- 1. 图的知识
- 2. 图的基本概念
- 3. 安装Neo4j
- 第4章:Neo4j Browser使用
- 5. Cypher语法入门
- 6. 创建数据
- 7. 查询数据
- 8. Python环境准备
- 第9章:Python操作Neo4j
- 第10章:电影推荐系统
- 11. 社交网络分析
- 12. 复杂查询
- 12.2 路径查询:找到两个节点之间的路径
- 12.3 聚合查询:统计和分组
- 12.4 排序和分页:LIMIT和ORDER BY
- 13. 数据更新和删除
- 14. 数据导入导出
- 15. 性能优化基础
- 16. 图书管理系统
- 17. 知识图谱构建
- 18. Neo4j 日期时间处理指南
1. 图的知识 #
- uv
- 图的知识
- 知识图谱
- 知识图谱与RAG
- neo4j安装
- Neo4j
- neo4j4python
- streamlit
- read_csv
- abc
- py2neo
- Plotly
- Matplotlib
- heapq
- PageRank算法
- Dijkstra算法
- 最小堆
- GDS
- APOC
- FastAPI
- 图书知识图谱
1.1 社交网络 #
想象一下你的微信朋友圈:
- 你和朋友之间是“好友关系”,朋友之间也可能相互认识。这种复杂的关系网络就是一个图!
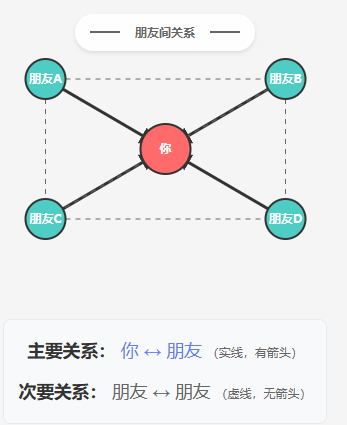
- 图(Graph):由节点(Node)和边(Edge)组成的数据结构。节点代表实体,边代表实体之间的关系。
- 节点(Node/Vertex):图中的点,表示具体的对象或实体,如“你”、“朋友A”。
- 边(Edge/Relationship):连接两个节点的线,表示它们之间的关系,如“好友关系”。
1.2 地图导航 #
当你使用导航软件时:
- 地点是节点,道路是连接,距离是属性。这就是一个典型的图结构!
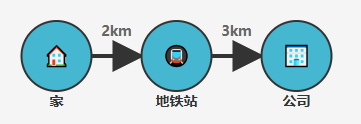
- 属性(Property):节点或边上附加的信息,如“距离=2km”。
关键概念: 图由节点(实体)和边(关系)组成,就像社交网络中的用户和好友关系,地图中的地点和道路连接。
1.3 传统数据库的局限性 #
传统的关系型数据库(如MySQL、Oracle)在处理复杂关系时遇到了挑战。
| 场景 | 传统数据库 | 图数据库 |
|---|---|---|
| 查找朋友的朋友 | 需要多次JOIN操作,查询复杂 | 直接遍历关系,查询简单 |
| 推荐系统 | 需要复杂的SQL查询和临时表 | 直接分析用户关系网络 |
| 路径查找 | 需要递归查询,性能差 | 内置图算法,性能优秀 |
| 关系复杂度 | 表结构固定,难以扩展 | 关系灵活,易于扩展 |
1.3.1 传统数据库的挑战 #
假设要查找“朋友的朋友的朋友”:
-- 假设有users表(用户信息)和friendships表(好友关系)
-- users表结构:id, name
-- friendships表结构:user_id, friend_id
-- 1. 选择张三的所有朋友
-- 2. 再找这些朋友的朋友
-- 3. 再找这些朋友的朋友的朋友
SELECT f3.name
FROM users u1
-- 连接第一层好友关系
JOIN friendships f1 ON u1.id = f1.user_id
JOIN users u2 ON f1.friend_id = u2.id
-- 连接第二层好友关系
JOIN friendships f2 ON u2.id = f2.user_id
JOIN users u3 ON f2.friend_id = u3.id
-- 连接第三层好友关系
JOIN friendships f3 ON u3.id = f3.user_id
JOIN users f3 ON f3.friend_id = f3.id
WHERE u1.name = '张三';- 关系型数据库(Relational Database):以表格(行和列)形式存储数据,通过主键和外键建立表之间的关系。
- JOIN操作:SQL中的一种操作,用于将多个表的数据关联起来。
1.4 图数据库的优势 #
图数据库专门为处理关系数据而设计,具有天然的优势。
- ⚡ 查询速度快:关系直接存储,无需JOIN
- 🔗 关系直观:数据模型更接近现实
- 📈 易于扩展:添加新关系类型很简单
- 🎯 算法丰富:内置图算法库
1.4.1 图数据库更简单 #
// 查询“张三”的朋友的朋友的朋友
// 1. 匹配name为'张三'的Person节点
// 2. 沿着FRIEND关系走3步,找到所有朋友的朋友的朋友
// 3. 返回这些人的姓名
MATCH (me:Person {name: '张三'})-[:FRIEND*3]->(friend:Person)
RETURN friend.name;1.4.2 名词 #
- 图数据库(Graph Database):以图结构存储和管理数据的数据库,节点和边是核心。
- Cypher:Neo4j的声明式查询语言,专为图数据设计,语法直观易懂。
- 模式匹配(Pattern Matching):通过描述节点和关系的结构,查找符合条件的子图。
- 图遍历(Graph Traversal):按照关系从一个节点出发,访问其他节点的过程。
1.4.3 Cypher语法 #
MATCH (me:Person {name: '张三'})-[:FRIEND*3]->(friend:Person)MATCH:匹配模式的关键字,用于查找图中的节点和关系(me:Person):定义节点变量me,类型为Person{name: '张三'}:节点属性过滤,只匹配name属性为'张三'的Person节点-[:FRIEND*3]->:关系模式,表示FRIEND关系,*3表示重复3次(3步)(friend:Person):目标节点变量friend,类型为Person
