1.项目介绍 #
2. 读取数据 #
import.py
# 导入pandas库,并简写为pd,用于数据处理
import pandas as pd
# 读取名为"books.csv"的CSV文件,并将其内容存入DataFrame对象df中
df = pd.read_csv("books.csv")
# 从df中提取所有书名,去重后存入集合books
books = set(df["name"])
# 从df中提取所有作者名,去重后存入集合authors
authors = set(df["author"])
# 从df中提取所有出版社名,去重后存入集合publishers
publishers = set(df["publisher"])
# 从df中提取所有类别,去重后存入集合categories
categories = set(df["category"])
# 创建一个空集合,用于存放所有关键词
keywords = set()
# 遍历df中每一行的"keywords"字段
for each in df["keywords"]:
# 将每个关键词字符串按分号分割,并添加到keywords集合中
keywords.update(each.split(";"))3. 读取关系 #
3.1 df.iterrows #
- 这是 Pandas DataFrame 的一个行迭代器方法。
- 用于逐行遍历DataFrame,每次返回一对
(index, row),其中:index是行号(索引)row是一行数据(Series对象)
常见用法:
for idx, row in df.iterrows():
print(idx, row["title"], row["author"])- 这样可以一行一行地处理表格里的每条数据。
3.2. import.py #
import.py
# 导入pandas库,并简写为pd,用于数据处理
import pandas as pd
# 读取名为"books.csv"的CSV文件,并将其内容存入DataFrame对象df中
df = pd.read_csv("books.csv")
# 从df中提取所有书名,去重后存入集合books
books = set(df["name"])
# 从df中提取所有作者名,去重后存入集合authors
authors = set(df["author"])
# 从df中提取所有出版社名,去重后存入集合publishers
publishers = set(df["publisher"])
# 从df中提取所有类别,去重后存入集合categories
categories = set(df["category"])
# 创建一个空集合,用于存放所有关键词
keywords = set()
# 遍历df中每一行的"keywords"字段
for each in df["keywords"]:
# 将每个关键词字符串按分号分割,并添加到keywords集合中
keywords.update(each.split(";"))
# 创建一个空列表,用于存储“书籍-作者”关系
+rels_written_by = []
# 创建一个空列表,用于存储“书籍-出版社”关系
+rels_published_by = []
# 创建一个空列表,用于存储“书籍-类别”关系
+rels_has_category = []
# 创建一个空列表,用于存储“书籍-关键词”关系
+rels_has_keyword = []
# 遍历DataFrame中的每一行
+for idx, row in df.iterrows():
# 将当前书名和作者组成的列表添加到rels_written_by中
+ rels_written_by.append([row["name"], row["author"]])
# 将当前书名和出版社组成的列表添加到rels_published_by中
+ rels_published_by.append([row["name"], row["publisher"]])
# 将当前书名和类别组成的列表添加到rels_has_category中
+ rels_has_category.append([row["name"], row["category"]])
# 将当前行的关键词按分号分割,遍历每个关键词
+ for kw in row["keywords"].split(";"):
# 将当前书名和关键词组成的列表添加到rels_has_keyword中
+ rels_has_keyword.append([row["name"], kw])
4. 连接数据库创建实体 #
4.1. import.py #
import.py
# 导入pandas库,并简写为pd,用于数据处理
import pandas as pd
+from py2neo import Graph, Node
# 读取名为"books.csv"的CSV文件,并将其内容存入DataFrame对象df中
df = pd.read_csv("books.csv")
# 从df中提取所有书名,去重后存入集合books
books = set(df["name"])
# 从df中提取所有作者名,去重后存入集合authors
authors = set(df["author"])
# 从df中提取所有出版社名,去重后存入集合publishers
publishers = set(df["publisher"])
# 从df中提取所有类别,去重后存入集合categories
categories = set(df["category"])
# 创建一个空集合,用于存放所有关键词
keywords = set()
# 遍历df中每一行的"keywords"字段
for each in df["keywords"]:
# 将每个关键词字符串按分号分割,并添加到keywords集合中
keywords.update(each.split(";"))
# 创建一个空列表,用于存储“书籍-作者”关系
rels_written_by = []
# 创建一个空列表,用于存储“书籍-出版社”关系
rels_published_by = []
# 创建一个空列表,用于存储“书籍-类别”关系
rels_has_category = []
# 创建一个空列表,用于存储“书籍-关键词”关系
rels_has_keyword = []
# 遍历DataFrame中的每一行
for idx, row in df.iterrows():
# 将当前书名和作者组成的列表添加到rels_written_by中
rels_written_by.append([row["name"], row["author"]])
# 将当前书名和出版社组成的列表添加到rels_published_by中
rels_published_by.append([row["name"], row["publisher"]])
# 将当前书名和类别组成的列表添加到rels_has_category中
rels_has_category.append([row["name"], row["category"]])
# 将当前行的关键词按分号分割,遍历每个关键词
for kw in row["keywords"].split(";"):
# 将当前书名和关键词组成的列表添加到rels_has_keyword中
rels_has_keyword.append([row["name"], kw])
# 连接Neo4j
+g = Graph("bolt://localhost:7687", auth=("neo4j", "12345678"))
# 删除所有实体和关系
+cypher = "MATCH (n) DETACH DELETE n"
+g.run(cypher)
# 遍历所有书名,为每本书创建一个“Book”节点
+for name in books:
# 根据书名从DataFrame中获取对应的行数据
+ row = df[df["name"] == name].iloc[0]
# 创建Book节点,包含书名、出版年份和简介属性
+ node = Node(
+ "Book",
+ name=str(name),
+ publish_year=int(row["publish_year"]),
+ summary=str(row["summary"]),
+ )
# 将节点写入Neo4j数据库
+ g.create(node)
# 打印已创建的图书实体名称
+ print("创建图书实体:", name)
# 遍历所有作者名,为每位作者创建一个“Author”节点
+for author in authors:
# 创建Author节点,包含作者名属性
+ node = Node("Author", name=str(author))
# 将节点写入Neo4j数据库
+ g.create(node)
# 打印已创建的作者实体名称
+ print("创建作者实体:", author)
# 遍历所有出版社名,为每个出版社创建一个“Publisher”节点
+for publisher in publishers:
# 创建Publisher节点,包含出版社名属性
+ node = Node("Publisher", name=str(publisher))
# 将节点写入Neo4j数据库
+ g.create(node)
# 打印已创建的出版社实体名称
+ print("创建出版社实体:", publisher)
# 遍历所有类别,为每个类别创建一个“Category”节点
+for category in categories:
# 创建Category节点,包含类别名属性
+ node = Node("Category", name=str(category))
# 将节点写入Neo4j数据库
+ g.create(node)
# 打印已创建的类别实体名称
+ print("创建类别实体:", category)
# 遍历所有关键词,为每个关键词创建一个“Keyword”节点
+for kw in keywords:
# 创建Keyword节点,包含关键词名属性
+ node = Node("Keyword", name=str(kw))
# 将节点写入Neo4j数据库
+ g.create(node)
# 打印已创建的关键词实体名称
+ print("创建关键词实体:", kw)
5. 创建关系 #
5.1 apoc.meta.graph #
CALL apoc.meta.graph() 是 APOC 库中一个非常有用的元过程(meta procedure),用于提取和分析当前 Neo4j 数据库的图模式(schema)信息。它会返回数据库中存在的节点标签、关系类型以及它们之间的连接模式。
这个过程会扫描整个数据库(或指定的子图)并返回一个可视化的图模式表示,包括:
- 所有存在的节点标签(Node Labels)
- 所有存在的关系类型(Relationship Types)
- 这些标签和类型之间是如何相互连接的
5.1.1 基本用法 #
最简单的调用方式:
CALL apoc.meta.graph()5.1.2 返回值 #
该过程返回一个包含图模式信息的记录,通常包括以下部分:
- nodes: 代表不同节点标签的虚拟节点
- relationships: 代表标签之间关系的虚拟关系
每个返回的"节点"实际上代表了一类具有相同标签的节点,每个"关系"代表了一类实际存在的关系类型。
5.2 查看所有的节点和关系 #
MATCH (n) OPTIONAL MATCH (n)-[r]->(m) RETURN n,r,mMATCH (n)
- 这是查询的起点,匹配数据库中的所有节点
n是一个变量名,用于引用匹配到的节点- 这部分会找到图中所有的节点,不论它们的标签或属性如何
OPTIONAL MATCH (n)-[r]->(m)
OPTIONAL MATCH是Cypher中的可选匹配子句- 它尝试找到从每个
n节点出发的所有出向关系 r变量代表关系m变量代表关系指向的目标节点- 如果某个
n节点没有出向关系,这部分不会导致该节点被过滤掉,而是将r和m设为null
RETURN n,r,m
- 指定查询返回的结果
- 对于每个匹配,返回源节点
n、关系r和目标节点m - 如果某节点没有出向关系,
r和m将为null
这个查询会:
- 首先匹配数据库中的所有节点(
MATCH (n)) - 然后对于每个找到的节点
n,尝试找到:- 从
n出发的所有关系r - 通过这些关系
r连接到的所有目标节点m
- 从
- 最后返回三元组
(n, r, m)
5.3 创建关系 #
import.py
# 导入pandas库,并简写为pd,用于数据处理
import pandas as pd
from py2neo import Graph, Node
# 读取名为"books.csv"的CSV文件,并将其内容存入DataFrame对象df中
df = pd.read_csv("books.csv")
# 从df中提取所有书名,去重后存入集合books
books = set(df["name"])
# 从df中提取所有作者名,去重后存入集合authors
authors = set(df["author"])
# 从df中提取所有出版社名,去重后存入集合publishers
publishers = set(df["publisher"])
# 从df中提取所有类别,去重后存入集合categories
categories = set(df["category"])
# 创建一个空集合,用于存放所有关键词
keywords = set()
# 遍历df中每一行的"keywords"字段
for each in df["keywords"]:
# 将每个关键词字符串按分号分割,并添加到keywords集合中
keywords.update(each.split(";"))
# 创建一个空列表,用于存储“书籍-作者”关系
rels_written_by = []
# 创建一个空列表,用于存储“书籍-出版社”关系
rels_published_by = []
# 创建一个空列表,用于存储“书籍-类别”关系
rels_has_category = []
# 创建一个空列表,用于存储“书籍-关键词”关系
rels_has_keyword = []
# 遍历DataFrame中的每一行
for idx, row in df.iterrows():
# 将当前书名和作者组成的列表添加到rels_written_by中
rels_written_by.append([row["name"], row["author"]])
# 将当前书名和出版社组成的列表添加到rels_published_by中
rels_published_by.append([row["name"], row["publisher"]])
# 将当前书名和类别组成的列表添加到rels_has_category中
rels_has_category.append([row["name"], row["category"]])
# 将当前行的关键词按分号分割,遍历每个关键词
for kw in row["keywords"].split(";"):
# 将当前书名和关键词组成的列表添加到rels_has_keyword中
rels_has_keyword.append([row["name"], kw])
# 连接Neo4j
g = Graph("bolt://localhost:7687", auth=("neo4j", "12345678"))
# 删除所有实体和关系
cypher = "MATCH (n) DETACH DELETE n"
g.run(cypher)
# 遍历所有书名,为每本书创建一个“Book”节点
for name in books:
# 根据书名从DataFrame中获取对应的行数据
row = df[df["name"] == name].iloc[0]
# 创建Book节点,包含书名、出版年份和简介属性
node = Node(
"Book",
name=str(name),
publish_year=int(row["publish_year"]),
summary=str(row["summary"]),
)
# 将节点写入Neo4j数据库
g.create(node)
# 打印已创建的图书实体名称
print("创建图书实体:", name)
# 遍历所有作者名,为每位作者创建一个“Author”节点
for author in authors:
# 创建Author节点,包含作者名属性
node = Node("Author", name=str(author))
# 将节点写入Neo4j数据库
g.create(node)
# 打印已创建的作者实体名称
print("创建作者实体:", author)
# 遍历所有出版社名,为每个出版社创建一个“Publisher”节点
for publisher in publishers:
# 创建Publisher节点,包含出版社名属性
node = Node("Publisher", name=str(publisher))
# 将节点写入Neo4j数据库
g.create(node)
# 打印已创建的出版社实体名称
print("创建出版社实体:", publisher)
# 遍历所有类别,为每个类别创建一个“Category”节点
for category in categories:
# 创建Category节点,包含类别名属性
node = Node("Category", name=str(category))
# 将节点写入Neo4j数据库
g.create(node)
# 打印已创建的类别实体名称
print("创建类别实体:", category)
# 遍历所有关键词,为每个关键词创建一个“Keyword”节点
for kw in keywords:
# 创建Keyword节点,包含关键词名属性
node = Node("Keyword", name=str(kw))
# 将节点写入Neo4j数据库
g.create(node)
# 打印已创建的关键词实体名称
print("创建关键词实体:", kw)
# 定义一个函数,用于在Neo4j中创建关系
+def create_relationship(start_label, end_label, edges, rel_type, rel_name):
# 遍历所有的关系对
+ for edge in edges:
# 获取起始节点的名称,并转换为字符串
+ p = str(edge[0])
# 获取终止节点的名称,并转换为字符串
+ q = str(edge[1])
# 构造Cypher查询语句,匹配起始和终止节点,并创建关系
+ query = (
+ f"MATCH (p:{start_label}),(q:{end_label}) WHERE p.name='{p}' AND q.name='{q}' "
+ f"CREATE (p)-[rel:{rel_type}{{name:'{rel_name}'}}]->(q)"
+ )
+ try:
# 执行Cypher查询,创建关系
+ g.run(query)
# 打印已创建的关系信息
+ print(f"创建关系 {p}-{rel_type}->{q}")
+ except Exception as e:
# 如果出错,打印异常信息
+ print(e)
# 创建“Book-Author”之间的“written_by”关系
+create_relationship("Book", "Author", rels_written_by, "written_by", "作者")
# 创建“Book-Publisher”之间的“published_by”关系
+create_relationship("Book", "Publisher", rels_published_by, "published_by", "出版社")
# 创建“Book-Category”之间的“has_category”关系
+create_relationship("Book", "Category", rels_has_category, "has_category", "类别")
# 创建“Book-Keyword”之间的“has_keyword”关系
+create_relationship("Book", "Keyword", rels_has_keyword, "has_keyword", "关键词")6. 初始化embedding #
6.1 execute_query #
driver.execute_query() 返回的是一个 neo4j.Result 对象,它包含以下主要组件:
- records: 包含查询返回的所有记录(行数据)
- summary: 包含查询执行的元数据(如执行时间、统计信息等)
- keys: 返回结果的列名列表
`
node 是 neo4j.Record 类型的对象,主要特点:
- 行为类似字典,可以通过字段名访问数据
- 也支持类似元组的访问方式
- 主要访问方式:
node["name"]: 通过字段名访问node[0]: 通过索引访问(第一列)node.get("name"): 安全获取方法,可提供默认值node.items(): 获取所有字段键值对node.data(): 获取所有字段键值对
6.2 init_embedding.py #
# 导入neo4j驱动库
from neo4j import GraphDatabase
# 导入requests库,用于发送HTTP请求
import requests
# 定义火山方舟嵌入API的URL
VOLC_EMBEDDINGS_API_URL = "https://ark.cn-beijing.volces.com/api/v3/embeddings"
# 定义火山方舟API的密钥
VOLC_API_KEY = "d52e49a1-36ea-44bb-bc6e-65ce789a72f6"
# 定义获取文本嵌入向量的函数
def get_embedding(doc_content):
# 设置HTTP请求头,包括内容类型和授权信息
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {VOLC_API_KEY}",
}
# 构造请求体,指定模型和输入内容
payload = {"model": "doubao-embedding-text-240715", "input": doc_content}
# 发送POST请求到嵌入API
response = requests.post(VOLC_EMBEDDINGS_API_URL, json=payload, headers=headers)
# 如果请求成功
if response.status_code == 200:
# 解析返回的JSON数据
data = response.json()
# 提取嵌入向量
embedding = data["data"][0]["embedding"]
# 返回嵌入向量
return embedding
else:
# 如果请求失败,抛出异常并输出错误信息
raise Exception(f"Embedding API error: {response.text}")
# 主函数
def main():
# 连接Neo4j数据库
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "12345678"))
# 定义需要处理的节点标签
node_labels = [
"Book",
"Author",
]
# 遍历每种节点类型
for node_label in node_labels:
# 查询所有该类型节点的名称
result = driver.execute_query(f"match (n:{node_label}) return n.name as name")
# 获取所有查询结果
nodes = result.records
# 打印该类型节点的数量
print(f"共找到 {len(nodes)} 个 {node_label} 节点")
# 遍历每个节点
for record in nodes:
# 获取节点数据
data = record.data()
# 获取节点名称
name = data.get("name")
# 获取该名称的嵌入向量
embedding = get_embedding(name)
# 将嵌入向量写入Neo4j节点属性
driver.execute_query(
f"match (n:{node_label}) where n.name = $name set n.embedding=$embedding",
name=name,
embedding=embedding,
)
# 打印处理完成信息
print("数据处理完成!")
# 关闭数据库连接
driver.close()
# 如果当前脚本作为主程序运行,则执行main函数
if __name__ == "__main__":
main()7. 启动应用 #
7.1 set_page_config #
st.set_page_config() 是 Streamlit 提供的页面配置函数,用于设置整个应用的页面级属性。它必须是 Streamlit 脚本中的第一个命令(在所有其他 Streamlit 命令之前调用)。
page_title="图书知识图谱问答系统"
- 作用:设置网页的标题
- 显示位置:
- 浏览器标签页上显示的名称
- 当网页被收藏时的默认名称
- 在社交媒体分享时显示的标题
- 效果:将页面标题设为"图书知识图谱问答系统",让用户清楚知道这个应用的功能
layout="wide"
- 作用:设置页面的默认布局模式
- 可选值:
"centered"(默认):内容区域居中,两侧留有空白"wide":内容区域扩展到更宽的范围,减少两侧空白
- 效果:选择宽布局模式,更适合数据密集型的应用展示
7.2 app.py #
# 导入streamlit库,用于构建Web应用
import streamlit as st
# 定义主函数
def main():
# 设置Streamlit页面的标题和布局,必须是第一个Streamlit命令
st.set_page_config(page_title="图书知识图谱问答系统", layout="wide")
# 判断当前脚本是否作为主程序运行
if __name__ == "__main__":
# 调用主函数,启动应用
main()7.3 启动应用 #
streamlit run app.py8. 侧边栏 #
8.1 with st.sidebar #
with st.sidebar:- 作用:创建一个侧边栏容器,所有包含在其中的元素都会显示在页面左侧
- 优势:保持主界面整洁,将配置选项放在侧边栏
8.2 markdown #
st.markdown("### 参数设置", help="配置查询参数")- 功能:添加一个Markdown格式的小标题
- 参数:
"### 参数设置":三级标题,显示"参数设置"help:鼠标悬停时显示的提示文本
8.3 查询类型选择 #
query_type = st.radio("选择查询类型", ["图书", "作者"], index=0)- 组件类型:单选按钮(radio button)
