执行流程图
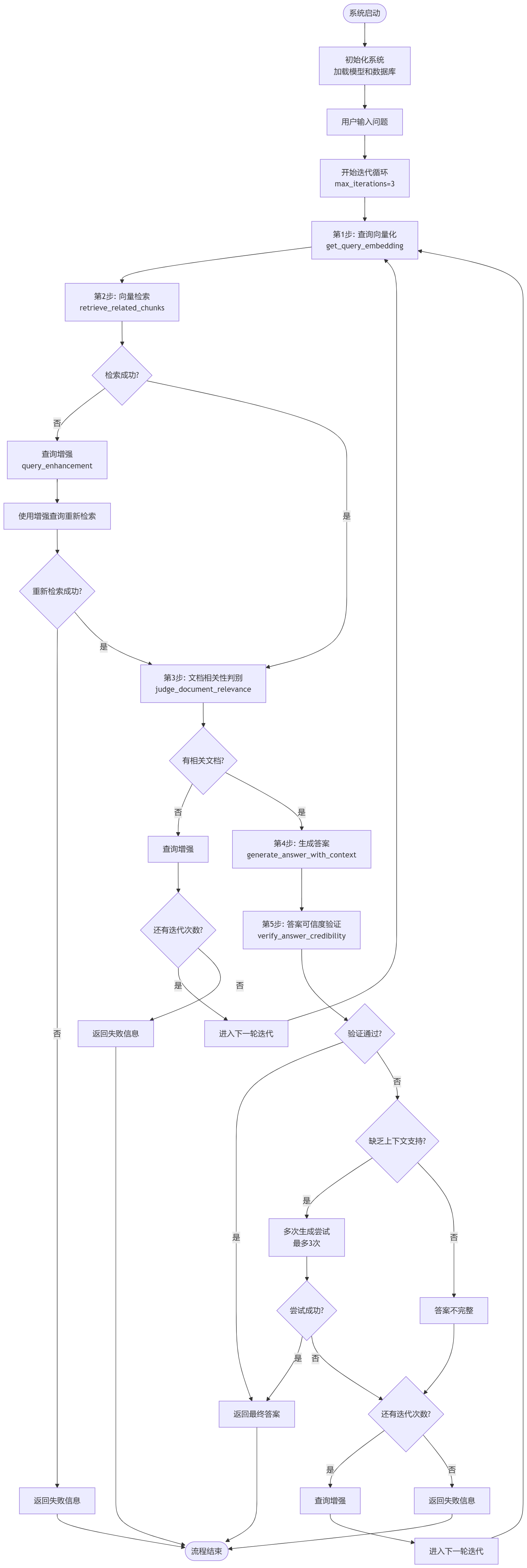
判别模块详细流程
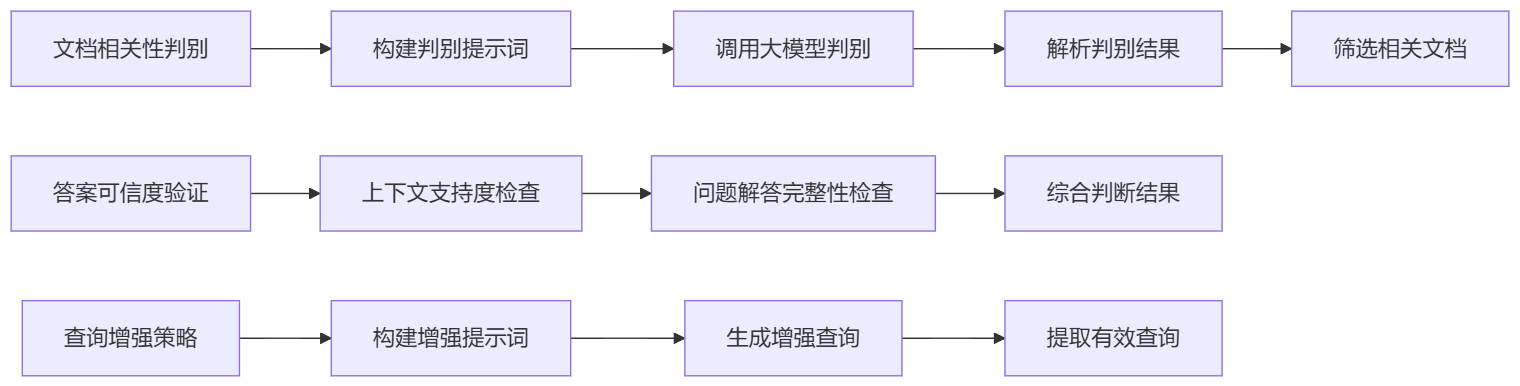
动态策略选择逻辑
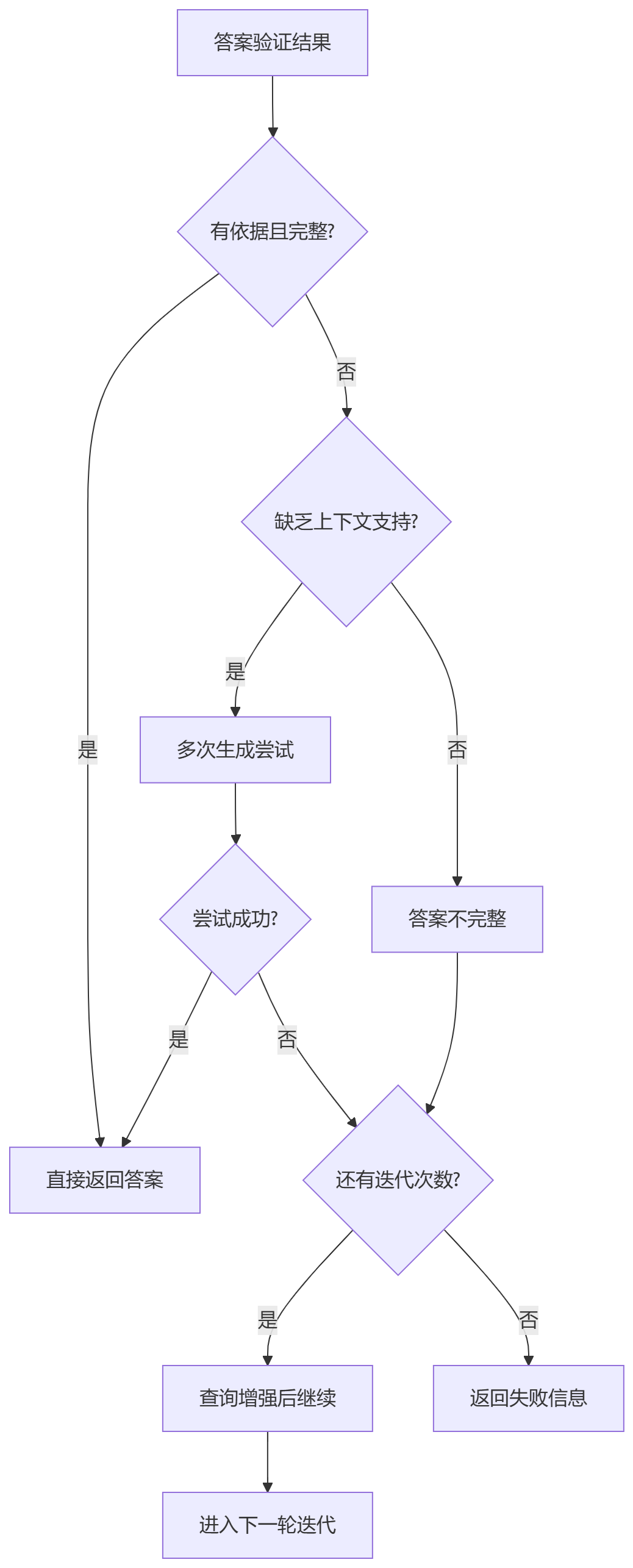
7.6 工作流程 #
每轮迭代包含6个核心步骤:
- 查询向量化 → 将文本转换为向量表示
- 向量检索 → 在数据库中检索相关文档
- 文档相关性判别 → 智能筛选真正相关的文档
- 答案生成 → 基于上下文生成答案
- 答案可信度验证 → 双重验证(支持度+完整性)
- 动态策略选择 → 根据验证结果选择后续策略
智能判别机制
文档相关性判别:
- 使用大模型判断每个文档与问题的相关程度
- 过滤掉不相关文档,提高后续处理质量
答案可信度验证:
- 上下文支持度检查:验证答案是否能在文档中找到依据
- 问题解答完整性检查:评估答案是否完整回答了问题
动态策略选择
根据验证结果采用不同策略:
- ✅ 验证通过 → 直接返回答案
- ❌ 缺乏支持 → 最多3次重新生成尝试
- ⚠️ 答案不完整 → 进入下一轮迭代
- �� 查询增强 → 智能重写查询后重新检索
5. 容错与优化机制