RETURN friend.nameRETURN:返回结果的关键字friend.name:返回friend节点的name属性值
1.4.4 查询执行过程 #
- 找到name为'张三'的Person节点
- 沿着FRIEND关系找到张三的所有朋友
- 继续沿着FRIEND关系找到朋友的朋友
- 最后找到朋友的朋友的朋友
- 返回所有第3层朋友的姓名
图数据库的核心思想:
数据 = 节点 + 关系 + 属性
查询 = 图遍历 + 模式匹配
1.5 Neo4j最流行的图数据库 #
Neo4j是目前最流行、最成熟的图数据库,被广泛应用于各个领域。
| 特性 | Neo4j | 其他图数据库 |
|---|---|---|
| 市场份额 | 图数据库市场领导者 | 相对较小 |
| 查询语言 | Cypher(直观易学) | Gremlin、SPARQL等 |
| 社区支持 | 活跃的开发者社区 | 相对较小 |
| 学习资源 | 丰富的教程和文档 | 相对较少 |
1.5.1 Neo4j的成功案例 #
- 🎬 Netflix:电影推荐系统
- 🏦 Walmart:供应链管理
- 🔍 Google:知识图谱
- 🚗 Uber:路径规划
1.5.2 Neo4j的优势 #
- 学习曲线平缓:Cypher查询语言直观易懂
- 生态系统完善:丰富的工具和库支持
- 社区活跃:大量学习资源和帮助
- 企业级支持:稳定可靠,适合生产环境
2. 图的基本概念 #
深入理解图数据库的核心组成元素
2.1 节点(Node):图中的实体 #
节点是图数据库中最基本的元素,代表现实世界中的实体。就像社交网络中的用户、地图中的地点、电商中的商品一样。
2.1.1 节点定义 #
节点(Node)是图中的基本单位,用来表示现实世界中的实体对象。每个节点都有唯一的标识符,可以包含各种属性信息。
2.1.2 节点示例 #
在社交网络中,节点可以是:
👤 张三 👤 李四 👤 王五 👤 赵六每个节点代表一个真实的人,包含这个人的各种信息。
- 节点(Node/Vertex):图中的点,表示具体的对象或实体,如“用户”“地点”“商品”等。
- 唯一标识符:每个节点在图中都有唯一的ID,便于区分和引用。
- 属性(Property):节点上附加的键值对信息,如姓名、年龄等。
💡 关键要点
- 节点是图的基本组成单位
- 每个节点都有唯一标识符
- 节点可以包含多个属性
- 节点之间通过关系连接
2.2 关系(Relationship):节点之间的连接 #
关系是连接节点的纽带,表示实体之间的关联。关系是有方向的,从起始节点指向目标节点。
2.2.1 关系定义 #
关系(Relationship)是连接两个节点的有向边,表示实体之间的关联。关系也有类型,用来区分不同的关联方式。
2.2.2 关系示例 #
在社交网络中,关系可以是:
👥 好友 👨💼 同事 👨🎓 同学 👨👩👧👦 家人每种关系类型表示不同的关联方式。
2.2.3 名词 #
- 关系(Relationship/Edge):连接两个节点的有向边,表示实体之间的某种联系。
- 关系类型:用来区分不同的关系,如FRIEND(朋友)、COLLEAGUE(同事)等。
- 有向边:关系有方向性,从起始节点指向目标节点。
- 关系属性:关系本身也可以有属性,如建立时间、亲密度等。
💡 关键要点
- 关系是有方向的,从起始节点指向目标节点
- 关系有类型,用来区分不同的关联
- 关系也可以包含属性
- 一个节点可以有多个关系
2.3 属性(Property):节点和关系的特征 #
属性是描述节点和关系特征的数据,就像人的姓名、年龄,或者关系的建立时间等。
2.3.1 属性定义 #
属性(Property)是附加在节点或关系上的键值对,用来描述实体的特征。属性可以是各种数据类型:字符串、数字、布尔值、日期等。
2.3.2 属性示例 #
节点属性(用户信息):
name: "张三" age: 25 city: "北京" email: "zhangsan@email.com"关系属性(好友关系):
since: "2020-01-15" strength: 0.8 lastContact: "2024-01-20"2.3.3 名词 #
- 属性(Property):节点或关系上附加的键值对信息,用于描述特征。
- 数据类型:属性可以是字符串、数字、布尔值、日期等多种类型。
💡 关键要点
- 属性是键值对形式的数据
- 节点和关系都可以有属性
- 属性支持多种数据类型
- 属性可以动态添加和修改
2.4 标签(Label):节点的分类 #
标签是节点的分类标识,用来对节点进行分组和管理。就像给文件添加文件夹一样。
2.4.1 标签定义 #
标签(Label)是节点的分类标识,用来对节点进行分组。一个节点可以有多个标签,方便查询和管理。
2.4.2 标签示例 #
在电商系统中,节点可以有多种标签:
👤 User 🛍️ Product 🏪 Store 📦 Order一个用户节点可以有:👤 User + 👑 VIP 两个标签
2.4.3 名词 #
- 标签(Label):节点的分类标识,可以为节点打上一个或多个标签,便于分组和查询。
| 概念 | 作用 | 示例 |
|---|---|---|
| 节点(Node) | 表示实体对象 | 用户、商品、订单 |
| 关系(Relationship) | 连接节点,表示关联 | 购买、属于、评价 |
| 属性(Property) | 描述特征信息 | 姓名、价格、时间 |
| 标签(Label) | 分类标识 | User、Product、VIP |
2.5 Cypher 查询示例 #
2.5.1 节点查询 #
// 创建一个User节点,包含姓名和年龄属性
CREATE (u:User {name: '张三', age: 25})
// 查询所有User节点
MATCH (u:User) RETURN u2.5.2 关系查询 #
// 查询名为'张三'的User节点
MATCH (a:User {name: '张三'}) RETURN a
// 查询名为'李四'的User节点
MATCH (b:User {name: '李四'}) RETURN b