- 参数:
- 标签文本:"选择查询类型"
- 选项列表:["图书", "作者"]
index=0:默认选中第一个选项("图书")
- 返回值:用户选择的值会赋给
query_type变量
8.4 结果数量滑块 #
top_k = st.slider("返回结果数量 (Top K)", 1, 10, 3, 1)- 组件类型:滑块控件
- 参数:
- 标签文本:"返回结果数量 (Top K)"
- 最小值:1
- 最大值:10
- 默认值:3
- 步长:1
- 用途:控制查询返回的结果数量
- 返回值:用户选择的值赋给
top_k变量
8.5 温度参数滑块 #
temperature = st.slider("温度 (Temperature)", 0.0, 1.0, 0.3, 0.1)- 组件类型:浮点数滑块
- 参数:
- 标签文本:"温度 (Temperature)"
- 最小值:0.0
- 最大值:1.0
- 默认值:0.3
- 步长:0.1
- 用途:控制生成式AI的创造性/随机性(常见于LLM模型)
- 返回值:用户选择的值赋给
temperature变量
8.6 app.py #
app.py
# 导入streamlit库,用于构建Web应用
import streamlit as st
# 定义主函数
def main():
# 设置Streamlit页面的标题和布局,必须是第一个Streamlit命令
st.set_page_config(page_title="图书知识图谱问答系统", layout="wide")
# 在侧边栏中创建一个区域,用于放置参数设置控件
+ with st.sidebar:
# 显示参数设置的标题,并提供悬浮提示
+ st.markdown("### 参数设置", help="配置查询参数")
# 创建单选框,让用户选择查询类型(图书或作者),默认选中“图书”
+ query_type = st.radio("选择查询类型", ["图书", "作者"], index=0)
# 创建滑块,让用户选择返回结果的数量,范围为1到10,默认值为3,步长为1
+ top_k = st.slider("返回结果数量 (Top K)", 1, 10, 3, 1)
# 创建滑块,让用户设置温度参数,范围为0.0到1.0,默认值为0.3,步长为0.1
+ temperature = st.slider("温度 (Temperature)", 0.0, 1.0, 0.3, 0.1)
# 判断当前脚本是否作为主程序运行
if __name__ == "__main__":
# 调用主函数,启动应用
main()9. 对话框 #
9.1. app.py #
app.py
# 导入streamlit库,用于构建Web应用
import streamlit as st
# 定义主函数
def main():
# 设置Streamlit页面的标题和布局,必须是第一个Streamlit命令
st.set_page_config(page_title="图书知识图谱问答系统", layout="wide")
# 在侧边栏中创建一个区域,用于放置参数设置控件
with st.sidebar:
# 显示参数设置的标题,并提供悬浮提示
st.markdown("### 参数设置", help="配置查询参数")
# 创建单选框,让用户选择查询类型(图书或作者),默认选中“图书”
query_type = st.radio("选择查询类型", ["图书", "作者"], index=0)
# 创建滑块,让用户选择返回结果的数量,范围为1到10,默认值为3,步长为1
top_k = st.slider("返回结果数量 (Top K)", 1, 10, 3, 1)
# 创建滑块,让用户设置温度参数,范围为0.0到1.0,默认值为0.3,步长为0.1
temperature = st.slider("温度 (Temperature)", 0.0, 1.0, 0.3, 0.1)
# 使用markdown在页面顶部居中显示蓝色标题
+ st.markdown(
+ "<h1 style='text-align: center; color: blue;'>图书知识图谱查询系统</h1>",
+ unsafe_allow_html=True,
+ )
# 如果session_state中还没有'messages',则初始化为空列表
+ if "messages" not in st.session_state:
+ st.session_state.messages = []
# 遍历历史消息,将其逐条显示在对话框中
+ for message in st.session_state.messages:
+ st.chat_message(message["role"]).write(message["content"])
# 如果用户在输入框中输入了内容(query不为空)
+ if query := st.chat_input("输入图书相关问题", key="query_input"):
# 将用户输入的内容追加到消息历史中
+ st.session_state.messages.append({"role": "user", "content": query})
# 在对话框中显示用户刚刚输入的内容
+ st.chat_message("user").write(query)
# 判断当前脚本是否作为主程序运行
if __name__ == "__main__":
# 调用主函数,启动应用
main()
9.2. 初始化会话消息列表 #
if "messages" not in st.session_state:
st.session_state.messages = []- 功能:检查会话状态中是否存在消息列表,不存在则初始化空列表
- 关键点:
st.session_state是Streamlit提供的会话状态管理工具- 使用字典形式存储跨多次运行的状态数据
- 这里用
messages键存储聊天消息历史
- 作用:确保每次页面刷新后仍能保留之前的聊天记录
9.3 渲染历史消息 #
for message in st.session_state.messages:
st.chat_message(message["role"]).write(message["content"])- 功能:遍历并显示所有已存储的聊天消息
- 组件解析:
st.chat_message():创建带有角色标识的消息容器- 接受
"user"或"assistant"作为角色参数
- 接受
.write():在消息容器中显示内容
- 数据结构:
- 每条消息是字典格式:
{"role": "user"/"assistant", "content": "消息文本"}
- 每条消息是字典格式:
- 效果:按顺序重新显示所有历史对话
9.4 处理用户新输入 #
if query := st.chat_input("输入图书相关问题", key="query_input"):
st.session_state.messages.append({"role": "user", "content": query})
st.chat_message("user").write(query)- 输入组件:
st.chat_input():创建底部聊天输入框- 参数
"输入图书相关问题"是输入框的占位提示文本 key参数确保输入框有唯一标识
- 参数
- 使用海象运算符
:=在判断的同时获取输入值
- 处理流程:
- 当用户输入内容并按下回车时,
query获取输入文本 - 将新消息以用户角色追加到
messages列表 - 立即在界面上显示这条用户消息
- 当用户输入内容并按下回车时,
- 数据流:
用户输入 → 存入session_state → 渲染到界面
9.5 海象运算符 #
海象运算符(Walrus Operator):= 是 Python 3.8 引入的新特性,它允许在表达式内部进行变量赋值。这与传统的赋值运算符 = 有重要区别。
9.5.1 基本语法 #
variable := expression9.5.2 特点 #
- 在表达式内完成赋值
- 返回被赋的值
- 得名由来:
:=看起来像海象的眼睛和獠牙
9.5.3 典型使用场景 #
条件判断中的赋值
# 传统方式
data = get_data()
if data:
process(data)
# 使用海象运算符
if (data := get_data()):
process(data)9.6 完整工作流程 #
首次加载:
- 初始化空消息列表
- 不显示任何历史消息(因为列表为空)
- 显示输入框等待用户提问
用户提问:
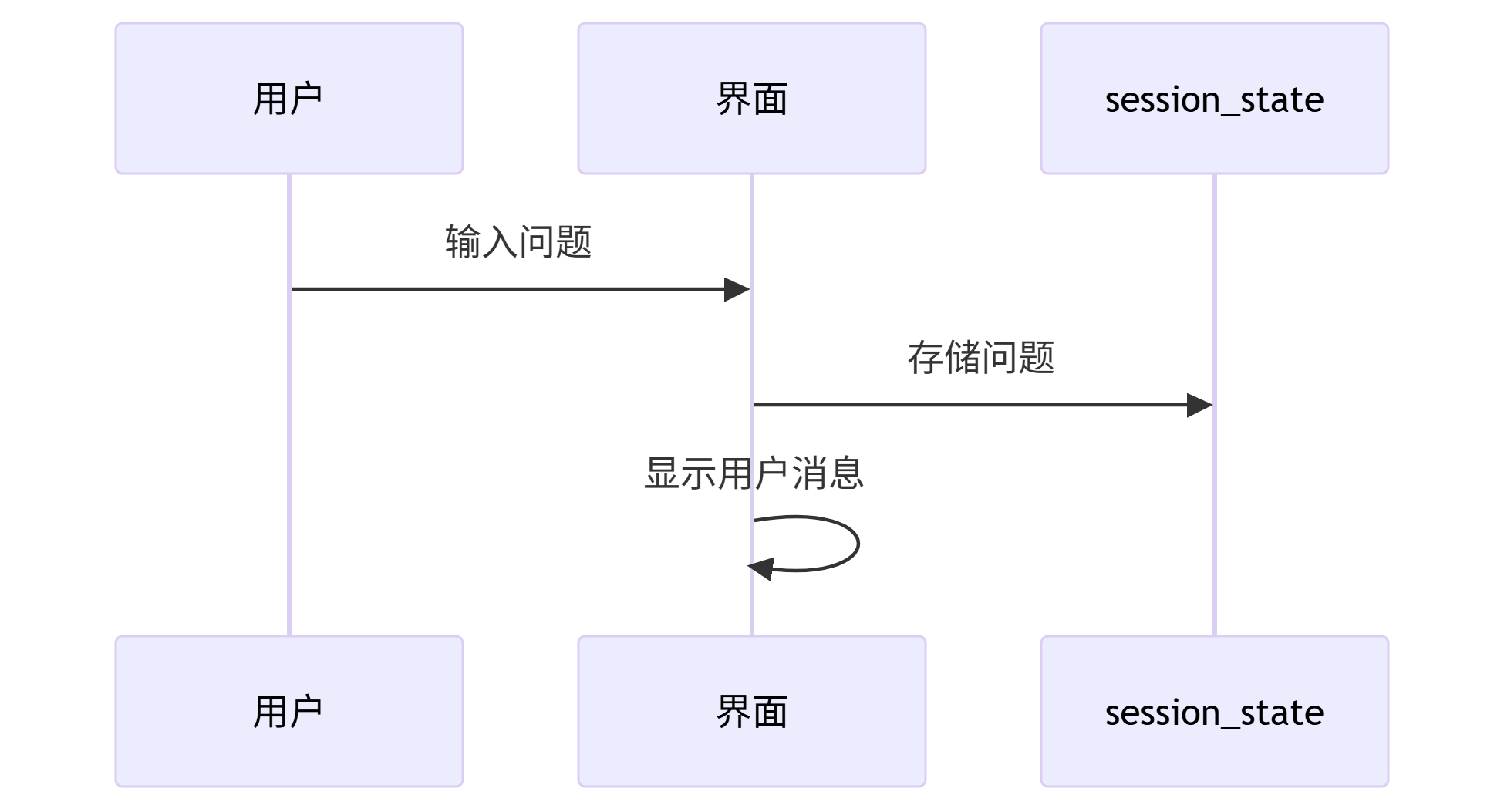
- 后续交互:
- 每次提交都会触发脚本重新运行
- 由于状态被保存,能保持完整的对话历史
10. 查询上下文 #
10.1. embedding.py #
embedding.py
# 导入requests库,用于发送HTTP请求
import requests
# 从py2neo库导入Graph类,用于连接Neo4j数据库
from py2neo import Graph
# 创建Graph对象,连接本地的Neo4j数据库,指定认证信息
graph = Graph("bolt://localhost:7687", auth=("neo4j", "12345678"))
# 定义火山方舟嵌入API的URL
VOLC_EMBEDDINGS_API_URL = "https://ark.cn-beijing.volces.com/api/v3/embeddings"
# 定义火山方舟API的密钥
VOLC_API_KEY = "d52e49a1-36ea-44bb-bc6e-65ce789a72f6"
# 定义获取文本嵌入向量的函数
def get_embedding(doc_content):
# 设置HTTP请求头,包括内容类型和授权信息
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {VOLC_API_KEY}",
}
# 构造请求体,指定模型和输入内容
payload = {"model": "doubao-embedding-text-240715", "input": doc_content}
# 发送POST请求到嵌入API
response = requests.post(VOLC_EMBEDDINGS_API_URL, json=payload, headers=headers)
# 判断请求是否成功
if response.status_code == 200:
# 解析返回的JSON数据
data = response.json()
# 提取嵌入向量
embedding = data["data"][0]["embedding"]
# 返回嵌入向量
return embedding
else:
# 如果请求失败,抛出异常并输出错误信息
raise Exception(f"Embedding API error: {response.text}")
# 定义基于嵌入向量检索图书的函数
def query_book_with_embeddings(query_embedding, top_k=3):
# 定义Cypher查询语句,调用向量索引检索图书节点
query = """
CALL db.index.vector.queryNodes('book_embeddings', $top_k, $query_embedding)
YIELD node, score
MATCH (node:Book)
OPTIONAL MATCH (node)-[:written_by]->(author:Author)
OPTIONAL MATCH (node)-[:published_by]->(publisher:Publisher)
OPTIONAL MATCH (node)-[:has_category]->(category:Category)
RETURN node.name AS name,
score AS similarity,
author.name AS 作者,
publisher.name AS 出版社,
category.name AS 类别,
node.publish_year AS 出版年份,
node.summary AS 简介,
node.keywords AS 关键词
ORDER BY score DESC
"""
# 执行Cypher查询,传入参数
results = graph.run(query, top_k=top_k, query_embedding=query_embedding)
# 初始化结果列表
books = []
# 遍历查询结果
for record in results:
# 构建图书信息字典
book_info = {
"name": record["name"],
"similarity": float(record["similarity"]),
"作者": record.get("作者"),
"出版社": record.get("出版社"),
"类别": record.get("类别"),
"出版年份": record.get("出版年份"),
"简介": record.get("简介"),
"关键词": record.get("关键词", []),
}
# 将图书信息添加到结果列表
books.append(book_info)
# 返回图书检索结果
return books
# 定义基于嵌入向量检索作者的函数
def query_author_with_embeddings(query_embedding, top_k=3):
