1. 联网问答 #
1.1 安装 #
pip install markdownify
pip install beautifulsoup4
pip install requests
pip install strsimpy1.2 流程 #
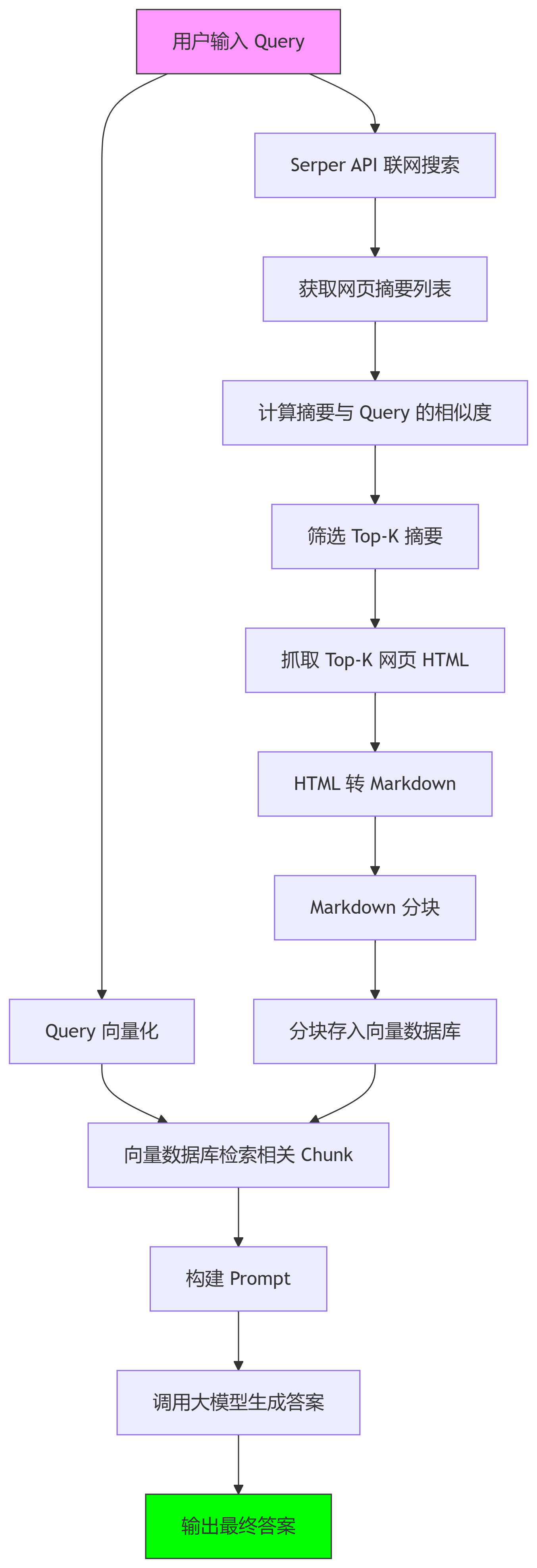
流程步骤解析
用户输入 Query
- 用户提交问题或搜索请求。
Serper API 联网搜索
- 调用搜索引擎 API(如 Google Serper)获取相关网页列表。
获取网页摘要列表
- 提取搜索结果的标题、URL 和摘要片段。
计算摘要与 Query 的相似度
- 计算摘要与用户 Query 的相关性。
筛选 Top-K 摘要
- 选择相似度最高的
K个网页摘要。
- 选择相似度最高的
抓取 Top-K 网页 HTML
- 下载对应网页的完整 HTML 内容。
HTML 转 Markdown
- 使用工具(如
markdownify)清理 HTML 并转换为 Markdown 格式。
- 使用工具(如
Markdown 分块
- 按段落或固定长度将 Markdown 切分为多个 Chunk(便于向量化)。
分块存入向量数据库
- 将分块后的文本通过 Embedding 模型(如 OpenAI Embeddings)向量化,并存储到向量数据库(如 Pinecone、Milvus)。
Query 向量化
- 将用户 Query 转换为向量,用于检索。
向量数据库检索相关 Chunk
- 从向量数据库中查找与 Query 向量最相似的文本块。
构建 Prompt
- 将检索到的 Chunk 和用户 Query 组合成大模型(如 GPT-4)的输入 Prompt。
调用大模型生成答案
- 大模型基于 Prompt 生成结构化答案。
输出最终答案
- 返回答案给用户。
1.3 代码 #
# 导入sentence_transformers库中的SentenceTransformer类
from sentence_transformers import SentenceTransformer
# 导入chromadb库
import chromadb
# 从本地llm.local模块导入ollama_qa函数
from llm.local import ollama_qa
# 加载本地的句子嵌入模型 all-MiniLM-L6-v2
model = SentenceTransformer("all-MiniLM-L6-v2")
# 创建持久化的Chroma客户端,数据将保存在本地的./chroma_db目录下
client = chromadb.PersistentClient(path="./chroma_db")
# 获取或创建名为"rag_collection"的集合
collection = client.get_or_create_collection("rag_collection")
# 导入requests库用于网络请求
import requests
# 导入langchain的文本分割器
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 导入hashlib用于生成唯一ID
import hashlib
# 导入BeautifulSoup用于网页解析
from bs4 import BeautifulSoup
# 导入re用于正则表达式处理
import re
# 导入markdownify用于HTML转Markdown
from markdownify import markdownify as md
from strsimpy.normalized_levenshtein import NormalizedLevenshtein