// 创建a到b之间的FRIEND关系
CREATE (a)-[:FRIEND]->(b)
// 查询所有FRIEND关系的节点对
MATCH (a)-[:FRIEND]->(b) RETURN a, b意思是查询不能以 MATCH 结束,必须以以下之一结束:
- RETURN 子句(返回数据)
- FINISH 子句
- 更新子句(如 CREATE, SET, DELETE 等)
- 单位子查询调用
- 不带 YIELD 的过程调用
2.5.3 属性查询 #
// 查询名为'张三'的User节点,设置city和email属性
MATCH (u:User {name: '张三'}) SET u.city = '北京', u.email = 'zhangsan@email.com'
// 查询所有年龄大于20岁的User节点
MATCH (u:User) WHERE u.age > 20 RETURN u2.5.4 标签查询 #
// 查询名为'张三'的User节点,给该节点添加VIP标签
MATCH (u:User {name: '张三'}) SET u:VIP
// 查询所有带有VIP标签的节点
MATCH (u:VIP) RETURN u
// 查询同时带有User和VIP标签的节点
MATCH (u:User:VIP) RETURN u3. 安装Neo4j #
从零开始,轻松安装和配置Neo4j数据库
3.1 下载Neo4j Desktop #
Neo4j Desktop是Neo4j官方提供的图形化界面工具,让数据库管理变得简单直观。
- Neo4j Desktop:Neo4j官方推出的桌面端图形化管理工具,适合初学者和开发者进行本地数据库管理、可视化操作和插件扩展。
- 端口(Port):计算机网络通信的入口,Neo4j默认使用7474端口进行Web访问。
- 配置文件:Neo4j的运行参数和资源分配设置,通常在安装目录的conf文件夹下。
3.1.1 系统要求 #
- 操作系统:Windows 10/11、macOS 10.14+、Ubuntu 18.04+
- 内存:至少4GB RAM(推荐8GB以上)
- 存储空间:至少2GB可用空间
- 网络:需要互联网连接下载安装包
- Java:Neo4j Desktop会自动安装所需Java版本
3.1.2 下载Neo4j Desktop #
点击下面的按钮,访问Neo4j官方网站下载最新版本:
当前最新版本:Neo4j Desktop 1.5.x
3.1.3 下载步骤 #
- 访问官网:https://neo4j.com/download/
- 选择版本:点击"Download Neo4j Desktop"按钮
- 选择平台:根据你的操作系统选择对应的安装包
- 开始下载:点击下载按钮,等待文件下载完成
💡 下载建议:
- 选择稳定版本:建议下载最新的稳定版本
- 验证下载:下载完成后检查文件完整性
- 备份重要数据:安装前备份现有数据库(如果有)
3.2 创建第一个数据库 #
安装完成后,让我们创建你的第一个Neo4j数据库实例。
3.2.1 安装步骤 #
- 运行安装程序:双击下载的安装文件
- 接受许可协议:阅读并接受Neo4j许可条款
- 选择安装路径:建议使用默认路径
- 完成安装:等待安装完成,启动Neo4j Desktop
3.2.2 创建实例 #
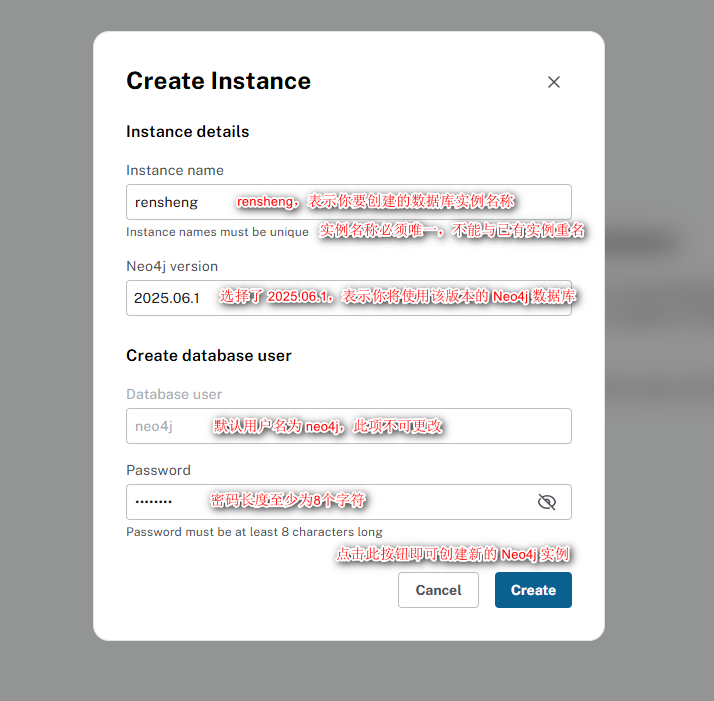
3.2.3 创建数据库 #
⚠️ 重要提醒:
- 记住密码:数据库管理员密码非常重要,请妥善保存
- 端口占用:Neo4j默认使用7474端口,确保该端口未被占用
- 防火墙设置:如果遇到连接问题,检查防火墙设置
- 数据库实例:在Neo4j Desktop中新建的一个独立数据库环境,可以单独启动、停止和管理。
- 管理员密码:用于登录和管理数据库的最高权限密码。
3.3 启动和停止数据库 #
Neo4j Desktop用户请直接在图形界面中点击“启动”或“停止”按钮。
💡 管理技巧:
- 定期重启:长时间运行后建议重启数据库
- 监控资源:注意内存和CPU使用情况
- 备份数据:重要操作前先备份数据库
3.4 基本配置设置 #
3.4.1 基本配置 #
⚠️ 配置注意事项:
- 内存设置:不要超过系统可用内存的80%
- 端口冲突:确保配置的端口未被其他程序占用
- 权限问题:某些配置需要管理员权限
- 备份配置:修改配置前先备份原文件
- 内存分配:Neo4j允许通过配置文件调整JVM堆内存和页面缓存,提升大数据量下的性能。
- 日志文件:Neo4j运行时会生成日志,便于排查问题。
3.4.2 配置完成检查 #
- 数据库启动:配置修改后能正常启动
- 性能提升:查询速度有明显改善
- 资源使用:内存和CPU使用率合理
- 日志正常:没有错误或警告信息
3.4.3 性能优化建议 #
- 根据数据量调整内存:大数据集需要更多内存
- 启用查询缓存:提高重复查询性能
- 定期清理日志:避免日志文件过大
- 监控系统资源:及时发现性能瓶颈
第4章:Neo4j Browser使用 #
学会使用Neo4j官方可视化工具,轻松管理和查询图数据库
4.1 打开Neo4j Browser #
💡 Neo4j Browser 是 Neo4j 官方提供的可视化图数据库交互工具。
- Neo4j Browser:Neo4j官方推出的Web可视化管理工具,支持图形化展示、Cypher查询、数据浏览、收藏管理等功能。
- Cypher:Neo4j专用的声明式图查询语言,语法直观,适合图数据操作。
- 确保 Neo4j 数据库服务已启动。
- 在浏览器地址栏输入
http://localhost:7474并回车。 - 首次访问会提示输入用户名和密码,默认用户名为
neo4j,密码为安装时设置的密码。
登录成功后,即可进入 Neo4j Browser 主界面。
4.2 界面介绍 #
在查询框中输入以下 Cypher 语句,查看数据库的基本信息:
// 调用db.info()过程,获取当前数据库的基本信息