# 定义Cypher查询语句,调用向量索引检索作者节点
query = """
CALL db.index.vector.queryNodes('author_embeddings', $top_k, $query_embedding)
YIELD node, score
MATCH (node:Author)
OPTIONAL MATCH (node)<-[:written_by]-(book:Book)
RETURN node.name AS name,
score AS similarity,
COLLECT(DISTINCT book.name) AS 相关图书
ORDER BY score DESC
"""
# 执行Cypher查询,传入参数
results = graph.run(query, top_k=top_k, query_embedding=query_embedding)
# 初始化结果列表
authors = []
# 遍历查询结果
for record in results:
# 构建作者信息字典
author_info = {
"name": record["name"],
"similarity": float(record["similarity"]),
"相关图书": record.get("相关图书", []),
}
# 将作者信息添加到结果列表
authors.append(author_info)
# 返回作者检索结果
return authors
10.2. app.py #
app.py
# 导入streamlit库,用于构建Web应用
import streamlit as st
+from embedding import (
+ get_embedding,
+ query_book_with_embeddings,
+ query_author_with_embeddings,
+)
# 定义主函数
def main():
# 设置Streamlit页面的标题和布局,必须是第一个Streamlit命令
st.set_page_config(page_title="图书知识图谱问答系统", layout="wide")
# 在侧边栏中创建一个区域,用于放置参数设置控件
with st.sidebar:
# 显示参数设置的标题,并提供悬浮提示
st.markdown("### 参数设置", help="配置查询参数")
# 创建单选框,让用户选择查询类型(图书或作者),默认选中“图书”
query_type = st.radio("选择查询类型", ["图书", "作者"], index=0)
# 创建滑块,让用户选择返回结果的数量,范围为1到10,默认值为3,步长为1
top_k = st.slider("返回结果数量 (Top K)", 1, 10, 3, 1)
# 创建滑块,让用户设置温度参数,范围为0.0到1.0,默认值为0.3,步长为0.1
temperature = st.slider("温度 (Temperature)", 0.0, 1.0, 0.3, 0.1)
# 使用markdown在页面顶部居中显示蓝色标题
st.markdown(
"<h1 style='text-align: center; color: blue;'>图书知识图谱查询系统</h1>",
unsafe_allow_html=True,
)
# 如果session_state中还没有'messages',则初始化为空列表
if "messages" not in st.session_state:
st.session_state.messages = []
# 遍历历史消息,将其逐条显示在对话框中
for message in st.session_state.messages:
st.chat_message(message["role"]).write(message["content"])
# 如果用户在输入框中输入了内容(query不为空)
if query := st.chat_input("输入图书相关问题", key="query_input"):
# 将用户输入的内容追加到消息历史中
st.session_state.messages.append({"role": "user", "content": query})
# 在对话框中显示用户刚刚输入的内容
st.chat_message("user").write(query)
# 使用Streamlit的spinner显示“正在查询中...”的加载动画
+ with st.spinner("正在查询中..."):
+ try:
# 获取用户输入问题的嵌入向量
+ query_embedding = get_embedding(query)
# 如果查询类型为“图书”
+ if query_type == "图书":
# 调用图书向量检索函数,获取相关图书结果
+ results = query_book_with_embeddings(query_embedding, top_k)
# 构建上下文字典,包含类型和结果
+ context = {"type": "图书", "results": results}
+ else:
# 否则,调用作者向量检索函数,获取相关作者结果
+ results = query_author_with_embeddings(query_embedding, top_k)
# 构建上下文字典,包含类型和结果
+ context = {"type": "作者", "results": results}
# 打印上下文信息到控制台(用于调试)
+ print(context)
+ except Exception as err:
# 如果查询过程中发生异常,构造错误信息
+ error_msg = f"查询过程中出错: {str(err)}"
# 将错误信息追加到消息历史中,角色为assistant
+ st.session_state.messages.append(
+ {"role": "assistant", "content": error_msg}
+ )
# 在对话框中显示错误信息
+ st.chat_message("assistant").write(error_msg)
# 判断当前脚本是否作为主程序运行
if __name__ == "__main__":
# 调用主函数,启动应用
main()
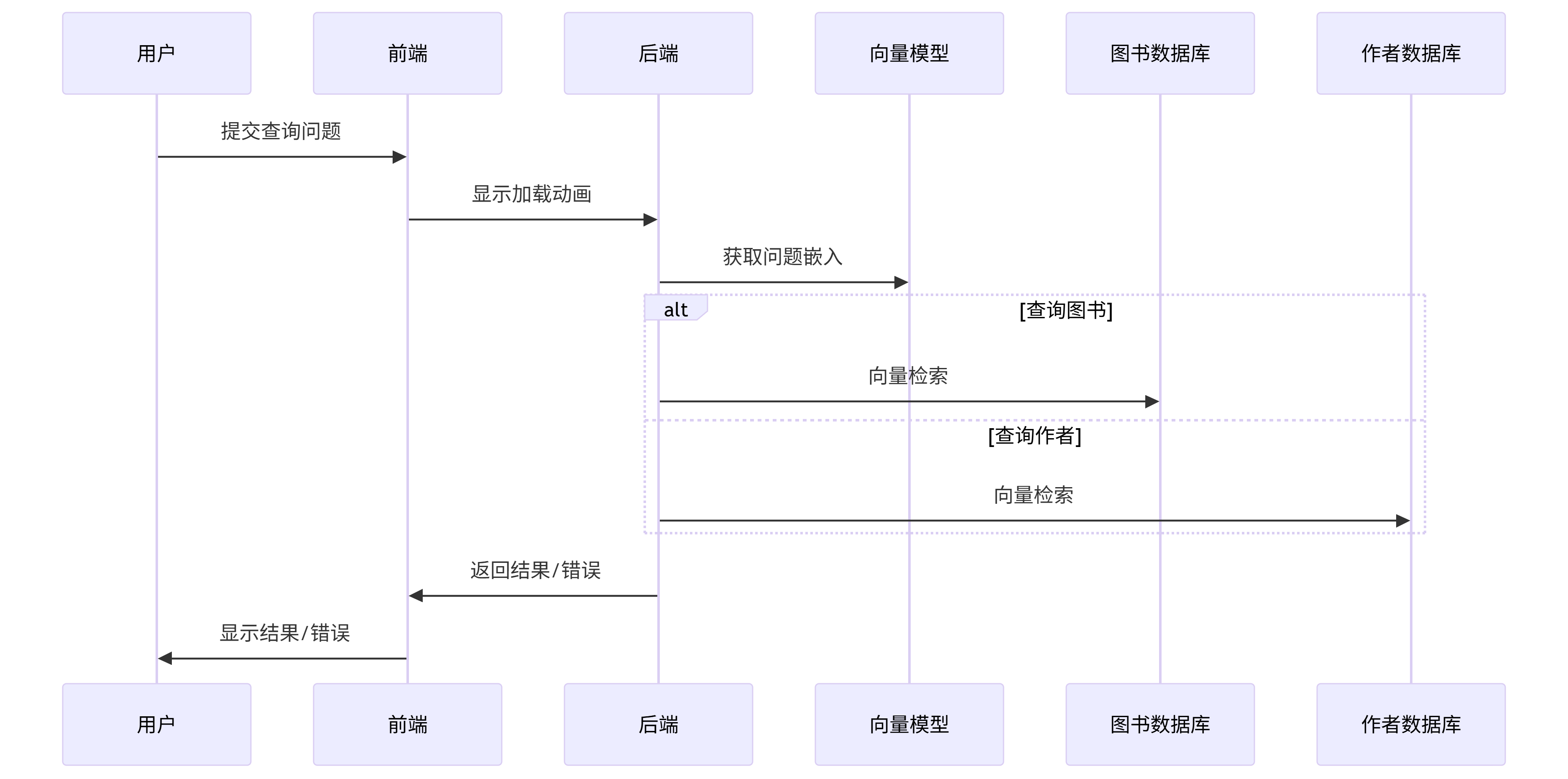
10.3 加载动画展示 #
with st.spinner("正在查询中..."):- 功能:在查询过程中显示加载动画
- 组件:
st.spinner():创建一个临时旋转动画容器- 参数
"正在查询中..."是显示的提示文本
- 特性:
- 进入
with块时自动显示加载动画 - 退出
with块时自动消失 - 如果块内代码执行时间很短,用户可能看不到动画
- 进入
10.4 核心查询逻辑 #
try:
query_embedding = get_embedding(query)
if query_type == "图书":
results = query_book_with_embeddings(query_embedding, top_k)
context = {"type": "图书", "results": results}
else:
results = query_author_with_embeddings(query_embedding, top_k)
context = {"type": "作者", "results": results}
print(context) # 调试输出工作流程:
- 获取嵌入向量:
get_embedding(query)将用户问题转换为向量表示 - 分支查询:
- 图书查询:调用
query_book_with_embeddings() - 作者查询:调用
query_author_with_embeddings()
- 图书查询:调用
- 构建上下文:将结果封装为字典,包含类型和结果集
- 调试输出:打印上下文到控制台
- 获取嵌入向量:
关键点:
- 使用向量检索实现语义搜索
top_k参数控制返回结果数量- 保持统一的返回数据结构
10.5 异常处理机制 #
except Exception as err:
error_msg = f"查询过程中出错: {str(err)}"
st.session_state.messages.append(
{"role": "assistant", "content": error_msg}
)
st.chat_message("assistant").write(error_msg)处理流程:
- 捕获所有异常并生成错误信息
- 将错误信息添加到聊天历史(角色为assistant)
- 在界面显示错误消息
设计考量:
- 使用宽泛的
Exception捕获各类错误 - 错误信息同时存储到状态和显示到界面
- 保持与正常回复相同的消息格式
- 使用宽泛的
10.6 完整执行流程 #
11.拼接上下文 #
11.1. app.py #
app.py
# 导入streamlit库,用于构建Web应用
import streamlit as st
from embedding import (
get_embedding,
query_book_with_embeddings,
query_author_with_embeddings,
)
# 定义格式化查询结果上下文的函数
+def format_context(type, results):
# 定义格式化图书信息的内部函数
+ def format_book(result):
# 构建需要显示的字段及其对应的值
+ fields = [
+ ("作者", result.get("作者")),
+ ("出版社", result.get("出版社")),
+ ("类别", result.get("类别")),
+ ("出版年份", result.get("出版年份")),
+ ("简介", result.get("简介")),
# 如果有关键词,则用逗号拼接,否则为None
+ ("关键词", ", ".join(result["关键词"]) if result.get("关键词") else None),
+ ]
# 只保留有值的字段,格式化为每行一项
+ details = "\n".join([f" - {k}: {v}" for k, v in fields if v])
# 返回格式化后的详情字符串
+ return details
# 定义格式化作者信息的内部函数
+ def format_author(result):
# 如果有相关图书,则拼接为一行显示
+ if result.get("相关图书"):
+ return f" - 相关图书: {', '.join(result['相关图书'])}"
# 否则返回空字符串
+ return ""
# 初始化结果行列表
+ lines = []
# 遍历所有结果,idx为序号(从1开始),result为每条结果
+ for idx, result in enumerate(results, 1):
# 构建每条结果的标题,包含序号、名称和相似度
+ header = f"{idx}. {result['name']} (相似度: {result['similarity']:.4f})"
# 根据类型选择不同的详情格式化方式
+ if type == "图书":
+ details = format_book(result)
+ else:
+ details = format_author(result)
# 初始化单条信息字符串
+ info = ""
# 如果有标题,则添加标题
+ if header:
+ info += f"{header}\n"
# 如果有详情,则添加详情
+ if details:
+ info += f"{details}\n"
# 将格式化后的信息添加到结果行列表
+ lines.append(info)
# 用两个换行符拼接所有结果,返回最终字符串
+ return "\n\n".join(lines)
# 定义主函数
def main():
# 设置Streamlit页面的标题和布局,必须是第一个Streamlit命令
st.set_page_config(page_title="图书知识图谱问答系统", layout="wide")
# 在侧边栏中创建一个区域,用于放置参数设置控件
with st.sidebar:
# 显示参数设置的标题,并提供悬浮提示
st.markdown("### 参数设置", help="配置查询参数")
# 创建单选框,让用户选择查询类型(图书或作者),默认选中“图书”
query_type = st.radio("选择查询类型", ["图书", "作者"], index=0)
# 创建滑块,让用户选择返回结果的数量,范围为1到10,默认值为3,步长为1
top_k = st.slider("返回结果数量 (Top K)", 1, 10, 3, 1)
# 创建滑块,让用户设置温度参数,范围为0.0到1.0,默认值为0.3,步长为0.1
temperature = st.slider("温度 (Temperature)", 0.0, 1.0, 0.3, 0.1)
# 使用markdown在页面顶部居中显示蓝色标题
st.markdown(
"<h1 style='text-align: center; color: blue;'>图书知识图谱查询系统</h1>",
unsafe_allow_html=True,
)