# Serper API的密钥
SERPER_API_KEY = "2083cd014458a8ba01651de7f2f8ec8e834e3c98"
# Serper API的URL
SERPER_API_URL = "https://google.serper.dev/search"
# 定义函数:将文本转为embedding向量
def get_text_embedding(text):
# 打印日志,提示正在进行向量化
print("[日志] 正在将文本转为向量...")
# 使用模型进行编码并转为列表
return model.encode(text).tolist()
# 定义函数:向量检索,返回最相关的文本块列表
def retrieve_related_chunks(query_embedding, n_results=3):
# 打印日志,提示正在进行向量检索
print(f"[日志] 正在进行向量检索,返回最相关的{n_results}个文本块...")
# 在集合中进行向量检索,返回最相关的n_results个结果
results = collection.query(query_embeddings=[query_embedding], n_results=n_results)
# 获取检索到的文档内容
related_chunks = results.get("documents")
# 如果没有检索到相关内容,则提示并退出程序
if not related_chunks or not related_chunks[0]:
print("未检索到相关内容,请先入库或检查数据库!")
exit(1)
# 打印日志,显示检索到的文本块数量
print(f"[日志] 成功检索到{len(related_chunks[0])}个相关文本块。")
# 返回最相关的文本块列表
return related_chunks[0]
# 联网搜索,返回网页摘要列表
def search_serper(query, num=5):
# 打印日志,提示正在联网搜索
print("[日志] 正在通过Serper API联网搜索...")
# 构造请求头
headers = {"X-API-KEY": SERPER_API_KEY, "Content-Type": "application/json"}
# 构造请求数据
data = {"q": query}
try:
# 发送POST请求到Serper API
resp = requests.post(SERPER_API_URL, headers=headers, json=data, timeout=10)
# 检查请求是否成功
resp.raise_for_status()
# 解析返回的JSON数据
results = resp.json()
# 用于存储摘要的列表
docs = []
# 遍历前num条有机搜索结果
for item in results.get("organic", [])[:num]:
# 获取摘要内容
snippet = item.get("snippet", "")
# 获取链接
url = item.get("link", "")
# 如果有摘要则加入docs
if snippet:
docs.append({"url": url, "content": snippet})
# 打印日志,显示获取到的摘要数量
print(f"[日志] 搜索到{len(docs)}条摘要。")
# 返回摘要列表
return docs
except Exception as e:
# 打印错误日志
print("[错误] Serper API请求失败:", e)
# 返回空列表
return []
# 文本分块与入库(避免重复)
def preprocess_and_store(docs):
# 打印日志,提示正在进行数据预处理与入库
print("[日志] 正在进行数据预处理与入库...")