CALL db.info();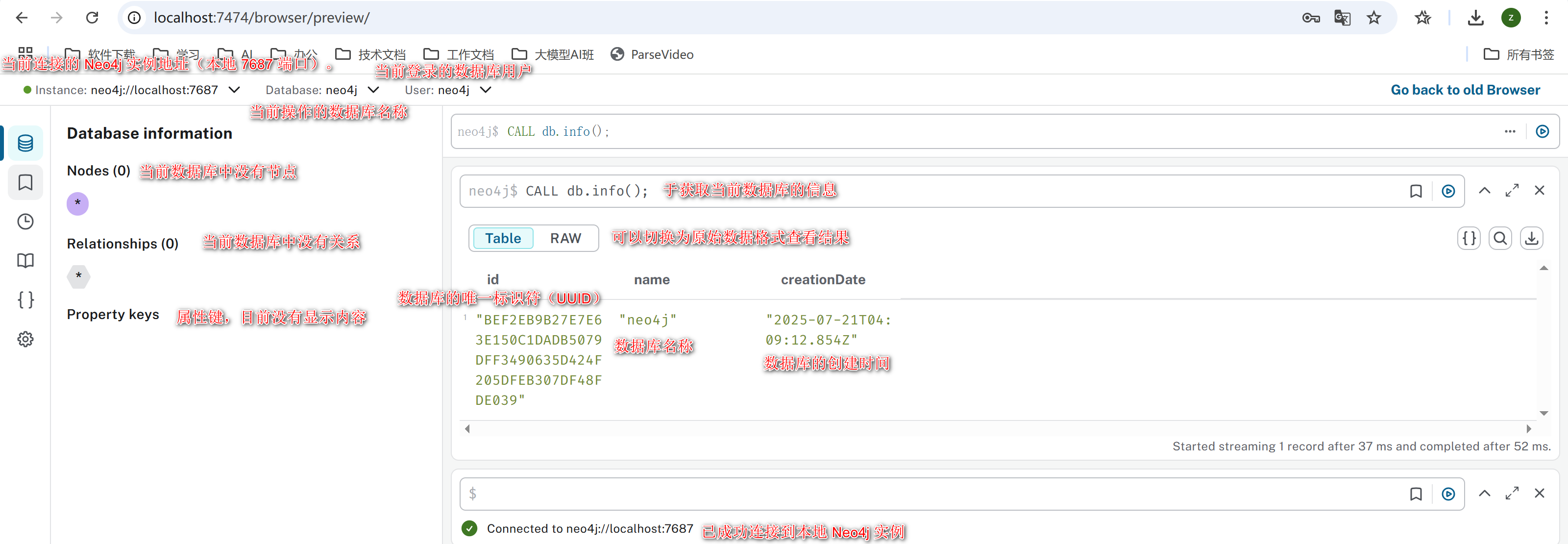
4.3 第一个查询:查看数据库信息 #
SHOW DATABASES;—— 查看所有数据库列表
// 显示当前Neo4j实例下的所有数据库
SHOW DATABASES;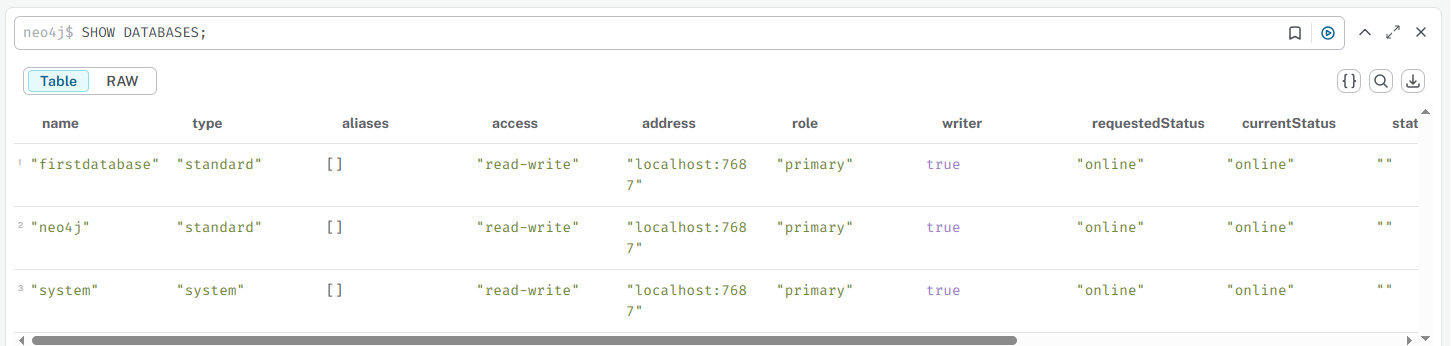
4.4 保存和加载查询 #
💡 Neo4j Browser 支持将常用查询保存为收藏,方便后续快速调用。
- 收藏(Saved Cypher):将常用的Cypher查询语句保存下来,便于后续一键调用。
- 查询历史(History):自动记录你执行过的所有Cypher语句,方便回溯和复用。
- 在查询框输入并执行查询语句。
- 点击查询结果右上角的“Open save cypher prompt”图标,将该查询添加到收藏。
- 左侧“收藏”区域可查看、管理已保存的查询。
- 点击收藏的查询即可自动加载到查询框,直接执行。
通过收藏功能,可以高效管理和复用常用的 Cypher 查询。
4.5 Browser常用功能区一览 #
| 功能区 | 说明 | 示例图片 |
|---|---|---|
| 📊 数据库信息 | 展示当前数据库的基本信息、节点和关系统计等 | 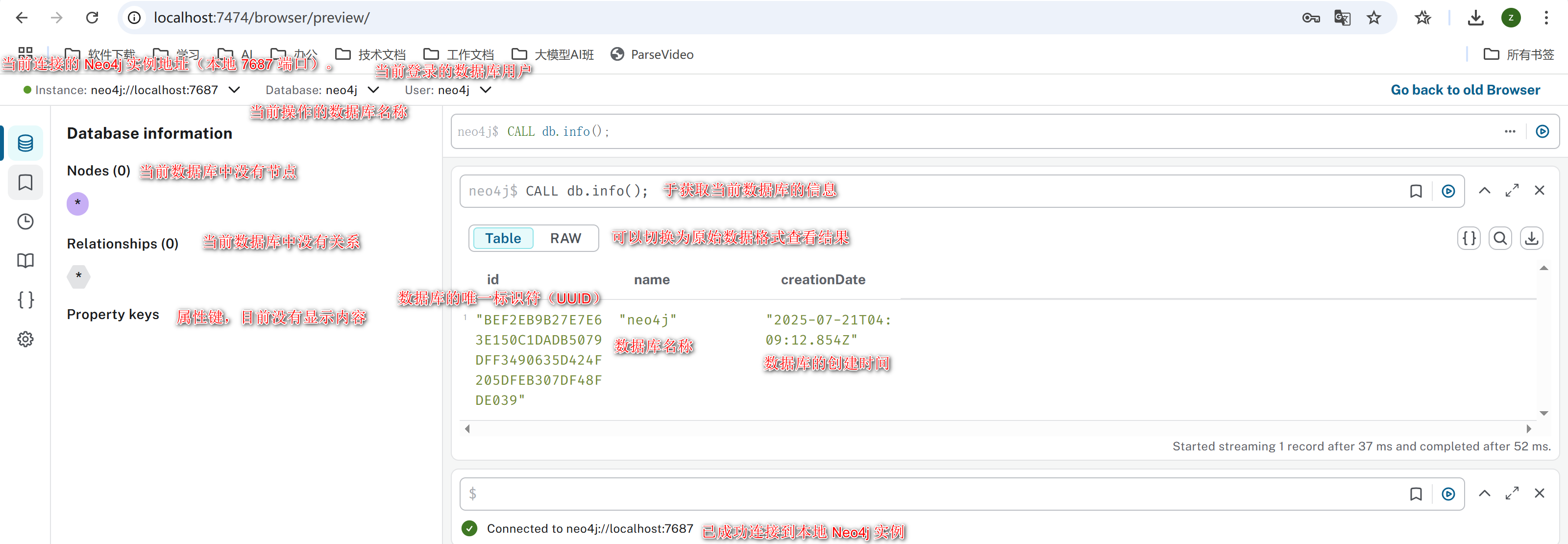 |
| ⭐ 收藏的 Cypher | 管理和快速调用你收藏的常用 Cypher 查询 |  |
| 🕓 历史 | 查看你最近执行过的 Cypher 查询历史 | 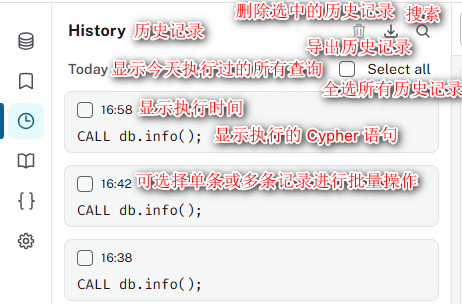 |
| 📖 Cypher 参考 | 快速查阅 Cypher 语法和函数参考 |  |
| ⚙️ 参数 | 管理和设置 Cypher 查询的参数变量 | 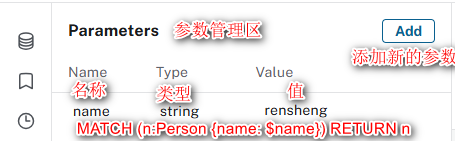 |
| 🔧 设置 | 调整 Browser 的主题、字体等个性化设置 |  |
- 参数(Parameter):在Cypher查询中可用的变量,用于动态传递值,提升查询灵活性和安全性。
- Cypher参考:内置的语法和函数帮助文档,便于快速查阅。
- 个性化设置:可调整主题、字体、布局等,提升使用体验。
5. Cypher语法入门 #
掌握Cypher的基本语法,为图数据库查询打下坚实基础
5.1 什么是Cypher:图数据库的SQL #
Cypher是Neo4j的声明式查询语言,专为图数据库设计。它的语法直观、易学,类似于SQL,但更适合表达节点、关系和图结构。
- Cypher:Neo4j官方的声明式图查询语言,专为图结构数据设计,语法直观,易于学习。
- SQL:结构化查询语言,传统关系型数据库的标准查询语言。
-- SQL 查询示例
-- 查询users表中所有年龄大于18岁的用户姓名
SELECT name FROM users WHERE age > 18;// Cypher 查询示例
// 查询所有年龄大于18岁的Person节点的姓名
MATCH (p:Person) WHERE p.age > 18 RETURN p.name;💡 Cypher 让你像描述图结构一样描述查询,天然支持节点、关系和属性。
5.2 基本语法规则 #
- 每条语句以分号(
;)结尾(可选,但推荐)。 - 关键字不区分大小写,变量/标签区分大小写。
- 节点用圆括号
()表示,关系用中括号[]表示。 - 关系有方向时用
->或<-,无方向用--。 - 属性用花括号
{}表示,如{name: '张三'}。
- 节点(Node):图中的实体对象,用圆括号表示。
- 关系(Relationship):连接两个节点的边,用中括号表示。
- 属性(Property):节点或关系上的键值对信息。
- MATCH:Cypher中的模式匹配关键字,用于查找符合条件的节点和关系。
- RETURN:Cypher中的结果返回关键字,用于指定查询输出。
// 匹配name为'张三'的Person节点,查找其所有朋友的姓名
MATCH (a:Person {name: '张三'})-[:FRIEND]->(b:Person)
RETURN b.name;💡 MATCH 用于模式匹配,RETURN 用于返回结果。
5.3 变量命名:使用有意义的名称 #
Cypher中的变量用于引用节点、关系或属性。建议使用有意义的英文单词,便于理解和维护。
- 节点变量:如
person、friend、movie - 关系变量:如
rel、knows、actedIn
- 变量(Variable):在Cypher中用于引用节点、关系或属性的占位符,通常用小写英文单词命名。
// 匹配Person节点之间的KNOWS关系,返回双方姓名
MATCH (person:Person)-[knows:KNOWS]->(friend:Person)
RETURN person.name, friend.name;好的变量名让查询更易读,尤其在复杂图结构中。
5.4 注释:让代码更易读 #
Cypher支持单行注释,使用 // 开头。注释有助于解释查询意图,提升代码可维护性。
- 注释(Comment):对代码进行说明的文本,不会被执行,便于团队协作和后期维护。
// 查找张三的所有朋友
MATCH (p:Person {name: '张三'})-[:FRIEND]->(f:Person)
RETURN f.name;💡 建议:为每个复杂查询添加注释,方便团队协作和后期维护。
6. 创建数据 #
学会用Cypher在Neo4j中创建节点、关系和属性
6.1 创建节点:CREATE语句 #
在Neo4j中,节点(Node)是图的基本单元。使用 CREATE 语句可以创建一个或多个节点。
- CREATE:Cypher中的关键字,用于创建节点、关系等新数据。
- 节点(Node):图中的实体对象。
- 变量(Variable):用于引用节点或关系的占位符。
// 创建一个没有标签和属性的空节点
CREATE (n)这条语句会创建一个没有标签和属性的空节点。
n是什么?