- 查询增强:当检索失败时,自动重写查询
- 多次尝试:答案验证失败时进行多次生成
- 迭代优化:最多3轮迭代,持续改进结果
- 失败处理:提供明确的失败信息和原因
每轮迭代包含6个核心步骤:
- 查询向量化 → 将文本转换为向量表示
- 向量检索 → 在数据库中检索相关文档
- 文档相关性判别 → 智能筛选真正相关的文档
- 答案生成 → 基于上下文生成答案
- 答案可信度验证 → 双重验证(支持度+完整性)
- 动态策略选择 → 根据验证结果选择后续策略
智能判别机制
文档相关性判别:
- 使用大模型判断每个文档与问题的相关程度
- 过滤掉不相关文档,提高后续处理质量
答案可信度验证:
- 上下文支持度检查:验证答案是否能在文档中找到依据
- 问题解答完整性检查:评估答案是否完整回答了问题
动态策略选择
根据验证结果采用不同策略:
- ✅ 验证通过 → 直接返回答案
- ❌ 缺乏支持 → 最多3次重新生成尝试
- ⚠️ 答案不完整 → 进入下一轮迭代
- �� 查询增强 → 智能重写查询后重新检索
5. 容错与优化机制
- 查询增强:当检索失败时,自动重写查询
- 多次尝试:答案验证失败时进行多次生成
- 迭代优化:最多3轮迭代,持续改进结果
- 失败处理:提供明确的失败信息和原因