# 创建文本分割器,设置分块大小和重叠
splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=30,
separators=["\n\n", "\n", ".", "。", ",", ","],
)
# 遍历每个文档
for doc in docs:
# 获取文档URL
url = doc["url"]
# 获取文档内容
content = doc["content"]
# 对内容进行分块
chunks = splitter.split_text(content)
# 遍历每个分块
for chunk in chunks:
# 生成唯一ID(url+chunk的md5)
doc_id = hashlib.md5((url + chunk).encode("utf-8")).hexdigest()
# 检查该分块是否已存在
exists = collection.get(ids=[doc_id])
if exists and exists.get("ids"):
# 已存在则跳过
continue
# 获取分块的向量
embedding = get_text_embedding(chunk)
# 将分块及其向量入库
collection.add(documents=[chunk], embeddings=[embedding], ids=[doc_id])
# 打印日志,提示数据入库完成
print("[日志] 数据入库完成。")
# 计算关键词相似度(基于NormalizedLevenshtein)
def keyword_similarity(query, text):
norm_lev = NormalizedLevenshtein()
# 归一化距离越小,相似度越高,返回1-距离
return 1 - norm_lev.distance(query, text)
# 抓取网页正文
def fetch_web_content(url):
try:
# 发送GET请求获取网页内容
resp = requests.get(url, timeout=8)
# 检查请求是否成功
resp.raise_for_status()
# 用BeautifulSoup解析网页
soup = BeautifulSoup(resp.text, "html.parser")
# 获取格式化后的HTML
html = soup.prettify()
# 将HTML转为Markdown
md_text = md(html)
# 用正则去除多余空白
md_text = re.sub(r"\s+", " ", md_text)
# 返回清洗后的文本
return md_text.strip()
except Exception as e:
# 打印警告日志
print(f"[警告] 抓取{url}失败: {e}")
# 返回空字符串
return ""
# 主流程入口
if __name__ == "__main__":
# 打印日志,提示程序启动
print("[日志] 程序启动,准备接受用户输入。")
# 设置用户查询问题
query = "北京今日新闻是什么?"
# 打印日志,显示用户输入的问题
print(f"[日志] 用户输入的问题为:{query}")
# 1. 联网搜索,获取摘要
docs = search_serper(query, num=20)
# 如果没有获取到摘要则退出
if not docs:
print("[错误] 未获取到搜索结果,无法继续。")
exit(1)
# 2. 计算摘要与query的关键词相似度,选top-k
for doc in docs:
# 计算相似度并存入字典
doc["sim"] = keyword_similarity(query, doc["content"])
# 按相似度降序排序
docs_sorted = sorted(docs, key=lambda d: d["sim"], reverse=True)
# 设定top-k数量
top_k = 5
# 选取top-k摘要
top_docs = docs_sorted[:top_k]
# 打印日志,显示选取的摘要数量
print(f"[日志] 选取top-{top_k}摘要用于抓取正文。")
# 3. 抓取top-k摘要的网页正文
full_docs = []
for doc in top_docs:
# 获取URL
url = doc["url"]
# 抓取网页正文
content = fetch_web_content(url)
# 如果抓取到内容则加入full_docs
if content:
full_docs.append({"url": url, "content": content})
# 如果没有抓取到任何正文则退出
if not full_docs:
print("[错误] 未能抓取到任何网页正文,无法继续。")
exit(1)
# 4. 对正文内容分块并入库
preprocess_and_store(full_docs)
# 5. Query向量化
query_embedding = get_text_embedding(query)
# 打印日志,提示向量化完成
print("[日志] Query向量化完成。")
# 6. 向量检索
related_chunks = retrieve_related_chunks(query_embedding, n_results=3)
# 打印日志,提示向量检索完成
print("[日志] 向量检索完成。")
# 7. 构建Prompt
context = "\n".join(related_chunks)
# 构造prompt字符串
prompt = f"已知信息:\n{context}\n\n请根据上述内容回答用户问题:{query}"
# 打印prompt内容
print("prompt:", prompt)
# 打印日志,提示Prompt构建完成
print("[日志] Prompt构建完成,准备调用大模型生成答案。")
# 8. 调用大模型生成答案
answer = ollama_qa(prompt)
# 打印日志,提示答案生成完成
print("[日志] 答案生成完成。")
# 输出最终答案
print("\n【答案】\n", answer)