n是一个变量名,用于引用刚刚创建的节点。你可以用任意有意义的英文单词代替它,比如person、user等。后续的查询、设置属性、创建关系时,可以通过这个变量名操作该节点。
// 创建一个带有Person标签的节点
CREATE (p:Person)创建一个带有
Person标签的节点。
6.2 添加标签:给节点分类 #
标签(Label)用于给节点分类,一个节点可以有一个或多个标签。
- 标签(Label):用于对节点进行分类的标识,可以有多个。
// 创建一个带有Movie标签的节点
CREATE (m:Movie)创建一个带有
Movie标签的节点。
// 创建一个同时拥有Person和Student标签的节点
CREATE (p:Person:Student)一个节点可以同时拥有多个标签,如
Person和Student。
6.3 设置属性:存储详细信息 #
属性(Property)用于存储节点的详细信息,格式为 {key: value}。
- 属性(Property):节点或关系上的键值对信息,用于描述特征。
// 创建一个Person节点,并设置name和age属性
CREATE (p:Person {name: '张三', age: 22})创建一个
Person节点,并设置name和age属性。
// 创建一个Movie节点,并设置title和year属性
CREATE (m:Movie {title: '星际穿越', year: 2014})创建一个
Movie节点,并设置title和year属性。
6.4 创建关系:连接节点 #
关系(Relationship)用于连接两个节点,表达它们之间的联系。使用 CREATE 语句可以直接创建关系。
- 关系(Relationship):连接两个节点的有向或无向边,表示实体间的联系。
// 创建两个Person节点,并用FRIEND关系连接
CREATE (a:Person {name: '张三'})-[:FRIEND]->(b:Person {name: '李四'})创建两个
Person节点,并用FRIEND关系连接。
在 Neo4j 中:
关系必须是有方向的(使用 --> 或 <--)
无方向的关系(--)只能在 MATCH 查询中使用,不能在 CREATE 语句中使用
// 先查找已存在的节点,再创建带属性的KNOWS关系
MATCH (a:Person {name: '张三'}), (b:Person {name: '李四'})
CREATE (a)-[:KNOWS {since: 2020}]->(b)先查找已存在的节点,再创建带属性的
KNOWS关系。
7. 查询数据 #
掌握Cypher查询,灵活查找和返回图数据库中的数据
7.1 查找节点:MATCH语句 #
Cypher中最常用的查询语句是 MATCH,用于在图中查找节点或关系。
- MATCH:Cypher中的关键字,用于在图中查找节点或关系。
- 变量(Variable):用于引用节点或关系的占位符。
// 查找所有节点,n是节点变量名
MATCH (n) RETURN n查找所有节点,
n是节点变量名。
// 查找所有带有Person标签的节点
MATCH (p:Person) RETURN p查找所有带有
Person标签的节点。
7.2 按标签查询:找到特定类型 #
通过标签(Label)可以快速筛选出特定类型的节点。
- 标签(Label):用于对节点进行分类的标识。
// 查找所有Movie类型的节点
MATCH (m:Movie) RETURN m查找所有
Movie类型的节点。
// 查找同时拥有Person和Student标签的节点
MATCH (p:Person:Student) RETURN p查找同时拥有
Person和Student标签的节点。
7.3 按属性查询:WHERE条件 #
使用 WHERE 子句可以根据属性值筛选节点。
- 属性(Property):节点或关系上的键值对信息。
- WHERE:Cypher中的条件过滤关键字,用于筛选满足条件的节点或关系。
// 查找名字为“张三”的Person节点
MATCH (p:Person) WHERE p.name = '张三'
RETURN p查找名字为“张三”的
Person节点。
// 查找2010年之后上映的电影,返回标题和年份
MATCH (m:Movie) WHERE m.year > 2010
RETURN m.title, m.year查找2010年之后上映的电影。
7.4 返回结果:RETURN语句 #
使用 RETURN 语句可以指定查询结果的输出内容。
- RETURN:Cypher中的结果返回关键字,用于指定查询输出。
// 返回所有Person节点的姓名和年龄
MATCH (p:Person)
RETURN p.name, p.age返回所有
Person节点的姓名和年龄。
// 返回所有朋友关系的两个人的姓名
MATCH (a:Person)-[:FRIEND]->(b:Person)
RETURN a.name, b.name返回所有朋友关系的两个人的姓名。
8. Python环境准备 #
用Python操作Neo4j,开启图数据分析之旅
8.1 安装Python Neo4j驱动 #
要让Python与Neo4j通信,需要安装官方驱动包 neo4j。
- Neo4j驱动(neo4j driver):官方提供的Python库,用于让Python程序与Neo4j数据库通信。
- pip:Python的包管理工具,用于安装和管理第三方库。
# 推荐使用pip安装
pip install neo4j建议使用Python 3.7及以上版本,确保pip已升级到最新。
8.2 连接数据库:建立Python与Neo4j的桥梁 #
使用 GraphDatabase.driver 方法创建数据库连接对象。
- Bolt协议:Neo4j专用的高性能二进制通信协议,端口号默认7687。
- auth:认证参数,包含用户名和密码。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 创建数据库连接对象,指定Bolt协议地址和认证信息
# "你的密码"请替换为实际设置的密码
# driver对象用于后续所有数据库操作
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "你的密码"))
bolt://localhost:7687是Neo4j默认的Bolt协议地址,用户名通常为neo4j。
8.3 测试连接:确保一切正常 #
可以通过执行一条简单的Cypher语句来测试连接是否成功。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 创建数据库连接对象
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "12345678"))
# 创建会话,执行Cypher语句
with driver.session() as session:
# 执行一条简单的Cypher查询,返回1
result = session.run("RETURN 1")
# result.single() 返回查询结果的第一行记录(Record对象)
# Record对象的[0]表示返回结果的第一个值
print(result.single()[0])8.3.1 Record对象是什么? #
在Neo4j官方Python驱动中,session.run() 执行Cypher查询后返回一个结果集(Result对象),其中每一行数据都是一个 Record 对象。可以把 Record 理解为“查询结果中的一行”,它本质上是一个类似元组的结构,支持下标访问和字段名访问。
例如:
result.single()返回结果集的第一行(Record对象)。result.single()[0]取出该行的第一个字段的值。
你也可以通过字段名访问,比如:
record = result.single()
print(record["1"]) # 如果Cypher语句返回的字段名为"1"总结:Record 就是Cypher查询结果中的一行数据,支持下标和字段名两种方式取值,便于灵活处理查询结果。
8.4 基本配置:设置连接参数 #
连接Neo4j时可以设置一些常用参数,提升安全性和性能:
encrypted:是否启用加密(默认为False,生产环境建议True)max_connection_lifetime:连接最大存活时间(秒)max_connection_pool_size:连接池最大连接数
- 连接池(Connection Pool):用于管理和复用数据库连接,提升并发性能。
- 加密(Encryption):数据传输过程中的加密保护,提升安全性。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 创建数据库连接对象,设置加密和连接池参数
# encrypted=False表示不加密,生产环境建议设置为True
# max_connection_lifetime=3600表示连接最长存活1小时
# max_connection_pool_size=10表示最大连接数为10
driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("neo4j", "12345678"),
encrypted=False,
max_connection_lifetime=3600,
max_connection_pool_size=10,
)
# 创建会话,执行Cypher语句
with driver.session() as session:
# 执行一条简单的Cypher查询,返回1
result = session.run("RETURN 1")
# 打印查询结果
print(result.single()[0])生产环境建议开启加密,合理设置连接池参数可提升并发性能。
第9章:Python操作Neo4j #
用Python代码高效操作图数据库,掌握数据的增删改查与结果处理
9.1 创建节点:用Python代码创建数据 #
使用Python操作Neo4j,首先需要安装官方驱动包 neo4j 并建立连接:
- 参数化查询:通过占位符和参数传递数据,防止注入攻击,提升安全性。
- session:会话对象,管理与数据库的交互。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 定义数据库连接地址和认证信息
uri = "bolt://localhost:7687"
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 定义Cypher语句,创建一个Person节点
cypher = "CREATE (p:Person {name: '张三', age: 25})"
# 创建会话,执行Cypher语句
with driver.session() as session:
session.run(cypher)
# 关闭驱动,释放资源
driver.close()建议实际开发中用参数化查询,防止注入风险。
参数化示例:
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
uri = "bolt://localhost:7687"
auth = ("neo4j", "12345678")
driver = GraphDatabase.driver(uri, auth=auth)
# 使用参数化查询,防止注入
cypher = "CREATE (p:Person {name: $name, age: $age})"
params = {"name": "李四", "age": 30}
# 指定数据库名称(如有多个库)
with driver.session(database="first") as session:
session.run(cypher, params)9.2 查询数据:在Python中执行Cypher #
通过 session.run() 方法可以执行任意Cypher查询,并获取结果:
- record:查询结果中的一行数据,支持下标和字段名访问。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