# 如果session_state中还没有'messages',则初始化为空列表
if "messages" not in st.session_state:
st.session_state.messages = []
# 遍历历史消息,将其逐条显示在对话框中
for message in st.session_state.messages:
st.chat_message(message["role"]).write(message["content"])
# 如果用户在输入框中输入了内容(query不为空)
if query := st.chat_input("输入图书相关问题", key="query_input"):
# 将用户输入的内容追加到消息历史中
st.session_state.messages.append({"role": "user", "content": query})
# 在对话框中显示用户刚刚输入的内容
st.chat_message("user").write(query)
# 使用Streamlit的spinner显示“正在查询中...”的加载动画
with st.spinner("正在查询中..."):
try:
# 获取用户输入问题的嵌入向量
query_embedding = get_embedding(query)
# 如果查询类型为“图书”
if query_type == "图书":
# 调用图书向量检索函数,获取相关图书结果
results = query_book_with_embeddings(query_embedding, top_k)
else:
# 否则,调用作者向量检索函数,获取相关作者结果
results = query_author_with_embeddings(query_embedding, top_k)
# 判断results是否为空,或者结果列表长度为0
+ if not results or len(results) == 0:
# 如果没有查询到相关信息,设置回复内容为提示语
+ answer = "抱歉,没有找到相关的信息。"
+ else:
# 否则,将查询结果格式化为字符串
+ context_str = format_context(query_type, results)
# 设置回复内容为格式化后的字符串
+ answer = context_str
# 将助手的回复内容追加到会话历史中
+ st.session_state.messages.append(
+ {"role": "assistant", "content": answer}
+ )
# 在对话框中显示助手的回复内容
+ st.chat_message("assistant").write(answer)
except Exception as err:
# 如果查询过程中发生异常,构造错误信息
error_msg = f"查询过程中出错: {str(err)}"
# 将错误信息追加到消息历史中,角色为assistant
st.session_state.messages.append(
{"role": "assistant", "content": error_msg}
)
# 在对话框中显示错误信息
st.chat_message("assistant").write(error_msg)
# 判断当前脚本是否作为主程序运行
if __name__ == "__main__":
# 调用主函数,启动应用
main()

12.发起查询 #
12.1. .env #
.env
NEO4J_URI="bolt://localhost:7687"
NEO4J_USER="neo4j"
NEO4J_PASSWORD="12345678"
DOUBAO_BASE_URL="https://ark.cn-beijing.volces.com/api/v3"
DOUBAO_API_KEY="d52e49a1-36ea-44bb-bc6e-65ce789a72f6"
DOUBAO_MODEL="doubao-seed-1-6-250615"12.2. config.py #
config.py
# 导入os模块,用于访问环境变量
import os
# 导入dotenv模块,用于加载.env文件中的环境变量
import dotenv
# 加载.env文件中的所有环境变量到系统环境变量中
dotenv.load_dotenv()
# 从环境变量中获取Neo4j数据库的URI
NEO4J_URI = os.environ.get("NEO4J_URI")
# 从环境变量中获取Neo4j数据库的用户名
NEO4J_USER = os.environ.get("NEO4J_USER")
# 从环境变量中获取Neo4j数据库的密码
NEO4J_PASSWORD = os.environ.get("NEO4J_PASSWORD")
# 从环境变量中获取火山豆包API的基础URL
DOUBAO_BASE_URL = os.environ.get("DOUBAO_BASE_URL")
# 从环境变量中获取火山豆包API的密钥
DOUBAO_API_KEY = os.environ.get("DOUBAO_API_KEY")
# 从环境变量中获取火山豆包大模型的名称
DOUBAO_MODEL = os.environ.get("DOUBAO_MODEL")
12.3. base.py #
llm/base.py
# 导入ABC和abstractmethod,用于定义抽象基类和抽象方法
from abc import ABC, abstractmethod
# 定义基础大语言模型(LLM)抽象基类
class BaseLLM(ABC):
# 定义抽象方法generate,要求子类必须实现
@abstractmethod
def generate(self, prompt: str, **kwargs):
# 占位语句,表示该方法需在子类中实现
pass
12.4. doubao.py #
llm/doubao.py
# 从当前包导入基础大语言模型抽象基类
from .base import BaseLLM
# 导入OpenAI库,用于调用大模型API
from openai import OpenAI
# 从配置文件导入火山豆包API密钥、基础URL和模型名称
from config import DOUBAO_API_KEY, DOUBAO_BASE_URL, DOUBAO_MODEL
# 定义豆包大语言模型类,继承自BaseLLM
class DoubaoLLM(BaseLLM):
# 初始化方法
def __init__(self):
# 创建OpenAI客户端,指定基础URL和API密钥
self.client = OpenAI(base_url=DOUBAO_BASE_URL, api_key=DOUBAO_API_KEY)
# 实现generate方法,用于生成模型回复
def generate(self, prompt, **kwargs):
# 调用OpenAI的chat.completions.create方法生成回复
resp = self.client.chat.completions.create(
# 指定使用的模型名称
model=DOUBAO_MODEL,
# 构造对话消息列表,用户输入为prompt
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt,
},
],
}
],
# 设置温度参数,默认为0.3
temperature=kwargs.get("temperature", 0.3),
# 设置最大token数,默认为4096
max_tokens=kwargs.get("max_tokens", 4096),
)
# 返回模型生成的回复内容
return resp.choices[0].message.content
12.5. app.py #
app.py
# 导入streamlit库,用于构建Web应用
import streamlit as st
+from langchain.prompts import PromptTemplate
from embedding import (
get_embedding,
query_book_with_embeddings,
query_author_with_embeddings,
)
# 从llm.doubao模块导入DoubaoLLM类
+from llm.doubao import DoubaoLLM
# 实例化豆包大语言模型对象
+llm = DoubaoLLM()
# 定义格式化查询结果上下文的函数
def format_context(type, results):
# 定义格式化图书信息的内部函数
def format_book(result):
# 构建需要显示的字段及其对应的值
fields = [
("作者", result.get("作者")),
("出版社", result.get("出版社")),
("类别", result.get("类别")),
("出版年份", result.get("出版年份")),
("简介", result.get("简介")),
# 如果有关键词,则用逗号拼接,否则为None
("关键词", ", ".join(result["关键词"]) if result.get("关键词") else None),
]
# 只保留有值的字段,格式化为每行一项
details = "\n".join([f" - {k}: {v}" for k, v in fields if v])
# 返回格式化后的详情字符串
return details
# 定义格式化作者信息的内部函数
def format_author(result):
# 如果有相关图书,则拼接为一行显示
if result.get("相关图书"):
return f" - 相关图书: {', '.join(result['相关图书'])}"
# 否则返回空字符串
return ""
# 初始化结果行列表
lines = []
# 遍历所有结果,idx为序号(从1开始),result为每条结果
for idx, result in enumerate(results, 1):
# 构建每条结果的标题,包含序号、名称和相似度
header = f"{idx}. {result['name']} (相似度: {result['similarity']:.4f})"
# 根据类型选择不同的详情格式化方式
if type == "图书":
details = format_book(result)
else:
details = format_author(result)
# 初始化单条信息字符串
info = ""
# 如果有标题,则添加标题
if header:
info += f"{header}\n"
# 如果有详情,则添加详情
if details:
info += f"{details}\n"
# 将格式化后的信息添加到结果行列表
lines.append(info)
# 用两个换行符拼接所有结果,返回最终字符串
return "\n\n".join(lines)
+prompt_template = PromptTemplate(
+ input_variables=["question", "context"],
+ template="""你是一名图书知识助手,需要根据提供的图书信息回答用户的提问。
+ 请直接回答问题,如果信息不足,请回答\"根据现有信息无法确定\"。
+ 问题:{question}
+ 图书信息:\n{context}
+ 回答:""",
+)
# 定义主函数
def main():
# 设置Streamlit页面的标题和布局,必须是第一个Streamlit命令
st.set_page_config(page_title="图书知识图谱问答系统", layout="wide")
# 在侧边栏中创建一个区域,用于放置参数设置控件
with st.sidebar:
# 显示参数设置的标题,并提供悬浮提示
st.markdown("### 参数设置", help="配置查询参数")
# 创建单选框,让用户选择查询类型(图书或作者),默认选中“图书”
query_type = st.radio("选择查询类型", ["图书", "作者"], index=0)
# 创建滑块,让用户选择返回结果的数量,范围为1到10,默认值为3,步长为1
top_k = st.slider("返回结果数量 (Top K)", 1, 10, 3, 1)
# 创建滑块,让用户设置温度参数,范围为0.0到1.0,默认值为0.3,步长为0.1
temperature = st.slider("温度 (Temperature)", 0.0, 1.0, 0.3, 0.1)
# 使用markdown在页面顶部居中显示蓝色标题
st.markdown(
"<h1 style='text-align: center; color: blue;'>图书知识图谱查询系统</h1>",
unsafe_allow_html=True,
)
# 如果session_state中还没有'messages',则初始化为空列表
if "messages" not in st.session_state:
st.session_state.messages = []
# 遍历历史消息,将其逐条显示在对话框中
for message in st.session_state.messages:
st.chat_message(message["role"]).write(message["content"])