uri = "bolt://localhost:7687"
auth = ("neo4j", "12345678")
driver = GraphDatabase.driver(uri, auth=auth)
# 定义Cypher查询和参数
cypher = "MATCH (p:Person) WHERE p.age > $age RETURN p.name, p.age"
params = {"age": 20}
with driver.session(database="first") as session:
result = session.run(cypher, params)
for record in result:
# 通过字段名访问结果
print(record["p.name"], record["p.age"])
record是一行结果,可以用字段名或下标访问。
9.3 处理结果:解析查询返回的数据 #
查询结果 result 是一个可迭代对象,每个 record 代表一行。可以:
- 用
record["字段名"]访问指定字段 - 用
record.data()转为字典 - 用
list(result)一次性获取所有结果
- result:Cypher查询的结果集,是可迭代对象。
- data():将record对象转为字典,便于与Pandas等库集成。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
uri = "bolt://localhost:7687"
auth = ("neo4j", "12345678")
driver = GraphDatabase.driver(uri, auth=auth)
# 定义Cypher查询和参数
cypher = "MATCH (p:Person) WHERE p.age > $age RETURN p.name, p.age"
params = {"age": 20}
with driver.session(database="first") as session:
result = session.run("MATCH (p:Person) RETURN p.name, p.age")
for record in result:
# record.data() 返回字典格式的结果
print(record.data()) # 例如:{'p.name': '张三', 'p.age': 25}
record.data()返回字典,便于与Pandas等库集成。
9.4 错误处理:处理连接和查询错误 #
操作数据库时要注意捕获异常,常见错误有连接失败、语法错误、参数错误等:
- Neo4jError:Neo4j官方驱动定义的异常类型,捕获数据库相关错误。
- Exception:Python内置的通用异常类型。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
uri = "bolt://localhost:7687"
auth = ("neo4j", "12345678")
driver = GraphDatabase.driver(uri, auth=auth)
from neo4j.exceptions import Neo4jError
try:
with driver.session() as session:
session.run("MATCH (n) RETURN n LIMIT 1")
except Neo4jError as e:
print("Neo4j错误:", e)
except Exception as e:
print("其他错误:", e)
建议实际开发中对所有数据库操作加异常处理,保证程序健壮性。
第10章:电影推荐系统 #
用Neo4j构建简单的电影推荐系统,体验图数据库的强大关联分析能力
10.1 项目介绍:构建简单的推荐系统 #
本项目将用Neo4j和Python实现一个基础的电影推荐系统。通过用户、电影、评分等节点和关系,挖掘用户的兴趣,为其推荐可能喜欢的电影。
- 掌握图数据库在推荐系统中的建模思路
- 体验用Cypher和Python批量导入数据
- 实现基于用户兴趣的简单推荐算法
10.2 数据建模:设计电影和用户的关系 #
常见的推荐系统图模型包括:
User(用户)节点Movie(电影)节点RATED(评分)关系,连接用户和电影,带有评分属性
- MERGE:Cypher中的关键字,查找或创建节点/关系,避免重复。
- MATCH:Cypher中的关键字,仅查找已存在的节点/关系。
- 关系属性:关系本身也可以有属性,如评分score。
// 创建用户和电影节点
CREATE (u:User {name: 'Alice'}), (m:Movie {title: 'Inception'})
// 用户对电影评分,创建RATED关系并设置score属性
CREATE (u)-[:RATED {score: 5}]->(m)你可以为每个用户-电影对建立一条
RATED关系,属性如score表示评分。
10.3 数据导入:使用Python批量导入数据 #
实际项目中,用户和电影数据量较大,推荐用Python脚本批量导入:
- 批量导入:通过脚本一次性插入大量数据,提升效率。
- session:会话对象,管理与数据库的交互。
- MERGE:查找或创建,避免重复插入。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 用户、电影和评分数据
users = ["张三", "李四", "王五"]
movies = ["盗梦空间", "星际穿越", "黑客帝国"]
ratings = [
("张三", "盗梦空间", 5),
("张三", "黑客帝国", 4),
("李四", "盗梦空间", 4),
("李四", "星际穿越", 5),
("王五", "黑客帝国", 5),
]
uri = "bolt://localhost:7687"
auth = ("neo4j", "12345678")
driver = GraphDatabase.driver(uri, auth=auth)
with driver.session(database="first") as session:
# 批量创建用户节点
for name in users:
session.run("MERGE (u:User {name: $name})", {"name": name})
# 批量创建电影节点
for title in movies:
session.run("MERGE (m:Movie {title: $title})", {"title": title})
# 批量创建评分关系
for uname, mtitle, score in ratings:
session.run(
"MATCH (u:User {name: $uname}), (m:Movie {title: $mtitle}) "
"MERGE (u)-[:RATED {score: $score}]->(m)",
{"uname": uname, "mtitle": mtitle, "score": score},
)
driver.close()
MERGE可以避免重复插入,适合批量导入。
MATCH 用于查找已存在的节点或关系,如果找不到则什么都不做; MERGE 则是“查找或创建”,如果不存在就自动创建,存在则直接返回。
10.4 常见用法: #
// 只查找,不创建
MATCH (u:User {name: 'Alice'}) RETURN u
// 查找,不存在则创建
MERGE (u:User {name: 'Alice'}) RETURN u- 批量导入时,推荐用MERGE,避免重复插入同名用户或电影。
- 如果只想操作已存在的数据,用MATCH。
- MERGE会根据你写的属性唯一性来判断是否“重复”。
10.4.1 MERGE的工作原理 #
MERGE操作相当于"查找或创建":
- 首先尝试匹配完整的模式(包括节点标签和指定的属性)
- 如果匹配不到,则创建新节点/关系
- 如果匹配到,则不做任何改变
session.run("MERGE (u:User {name: $name})", {"name": name})这表示:查找一个具有User标签且name属性等于指定值的节点,如果不存在则创建。
10.4.2 判断重复的依据 #
不是变量名(变量名只在当前查询中有效),而是基于:
- 节点标签(label) + 指定的属性组合
在这个例子中就是
User标签 +name属性值
10.4.3 节点ID #
Neo4j确实有内部ID(称为element ID),但:
- 不是用来判断重复的
- 是自动分配的不可变标识符
- 可以通过
id()函数查询(如RETURN id(node)) - 但最佳实践是不依赖这个ID,而是用业务属性(如你的
name)
10.4.4 重复的判断 #
- 用户节点:通过
User标签 +name属性唯一标识 - 电影节点:通过
Movie标签 +title属性唯一标识 - 评分关系:通过确保两端节点唯一 + 关系类型
RATED来避免重复
10.4.5 重要注意事项 #
- 如果多个节点有相同标签和相同属性值,
MERGE会匹配任意一个(不一定是第一个) - 对于关系,
MERGE会检查完整的模式(包括两端节点和关系类型/属性) - 最佳实践是为常用查询属性创建约束:
这样能保证CREATE CONSTRAINT unique_user_name FOR (u:User) REQUIRE u.name IS UNIQUEname真正唯一,且会创建索引提高查询速度
10.4 推荐算法:基于用户喜好的推荐 #
最简单的推荐算法是“协同过滤”:推荐与目标用户兴趣相似的其他用户喜欢的电影。例如:
- 协同过滤:一种推荐算法,基于用户之间的兴趣相似性进行推荐。
- count(*):统计分组后每组的数量。
- 分组(GROUP BY):将结果按某个字段分组统计。
// 匹配名为“张三”的用户u1与其评分过的电影m,以及其他同样评分过该电影的用户u2
MATCH (u1:User {name: '张三'})-[:RATED]->(m:Movie)<-[:rated]-(u2:user) where u1 <> u2
WITH u1, u2
MATCH (u2)-[:RATED]->(rec:Movie)
WHERE NOT ( (u1)-[:RATED]->(rec) )
RETURN rec.title AS 推荐电影, count(*) AS 推荐次数
ORDER BY 推荐次数 DESC
LIMIT 5你可以用Python调用此Cypher语句,动态替换用户名,实现个性化推荐。
查询说明:
MATCH (u1:User {name: '张三'})-[:RATED]->(m:Movie)<-[:RATED]-(u2:User)匹配名为“张三”的用户u1,找到他评分过的所有电影m,再找到同样评分过这些电影的其他用户u2。WHERE u1 <> u2排除u1和u2为同一用户的情况,避免自推荐。WITH u1, u2将u1和u2传递到下一个查询阶段,便于后续继续使用这两个变量。MATCH (u2)-[:RATED]->(rec:Movie)匹配u2评分过的所有电影rec,作为候选推荐电影。WHERE NOT ( (u1)-[:RATED]->(rec) )过滤掉u1已经评分过的电影,只推荐u1没看过的。RETURN rec.title AS 推荐电影, count(*) AS 推荐次数返回每部被推荐的电影标题,以及被推荐的理由(次数)。ORDER BY 推荐次数 DESC按推荐理由(次数)降序排列,把最有可能喜欢的电影排在前面。LIMIT 5只取前5条推荐结果,避免结果过多。
常用Cypher关键字:
MATCH:模式匹配,查找节点和关系。WHERE:条件过滤,支持属性、变量比较和NOT等逻辑。WITH:将变量传递到下一个查询阶段,常用于分步处理。NOT:逻辑非,用于排除已存在的关系。RETURN:指定返回哪些字段。ORDER BY:结果排序。LIMIT:限制返回结果数量。
10.5 推荐算法常见疑问与解答(FAQ) #
Q:WITH在这里是什么意思?
WITH用于将变量传递到下一个查询阶段,常用于分步处理。
Q:count(*) 在这里是什么意思?
count(*)表示统计每部被推荐电影出现的次数,也就是有多少个兴趣相似的用户推荐了这部电影。次数越多,推荐理由越充分。
- Q:这样的查询只能返回一个电影吗?
- 不是。查询会返回多部电影,每部电影一行,带上推荐理由(次数)。通过
ORDER BY排序,LIMIT控制返回数量。
- 不是。查询会返回多部电影,每部电影一行,带上推荐理由(次数)。通过
- Q:u2 是什么类型?是数组吗?
u2不是数组,而是单个用户节点变量。Cypher 会自动遍历所有满足条件的用户,每次循环u2代表其中一个用户。如果想得到所有兴趣相似的用户,可以用collect(u2)变成数组。
- Q:RETURN rec.title, count(*) 是不是类似于分组?
- 是的。Cypher 里
RETURN rec.title, count(*)实际上就是按rec.title分组,统计每部电影被推荐的次数,类似于 SQL 的GROUP BY rec.title。
- 是的。Cypher 里
小结: 推荐算法的 Cypher 查询结果会返回多部电影,每部电影的推荐理由次数由
count(*)统计。u2是单个用户节点,分组统计由RETURN ... , count(*)自动完成。
11. 社交网络分析 #
用Neo4j分析社交网络,挖掘朋友关系和影响力用户
11.1 项目介绍:分析朋友关系网络 #
本项目将用Neo4j构建和分析一个简单的社交网络。通过用户之间的好友关系,探索社交网络结构、查找多级朋友、识别影响力用户等。
- 掌握社交网络的图建模方法
- 体验多跳查询和网络分析
- 理解影响力用户的判定思路
11.2 创建社交网络:用户和好友关系 #
社交网络常用的图模型:
User(用户)节点FRIEND(好友)关系,连接两个用户
- FRIEND关系:表示用户之间的好友关系,可以是有向或无向。
- 节点(Node):图中的实体对象。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 创建会话,指定使用的数据库为"first"
with driver.session(database="first") as session:
session.run(
"""
// 创建用户节点
CREATE (a:User {name: '张三'}), (b:User {name: '李四'}), (c:User {name: '王五'})
// 创建好友关系
CREATE (a)-[:FRIEND]->(b), (b)-[:FRIEND]->(c), (c)-[:FRIEND]->(a)
"""
)
# 关闭数据库驱动,释放资源
driver.close()
FRIEND关系可以是有向或无向,实际建模时可根据业务需求选择。
11.3 查找朋友:多跳查询 #
用Cypher可以轻松查找某个用户的直接朋友、朋友的朋友(2跳)、甚至N跳关系:
- 多跳查询:通过多级关系查找间接连接的节点。
- 星号语法(*):用于指定关系的跳数范围。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 创建会话,指定使用的数据库为"first"
with driver.session(database="first") as session:
result1 = session.run(
"""
// 查找张三的所有直接朋友
MATCH (a:User {name: '张三'})-[:FRIEND]->(f:User)
RETURN f.name
"""
)
print(result1.data())
result2 = session.run(
"""
// 查找张三的2跳朋友(朋友的朋友)
MATCH (a:User {name: '张三'})-[:FRIEND*2]->(f:User)
RETURN f.name
"""
)
print(result2.data())
result2 = session.run(
"""
// 查找张三的N跳朋友(N为具体数字,如3)
MATCH (a:User {name: '张三'})-[:FRIEND*1..3]->(f:User)
RETURN DISTINCT f.name
"""
)
print(result2.data())
# 关闭数据库驱动,释放资源
driver.close()
[:FRIEND*2]表示2跳关系,[:FRIEND*1..N]表示1到N跳的所有路径。
11.4 网络分析:找出影响力用户 #
影响力用户通常是指拥有较多朋友、或在网络中处于关键位置的用户。常见分析方法:
- 度中心性:统计每个用户的直接朋友数量
PageRank:衡量节点在网络中的重要性(Neo4j自带算法)
度中心性(Degree Centrality):节点的直接连接数,衡量“活跃度”。
- PageRank:衡量节点在网络中重要性的算法。
- GDS插件:Neo4j Graph Data Science插件,提供丰富的图算法。
- 图投影(Graph Projection):将数据库中的节点和关系临时复制到内存中,便于高效分析。
// 创建一个名为'myGraph'的图投影,包含所有User节点和FRIEND关系
CALL gds.graph.project(
'myGraph',
'User',
'FRIEND'
)
// 在'myGraph'图上执行PageRank算法,计算每个用户节点的影响力分数
CALL gds.pageRank.stream('myGraph')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS 用户, score AS PageRank
ORDER BY score DESC
LIMIT 5
// 删除'myGraph'图投影,释放资源
CALL gds.graph.drop('myGraph')PageRank 需要Neo4j GDS插件,适合大规模网络分析。
关键说明:
gds.graph.project:创建图投影,指定节点和关系类型。gds.pageRank.stream:在图投影上执行PageRank算法。YIELD:指定要输出的字段。RETURN:返回结果。ORDER BY:排序。LIMIT:限制返回数量。gds.graph.drop:删除图投影,释放资源。
11.5 图投影与PageRank算法 #
11.5.1 什么是图投影(Graph Projection)? #
在Neo4j GDS(Graph Data Science)库中,图投影是将数据库中的节点和关系,临时复制到内存中形成一个“分析用的图”。这样可以高效地运行各种图算法,而不会影响原始数据。
- 分析用的图:内存中的临时图结构,仅用于算法分析。
原始数据:数据库中实际存储的数据。
用
gds.graph.project创建图投影,指定要分析的节点标签和关系类型。- 图投影只存在于内存,分析完后建议用
gds.graph.drop释放资源。 - 你可以为不同分析任务创建不同的图投影。
11.5.2 PageRank算法原理 #
PageRank 是一种经典的网络分析算法,最早由Google提出,用于衡量网页(节点)在网络中的重要性。在社交网络中,PageRank分数高的用户通常是“影响力大”的用户。
- PageRank会综合考虑“有多少人指向你”以及“指向你的人本身有多重要”。
- 分数高的节点往往是网络中的“核心人物”或“信息枢纽”。
- PageRank适合分析大规模网络的影响力分布。
11.6 APOC (Awesome Procedures On Cypher) #
APOC 是 Neo4j 最受欢迎的标准库,提供约 450 个存储过程和函数,极大扩展了 Cypher 的功能。您安装的是 2025.06.1-core 版本。
11.6.1 APOC 核心功能分类 #
11.6.1.1 数据导入/导出 #
文件操作:读写 CSV、JSON、XML 等
CALL apoc.load.json('https://api.example.com/data') YIELD value数据库迁移:导出/导入整个数据库
CALL apoc.export.cypher.all("export.cypher")
11.6.1.2 图算法 #
路径查找:Dijkstra、A* 等
MATCH (start:Place{name:'A'}), (end:Place{name:'D'}) CALL apoc.algo.dijkstra(start, end, 'ROAD', 'distance') YIELD path, weight社区检测:Louvain、Label Propagation
CALL apoc.algo.community(25, null, 'partition', 'KNOWS')
11.6.1.3 数据处理 #
集合操作:去重、交集、随机选择
RETURN apoc.coll.intersection([1,2,3], [2,3,4])Map 操作:合并、提取键
RETURN apoc.map.merge({a:1}, {b:2})
11.6.1.4 高级查询 #
并行执行:提高查询速度
CALL apoc.cypher.parallel( 'MATCH (n:User) RETURN n.name', {}, 'name' )模式匹配:动态关系查询
CALL apoc.path.subgraphAll( startNode, {relationshipFilter: 'FRIEND>|WORKS_WITH>'} )
11.6.2 安装与配置 #
- 版本兼容性:必须与 Neo4j 版本匹配
- 启用配置:
dbms.security.procedures.unrestricted=apoc.* apoc.import.file.enabled=true
11.7 Neo4j Graph Data Science (GDS) #
GDS 是 Neo4j 官方图数据科学库,专为大规模图分析设计,提供高性能的图算法和机器学习能力。
11.7.1 核心架构 #
11.7.1.1 内存图模型 #
- 投影图(Projected Graph):将Neo4j数据加载为优化的内存结构