# 如果用户在输入框中输入了内容(query不为空)
if query := st.chat_input("输入图书相关问题", key="query_input"):
# 将用户输入的内容追加到消息历史中
st.session_state.messages.append({"role": "user", "content": query})
# 在对话框中显示用户刚刚输入的内容
st.chat_message("user").write(query)
# 使用Streamlit的spinner显示“正在查询中...”的加载动画
with st.spinner("正在查询中..."):
try:
# 获取用户输入问题的嵌入向量
query_embedding = get_embedding(query)
# 如果查询类型为“图书”
if query_type == "图书":
# 调用图书向量检索函数,获取相关图书结果
results = query_book_with_embeddings(query_embedding, top_k)
else:
# 否则,调用作者向量检索函数,获取相关作者结果
results = query_author_with_embeddings(query_embedding, top_k)
# 判断results是否为空,或者结果列表长度为0
if not results or len(results) == 0:
# 如果没有查询到相关信息,设置回复内容为提示语
answer = "抱歉,没有找到相关的信息。"
else:
# 否则,将查询结果格式化为字符串
+ context = format_context(query_type, results)
# 使用prompt模板,将用户问题和上下文插入,生成最终的prompt
+ final_prompt = prompt_template.format(
+ question=query, context=context
+ )
# 调用大语言模型生成答案,传入温度参数
+ answer = llm.generate(final_prompt, temperature=temperature)
# 将助手的回复内容追加到会话历史中
+ st.session_state.messages.append(
+ {"role": "assistant", "content": answer}
+ )
# 在对话框中显示助手的回复内容
+ st.chat_message("assistant").write(answer)
except Exception as err:
# 如果查询过程中发生异常,构造错误信息
error_msg = f"查询过程中出错: {str(err)}"
# 将错误信息追加到消息历史中,角色为assistant
st.session_state.messages.append(
{"role": "assistant", "content": error_msg}
)
# 在对话框中显示错误信息
st.chat_message("assistant").write(error_msg)
# 判断当前脚本是否作为主程序运行
if __name__ == "__main__":
# 调用主函数,启动应用
main()
13.历史记录 #
13.1. app.py #
app.py
# 导入streamlit库,用于构建Web应用
import streamlit as st
from langchain.prompts import PromptTemplate
from embedding import (
get_embedding,
query_book_with_embeddings,
query_author_with_embeddings,
)
# 从llm.doubao模块导入DoubaoLLM类
from llm.doubao import DoubaoLLM
# 实例化豆包大语言模型对象
llm = DoubaoLLM()
# 定义格式化查询结果上下文的函数
def format_context(type, results):
# 定义格式化图书信息的内部函数
def format_book(result):
# 构建需要显示的字段及其对应的值
fields = [
("作者", result.get("作者")),
("出版社", result.get("出版社")),
("类别", result.get("类别")),
("出版年份", result.get("出版年份")),
("简介", result.get("简介")),
# 如果有关键词,则用逗号拼接,否则为None
("关键词", ", ".join(result["关键词"]) if result.get("关键词") else None),
]
# 只保留有值的字段,格式化为每行一项
details = "\n".join([f" - {k}: {v}" for k, v in fields if v])
# 返回格式化后的详情字符串
return details
# 定义格式化作者信息的内部函数
def format_author(result):
# 如果有相关图书,则拼接为一行显示
if result.get("相关图书"):
return f" - 相关图书: {', '.join(result['相关图书'])}"
# 否则返回空字符串
return ""
# 初始化结果行列表
lines = []
# 遍历所有结果,idx为序号(从1开始),result为每条结果
for idx, result in enumerate(results, 1):
# 构建每条结果的标题,包含序号、名称和相似度
header = f"{idx}. {result['name']} (相似度: {result['similarity']:.4f})"
# 根据类型选择不同的详情格式化方式
if type == "图书":
details = format_book(result)
else:
details = format_author(result)
# 初始化单条信息字符串
info = ""
# 如果有标题,则添加标题
if header:
info += f"{header}\n"
# 如果有详情,则添加详情
if details:
info += f"{details}\n"
# 将格式化后的信息添加到结果行列表
lines.append(info)
# 用两个换行符拼接所有结果,返回最终字符串
return "\n\n".join(lines)
prompt_template = PromptTemplate(
input_variables=["question", "context"],
template="""你是一名图书知识助手,需要根据提供的图书信息回答用户的提问。
请直接回答问题,如果信息不足,请回答\"根据现有信息无法确定\"。
问题:{question}
图书信息:\n{context}
回答:""",
)
# 定义主函数
def main():
# 设置Streamlit页面的标题和布局,必须是第一个Streamlit命令
st.set_page_config(page_title="图书知识图谱问答系统", layout="wide")
+ if "history" not in st.session_state:
+ st.session_state.history = []
# 在侧边栏中创建一个区域,用于放置参数设置控件
with st.sidebar:
# 显示参数设置的标题,并提供悬浮提示
st.markdown("### 参数设置", help="配置查询参数")
# 创建单选框,让用户选择查询类型(图书或作者),默认选中“图书”
query_type = st.radio("选择查询类型", ["图书", "作者"], index=0)
# 创建滑块,让用户选择返回结果的数量,范围为1到10,默认值为3,步长为1
top_k = st.slider("返回结果数量 (Top K)", 1, 10, 3, 1)
# 创建滑块,让用户设置温度参数,范围为0.0到1.0,默认值为0.3,步长为0.1
temperature = st.slider("温度 (Temperature)", 0.0, 1.0, 0.3, 0.1)
+ st.markdown("### 历史查询")
+ if st.session_state.history:
+ for i, item in enumerate(st.session_state.history):
+ with st.expander(f"查询 {i+1}: {item['question']}"):
+ st.json(item)
+ else:
+ st.info("暂无历史查询记录")
# 使用markdown在页面顶部居中显示蓝色标题
st.markdown(
"<h1 style='text-align: center; color: blue;'>图书知识图谱查询系统</h1>",
unsafe_allow_html=True,
)
# 如果session_state中还没有'messages',则初始化为空列表
if "messages" not in st.session_state:
st.session_state.messages = []
# 遍历历史消息,将其逐条显示在对话框中
for message in st.session_state.messages:
st.chat_message(message["role"]).write(message["content"])
# 如果用户在输入框中输入了内容(query不为空)
if query := st.chat_input("输入图书相关问题", key="query_input"):
# 将用户输入的内容追加到消息历史中
st.session_state.messages.append({"role": "user", "content": query})
# 在对话框中显示用户刚刚输入的内容
st.chat_message("user").write(query)
# 使用Streamlit的spinner显示“正在查询中...”的加载动画
with st.spinner("正在查询中..."):
try:
# 获取用户输入问题的嵌入向量
query_embedding = get_embedding(query)
# 如果查询类型为“图书”
if query_type == "图书":
# 调用图书向量检索函数,获取相关图书结果
results = query_book_with_embeddings(query_embedding, top_k)
else:
# 否则,调用作者向量检索函数,获取相关作者结果
results = query_author_with_embeddings(query_embedding, top_k)
# 判断results是否为空,或者结果列表长度为0
if not results or len(results) == 0:
# 如果没有查询到相关信息,设置回复内容为提示语
answer = "抱歉,没有找到相关的信息。"
else:
# 否则,将查询结果格式化为字符串
context = format_context(query_type, results)
# 使用prompt模板,将用户问题和上下文插入,生成最终的prompt
final_prompt = prompt_template.format(
question=query, context=context
)
# 调用大语言模型生成答案,传入温度参数
answer = llm.generate(final_prompt, temperature=temperature)
# 将查询结果添加到历史记录中
+ st.session_state.history.append(
+ {
+ "question": query,
+ "query_type": query_type,
+ "context": context,
+ "answer": answer,
+ "temperature": temperature,
+ }
+ )
# 在对话框中显示查询结果
+ with st.expander("查看详细结果"):
+ st.json({"type": query_type, "results": results})
# 将助手的回复内容追加到会话历史中
st.session_state.messages.append(
{"role": "assistant", "content": answer}
)
# 在对话框中显示助手的回复内容
st.chat_message("assistant").write(answer)
+ st.rerun()
except Exception as err:
# 如果查询过程中发生异常,构造错误信息
error_msg = f"查询过程中出错: {str(err)}"
# 将错误信息追加到消息历史中,角色为assistant
st.session_state.messages.append(
{"role": "assistant", "content": error_msg}
)
# 在对话框中显示错误信息
st.chat_message("assistant").write(error_msg)
# 判断当前脚本是否作为主程序运行
if __name__ == "__main__":
# 调用主函数,启动应用
main()
13.2 rerun #
st.rerun() 是 Streamlit 提供的一个重要函数,用于强制重新运行当前应用程序的整个脚本
13.2.1 基本功能 #
- 作用:立即触发整个 Streamlit 应用的重新执行
- 效果:
- 从脚本顶部开始重新执行所有代码
- 保持当前 URL 参数不变
- 保留
st.session_state中的内容(除非手动清除)
13.2.2 典型使用场景 #
13.2.2.1 响应式更新界面 #
import streamlit as st
if st.button("刷新数据"):
st.rerun() # 点击按钮后重新加载13.2.2.2 程序化重置应用状态 #
def reset_app():
st.session_state.clear() # 清除所有会话状态
st.rerun() # 重新运行应用
st.button("重置应用", on_click=reset_app)13.2.2.3 配合回调函数使用 #
def on_select():
st.session_state.selected = st.session_state.selector
st.rerun()
st.selectbox(
"选择项目",
options=["A", "B", "C"],
key="selector",
on_change=on_select
)13.2.3 工作原理 #
- 执行流程:
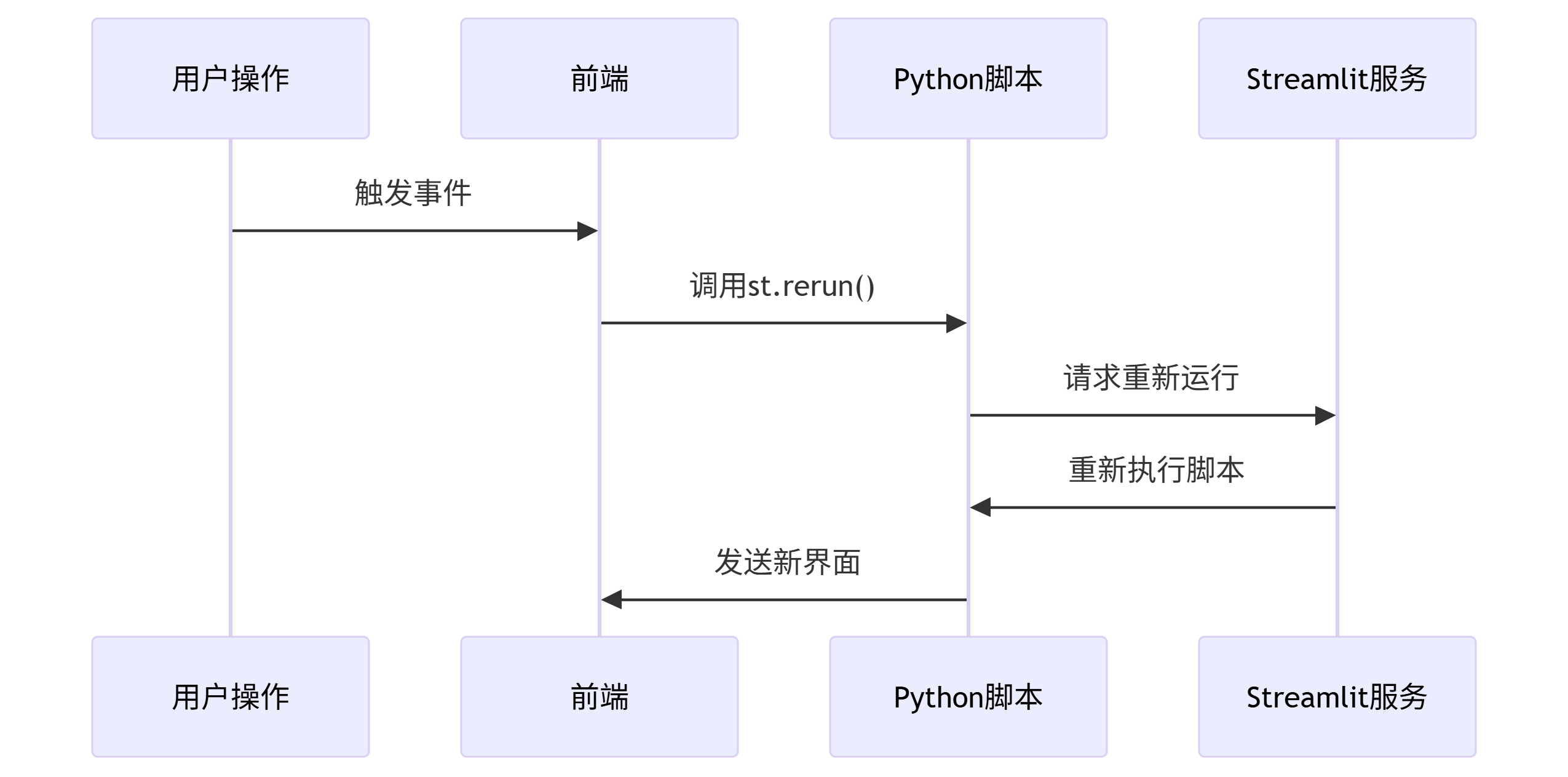
- 与自然重运行的区别:
- 普通热更新:仅在代码文件修改时触发
st.rerun():可以程序化控制触发时机
14.模型选择 #
14.1. deepseek.py #
llm/deepseek.py
# 从当前包导入基础大语言模型抽象基类
from .base import BaseLLM
# 导入OpenAI库,用于调用大模型API
from openai import OpenAI
# 从配置文件导入DeepSeekAPI密钥、基础URL和模型名称
from config import DEEPSEEK_API_KEY, DEEPSEEK_BASE_URL, DEEPSEEK_MODEL
# 定义DeepSeek大语言模型类,继承自BaseLLM
class DeepSeekLLM(BaseLLM):
# 初始化方法
def __init__(self, api_key=None, model_name=None):
# 创建OpenAI客户端,指定基础URL和API密钥
self.client = OpenAI(
base_url=DEEPSEEK_BASE_URL,
api_key=api_key or DEEPSEEK_API_KEY,
)
self.model_name = model_name or DEEPSEEK_MODEL
# 实现generate方法,用于生成模型回复
def generate(self, prompt, **kwargs):
# 调用OpenAI的chat.completions.create方法生成回复
resp = self.client.chat.completions.create(
# 指定使用的模型名称
model=self.model_name,
# 构造对话消息列表,用户输入为prompt
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt,
},
],
}
],
# 设置温度参数,默认为0.3
temperature=kwargs.get("temperature", 0.3),
# 设置最大token数,默认为4096
max_tokens=kwargs.get("max_tokens", 4096),
)
# 返回模型生成的回复内容
return resp.choices[0].message.content
14.2. .env #
.env
NEO4J_URI="bolt://localhost:7687"
NEO4J_USER="neo4j"
NEO4J_PASSWORD="12345678"
DOUBAO_BASE_URL="https://ark.cn-beijing.volces.com/api/v3"
DOUBAO_API_KEY="d52e49a1-36ea-44bb-bc6e-65ce789a72f6"
+DOUBAO_MODEL="doubao-seed-1-6-250615"
+DeepSeek_BASE_URL="https://api.deepseek.com/v1"
+DeepSeek_API_KEY="sk-278496d471bc4f4cb0ccb8c389a15018"
+DeepSeek_MODEL="deepseek-chat"14.3. app.py #
app.py
# 导入streamlit库,用于构建Web应用
import streamlit as st
from langchain.prompts import PromptTemplate
from embedding import (
get_embedding,
query_book_with_embeddings,
query_author_with_embeddings,
)
# 从llm.doubao模块导入DoubaoLLM类
from llm.doubao import DoubaoLLM
+from llm.deepseek import DeepSeekLLM
+from config import DEEPSEEK_API_KEY, DEEPSEEK_MODEL, DOUBAO_API_KEY, DOUBAO_MODEL
# 定义格式化查询结果上下文的函数
def format_context(type, results):
# 定义格式化图书信息的内部函数
def format_book(result):
# 构建需要显示的字段及其对应的值
fields = [
("作者", result.get("作者")),
("出版社", result.get("出版社")),
("类别", result.get("类别")),
("出版年份", result.get("出版年份")),
("简介", result.get("简介")),
# 如果有关键词,则用逗号拼接,否则为None
("关键词", ", ".join(result["关键词"]) if result.get("关键词") else None),
]
# 只保留有值的字段,格式化为每行一项
details = "\n".join([f" - {k}: {v}" for k, v in fields if v])
# 返回格式化后的详情字符串
return details
# 定义格式化作者信息的内部函数
def format_author(result):
# 如果有相关图书,则拼接为一行显示
if result.get("相关图书"):
return f" - 相关图书: {', '.join(result['相关图书'])}"
# 否则返回空字符串
return ""
# 初始化结果行列表
lines = []
# 遍历所有结果,idx为序号(从1开始),result为每条结果
for idx, result in enumerate(results, 1):
# 构建每条结果的标题,包含序号、名称和相似度
header = f"{idx}. {result['name']} (相似度: {result['similarity']:.4f})"
# 根据类型选择不同的详情格式化方式
if type == "图书":
details = format_book(result)
else:
details = format_author(result)
# 初始化单条信息字符串
info = ""
# 如果有标题,则添加标题
if header:
info += f"{header}\n"
# 如果有详情,则添加详情
if details:
info += f"{details}\n"
# 将格式化后的信息添加到结果行列表
lines.append(info)
# 用两个换行符拼接所有结果,返回最终字符串
return "\n\n".join(lines)
prompt_template = PromptTemplate(
input_variables=["question", "context"],
template="""你是一名图书知识助手,需要根据提供的图书信息回答用户的提问。
请直接回答问题,如果信息不足,请回答\"根据现有信息无法确定\"。
问题:{question}
图书信息:\n{context}
回答:""",
)
# 定义主函数
def main():
# 设置Streamlit页面的标题和布局,必须是第一个Streamlit命令
st.set_page_config(page_title="图书知识图谱问答系统", layout="wide")
if "history" not in st.session_state:
st.session_state.history = []
# 在侧边栏中创建一个区域,用于放置参数设置控件
with st.sidebar:
# 显示参数设置的标题,并提供悬浮提示
st.markdown("### 参数设置", help="配置查询参数")
# 创建单选框,让用户选择查询类型(图书或作者),默认选中“图书”
query_type = st.radio("选择查询类型", ["图书", "作者"], index=0)
# 创建滑块,让用户选择返回结果的数量,范围为1到10,默认值为3,步长为1
top_k = st.slider("返回结果数量 (Top K)", 1, 10, 3, 1)
# 创建滑块,让用户设置温度参数,范围为0.0到1.0,默认值为0.3,步长为0.1
temperature = st.slider("温度 (Temperature)", 0.0, 1.0, 0.3, 0.1)
# LLM服务商选择
+ llm_provider = st.selectbox("选择大模型服务商", ["doubao", "deepseek"], index=0)
# API Key输入
+ if llm_provider == "doubao":
+ api_key = st.text_input(
+ "doubao API Key",
+ value=DOUBAO_API_KEY,
+ type="password",
+ help="如留空则使用服务器默认配置",
+ )
+ model_name = st.text_input(
+ "doubao模型名", value=DOUBAO_MODEL, help="如留空则使用服务器默认配置"
+ )
+ else:
+ api_key = st.text_input(
+ "DeepSeek API Key",
+ value=DEEPSEEK_API_KEY,
+ type="password",
+ help="如留空则使用服务器默认配置",
+ )
+ model_name = st.text_input(
+ "DeepSeek模型名",
+ value=DEEPSEEK_MODEL,
+ help="如留空则使用服务器默认配置",
+ )
st.markdown("### 历史查询")
if st.session_state.history:
for i, item in enumerate(st.session_state.history):
with st.expander(f"查询 {i+1}: {item['question']}"):
st.json(item)
else:
st.info("暂无历史查询记录")
# 使用markdown在页面顶部居中显示蓝色标题
st.markdown(
"<h1 style='text-align: center; color: blue;'>图书知识图谱查询系统</h1>",
unsafe_allow_html=True,
)
# 如果session_state中还没有'messages',则初始化为空列表
if "messages" not in st.session_state:
st.session_state.messages = []
# 遍历历史消息,将其逐条显示在对话框中
for message in st.session_state.messages:
st.chat_message(message["role"]).write(message["content"])
# 如果用户在输入框中输入了内容(query不为空)
if query := st.chat_input("输入图书相关问题", key="query_input"):
# 将用户输入的内容追加到消息历史中
st.session_state.messages.append({"role": "user", "content": query})
# 在对话框中显示用户刚刚输入的内容
st.chat_message("user").write(query)
# 使用Streamlit的spinner显示“正在查询中...”的加载动画
with st.spinner("正在查询中..."):
try:
# 获取用户输入问题的嵌入向量
query_embedding = get_embedding(query)
# 动态实例化llm对象
+ if llm_provider == "doubao":
+ llm = DoubaoLLM(api_key=api_key, model_name=model_name)
+ else:
+ llm = DeepSeekLLM(
+ api_key=api_key,
+ model_name=model_name,
+ )
# 如果查询类型为“图书”
if query_type == "图书":
# 调用图书向量检索函数,获取相关图书结果
results = query_book_with_embeddings(query_embedding, top_k)
else:
# 否则,调用作者向量检索函数,获取相关作者结果
results = query_author_with_embeddings(query_embedding, top_k)
# 判断results是否为空,或者结果列表长度为0
if not results or len(results) == 0:
# 如果没有查询到相关信息,设置回复内容为提示语
answer = "抱歉,没有找到相关的信息。"
else:
# 否则,将查询结果格式化为字符串
context = format_context(query_type, results)
# 使用prompt模板,将用户问题和上下文插入,生成最终的prompt
final_prompt = prompt_template.format(
question=query, context=context
)
# 调用大语言模型生成答案,传入温度参数
answer = llm.generate(final_prompt, temperature=temperature)
# 将查询结果添加到历史记录中
st.session_state.history.append(
{
"question": query,
"query_type": query_type,
"context": context,
"answer": answer,
"temperature": temperature,
}
)
# 在对话框中显示查询结果
with st.expander("查看详细结果"):
st.json({"type": query_type, "results": results})
# 将助手的回复内容追加到会话历史中
st.session_state.messages.append(
{"role": "assistant", "content": answer}
)
# 在对话框中显示助手的回复内容
st.chat_message("assistant").write(answer)
st.rerun()
except Exception as err:
# 如果查询过程中发生异常,构造错误信息
error_msg = f"查询过程中出错: {str(err)}"
# 将错误信息追加到消息历史中,角色为assistant
st.session_state.messages.append(
{"role": "assistant", "content": error_msg}
)
# 在对话框中显示错误信息
st.chat_message("assistant").write(error_msg)
# 判断当前脚本是否作为主程序运行
if __name__ == "__main__":
# 调用主函数,启动应用
main()
14.4. config.py #
config.py
# 导入os模块,用于访问环境变量
import os
# 导入dotenv模块,用于加载.env文件中的环境变量
import dotenv
# 加载.env文件中的所有环境变量到系统环境变量中
dotenv.load_dotenv()
# 从环境变量中获取Neo4j数据库的URI
NEO4J_URI = os.environ.get("NEO4J_URI")
# 从环境变量中获取Neo4j数据库的用户名
NEO4J_USER = os.environ.get("NEO4J_USER")
# 从环境变量中获取Neo4j数据库的密码
NEO4J_PASSWORD = os.environ.get("NEO4J_PASSWORD")
# 从环境变量中获取火山豆包API的基础URL
DOUBAO_BASE_URL = os.environ.get("DOUBAO_BASE_URL")
# 从环境变量中获取火山豆包API的密钥
DOUBAO_API_KEY = os.environ.get("DOUBAO_API_KEY")
# 从环境变量中获取火山豆包大模型的名称
+DOUBAO_MODEL = os.environ.get("DOUBAO_MODEL")
# 从环境变量中获取DeepSeek API的基础URL
+DEEPSEEK_BASE_URL = os.environ.get("DEEPSEEK_BASE_URL", "https://api.deepseek.com")
# 从环境变量中获取DeepSeek API的密钥
+DEEPSEEK_API_KEY = os.environ.get("DEEPSEEK_API_KEY", "")
# 从环境变量中获取DeepSeek模型的名称
+DEEPSEEK_MODEL = os.environ.get("DEEPSEEK_MODEL", "deepseek-chat")
14.5. embedding.py #
embedding.py
# 导入requests库,用于发送HTTP请求
import requests
# 从py2neo库导入Graph类,用于连接Neo4j数据库
from py2neo import Graph
# 创建Graph对象,连接本地的Neo4j数据库,指定认证信息
graph = Graph("bolt://localhost:7687", auth=("neo4j", "12345678"))
# 定义火山方舟嵌入API的URL
VOLC_EMBEDDINGS_API_URL = "https://ark.cn-beijing.volces.com/api/v3/embeddings"
# 定义火山方舟API的密钥
VOLC_API_KEY = "d52e49a1-36ea-44bb-bc6e-65ce789a72f6"
# 定义获取文本嵌入向量的函数
def get_embedding(doc_content):
# 设置HTTP请求头,包括内容类型和授权信息
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {VOLC_API_KEY}",
}
# 构造请求体,指定模型和输入内容
payload = {"model": "doubao-embedding-text-240715", "input": doc_content}
# 发送POST请求到嵌入API
response = requests.post(VOLC_EMBEDDINGS_API_URL, json=payload, headers=headers)
# 判断请求是否成功
if response.status_code == 200:
# 解析返回的JSON数据
data = response.json()
# 提取嵌入向量
embedding = data["data"][0]["embedding"]
# 返回嵌入向量
return embedding
else:
# 如果请求失败,抛出异常并输出错误信息
raise Exception(f"Embedding API error: {response.text}")
# 定义基于嵌入向量检索图书的函数
def query_book_with_embeddings(query_embedding, top_k=3):
# 定义Cypher查询语句,调用向量索引检索图书节点
query = """
CALL db.index.vector.queryNodes('book_embeddings', $top_k, $query_embedding)
YIELD node, score
MATCH (node:Book)
OPTIONAL MATCH (node)-[:written_by]->(author:Author)
OPTIONAL MATCH (node)-[:published_by]->(publisher:Publisher)
OPTIONAL MATCH (node)-[:has_category]->(category:Category)
RETURN node.name AS name,
score AS similarity,
author.name AS 作者,
publisher.name AS 出版社,
category.name AS 类别,
node.publish_year AS 出版年份,
node.summary AS 简介,
node.keywords AS 关键词
ORDER BY score DESC
"""
# 执行Cypher查询,传入参数
results = graph.run(query, top_k=top_k, query_embedding=query_embedding)
# 初始化结果列表
books = []
# 遍历查询结果
for record in results:
# 构建图书信息字典
book_info = {
"name": record["name"],
"similarity": float(record["similarity"]),
"作者": record.get("作者"),
"出版社": record.get("出版社"),
"类别": record.get("类别"),
"出版年份": record.get("出版年份"),
"简介": record.get("简介"),
"关键词": record.get("关键词", []),
}
# 将图书信息添加到结果列表
books.append(book_info)
# 返回图书检索结果
return books
# 定义基于嵌入向量检索作者的函数
def query_author_with_embeddings(query_embedding, top_k=3):
# 定义Cypher查询语句,调用向量索引检索作者节点
query = """
CALL db.index.vector.queryNodes('author_embeddings', $top_k, $query_embedding)
YIELD node, score
MATCH (node:Author)
OPTIONAL MATCH (node)<-[:written_by]-(book:Book)
RETURN node.name AS name,
score AS similarity,
COLLECT(DISTINCT book.name) AS 相关图书
ORDER BY score DESC
"""
# 执行Cypher查询,传入参数
results = graph.run(query, top_k=top_k, query_embedding=query_embedding)
+ print(results)
# 初始化结果列表
authors = []
# 遍历查询结果
for record in results:
# 构建作者信息字典
author_info = {
"name": record["name"],
"similarity": float(record["similarity"]),
"相关图书": record.get("相关图书", []),
}
# 将作者信息添加到结果列表
authors.append(author_info)
# 返回作者检索结果
return authors
14.6. doubao.py #
llm/doubao.py
# 从当前包导入基础大语言模型抽象基类
from .base import BaseLLM
# 导入OpenAI库,用于调用大模型API
from openai import OpenAI
# 从配置文件导入火山豆包API密钥、基础URL和模型名称
+from config import DOUBAO_API_KEY, DOUBAO_BASE_URL, DOUBAO_MODEL
# 定义豆包大语言模型类,继承自BaseLLM
class DoubaoLLM(BaseLLM):
# 初始化方法
+ def __init__(self, api_key=None, model_name=None):
# 创建OpenAI客户端,指定基础URL和API密钥
+ self.client = OpenAI(
+ base_url=DOUBAO_BASE_URL,
+ api_key=api_key or DOUBAO_API_KEY,
+ )
+ self.model_name = model_name or DOUBAO_MODEL
# 实现generate方法,用于生成模型回复
def generate(self, prompt, **kwargs):
# 调用OpenAI的chat.completions.create方法生成回复
resp = self.client.chat.completions.create(
# 指定使用的模型名称
+ model=self.model_name,
# 构造对话消息列表,用户输入为prompt
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt,
},
],
}
],
# 设置温度参数,默认为0.3
temperature=kwargs.get("temperature", 0.3),
# 设置最大token数,默认为4096
max_tokens=kwargs.get("max_tokens", 4096),
)
# 返回模型生成的回复内容
return resp.choices[0].message.content