- 压缩存储:使用位图、压缩邻接表等节省内存
- 并行计算:所有算法都支持多线程执行
11.7.1.2 工作流程 #
加载图 → 执行算法 → 结果写回/返回 → 机器学习11.7.2 算法分类 #
11.7.2.1 中心性算法 (Centrality) #
| 算法 | 用途 | 复杂度 |
|---|---|---|
| PageRank | 网页排名 | O(kN) |
| Betweenness | 中介中心性 | O(N²) |
| ArticleRank | 改进版PageRank | O(kN) |
# 调用GDS库的PageRank算法,并将结果写回图中
# 'myGraph' 是要分析的图投影名称
# maxIterations: 设定最大迭代次数为20
# writeProperty: 结果写入节点属性'pagerank'
CALL gds.pageRank.write('myGraph', {
maxIterations: 20,
writeProperty: 'pagerank'
})11.7.2.2 路径查找 (Path Finding) #
- Dijkstra:带权最短路径
- A*:启发式最短路径
- Yen's K-Shortest Paths:Top K最短路径
// 匹配名称为'Berlin'和'Munich'的城市节点,分别赋值为a和b
MATCH (a:City {name: 'Berlin'}), (b:City {name: 'Munich'})
// 调用GDS库的Dijkstra最短路径算法,使用stream模式输出结果
CALL gds.shortestPath.dijkstra.stream({
// 指定节点查询,返回所有城市节点的id
nodeQuery: 'MATCH (c:City) RETURN id(c) AS id',
// 指定关系查询,返回所有城市之间道路的起点、终点及距离作为权重
relationshipQuery: 'MATCH (c1:City)-[r:ROAD]->(c2:City) RETURN id(c1) AS source, id(c2) AS target, r.distance AS weight',
// 设置起点为a(Berlin)
sourceNode: a,
// 设置终点为b(Munich)
targetNode: b
})
// 提取算法输出的相关字段
YIELD index, sourceNode, targetNode, totalCost, nodeIds, costs
// 返回路径上所有节点的名称和总花费
RETURN [nodeId IN nodeIds | gds.util.asNode(nodeId).name] AS path, totalCost12. 复杂查询 #
掌握Cypher的多跳、路径、聚合、排序等高级查询技巧
12.1 多跳查询:查找间接关系 #
多跳查询用于查找节点之间的间接关系,比如“朋友的朋友”。
- 多跳查询:通过多级关系查找间接连接的节点。
- DISTINCT:去重关键字,避免重复返回同一个节点。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 创建会话,指定使用的数据库为"first"
with driver.session(database="first") as session:
result1 = session.run(
"""
// 查找张三的2跳朋友(朋友的朋友)
MATCH (a:User {name: '张三'})-[:FRIEND*2]->(f:User)
RETURN f.name
"""
)
print(result1.data())
# 关闭数据库驱动,释放资源
driver.close()# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 创建会话,指定使用的数据库为"first"
with driver.session(database="first") as session:
result1 = session.run(
"""
// 查找张三的2跳朋友(朋友的朋友)
MATCH (a:User {name: '张三'})-[:FRIEND*2]->(f:User)
RETURN f.name
"""
)
print(result1.data())
# 关闭数据库驱动,释放资源
driver.close()# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 创建会话,指定使用的数据库为"first"
with driver.session(database="first") as session:
result1 = session.run(
"""
// 查找张三1到3跳范围内的所有朋友,去重
MATCH (a:User {name: '张三'})-[:FRIEND*1..3]->(f:User)
RETURN DISTINCT f.name
"""
)
print(result1.data())
# 关闭数据库驱动,释放资源
driver.close()
[:FRIEND*2]表示正好2跳,[:FRIEND*1..3]表示1到3跳的所有路径。DISTINCT去重,避免重复返回同一个朋友。
12.2 路径查询:找到两个节点之间的路径 #
路径查询可以找到两个节点之间的所有路径或最短路径。
- 路径(Path):节点之间通过关系连接形成的有序节点序列。
- 最短路径:经过关系数量最少或权重和最小的路径。
- APOC:Neo4j的扩展库,提供丰富的算法和工具函数。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 创建会话,指定使用的数据库为"first"
with driver.session(database="first") as session:
result1 = session.run(
"""
// 查找张三到王五之间的所有路径(最多4跳)
MATCH p = (a:User {name: '张三'})-[:FRIEND*1..4]->(b:User {name: '王五'})
RETURN p
"""
)
print(result1.data())
# [{'p': [{'name': '张三'}, 'FRIEND', {'name': '李四'}, 'FRIEND', {'name': '王五'}]}]
# 关闭数据库驱动,释放资源
driver.close()# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 创建会话,指定使用的数据库为"first"
with driver.session(database="first") as session:
result1 = session.run(
"""
// 查找张三到王五的最短路径(需APOC插件,带权重)
MATCH (a:User {name: '张三3'}), (b:User {name: '王五3'})
CALL apoc.algo.dijkstra(a, b, 'FRIEND', 'weight') YIELD path, weight
RETURN path, weight
"""
)
print(result1.data())
#
driver.close()
apoc.algo.dijkstra需安装APOC插件,支持带权重的最短路径。
12.2.1 什么是带权重的最短路径? #
- 最短路径通常指经过的关系(边)数量最少的路径。
- 带权重的最短路径是指每条关系有一个“权重”属性(如距离、花费、时间等),算法会找出所有权重之和最小的路径。
- 如地图中,权重可代表距离,最短路径就是距离最短的路线。
- 在社交网络中,权重可代表关系强度、互动频率等。
- APOC的dijkstra算法会自动累加每条边的weight,找出总和最小的路径。
12.2.2 为什么weight是NaN? #
- 你的关系上没有
weight属性,或属性为null。 - 属性名拼写不一致(如写成了weights、Weight等)。
- weight属性不是数字类型。
12.2.3 解决方法 #
- 确保所有相关关系都有数值型的
weight属性,例如:// 创建带权重的FRIEND关系 CREATE (a)-[:FRIEND {weight: 1.0}]->(b) - 批量给已有关系加默认权重:
// 给所有没有weight属性的FRIEND关系设置默认权重1.0 MATCH ()-[r:FRIEND]->() WHERE r.weight IS NULL SET r.weight = 1.0 - 确认APOC算法里用的属性名和实际属性名完全一致。
小结: 带权重的最短路径能表达更丰富的业务含义。weight为NaN多因数据缺失或属性名错误,补齐属性即可解决。
12.3 聚合查询:统计和分组 #
聚合查询用于统计节点数量、分组计数、求和、平均等。
- 聚合函数:如count、sum、avg等,用于统计和汇总数据。
- 分组(GROUP BY):按某个字段将结果分组统计。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 创建会话,指定使用的数据库为"first"
with driver.session(database="first") as session:
result1 = session.run(
"""
// 统计每个用户的朋友数量,并按朋友数降序排列
MATCH (u:User)-[:FRIEND]->(f:User)
RETURN u.name, count(f) AS 朋友数
ORDER BY 朋友数 DESC
"""
)
print(result1.data())
# [{'path': [{'name': '张三3'}, 'FRIEND', {'name': '王五3'}], 'weight': 1.0}]
driver.close()
count()统计数量,ORDER BY排序,AS给返回列起别名。
12.4 排序和分页:LIMIT和ORDER BY #
排序和分页常用于大数据量结果的展示。
- ORDER BY:结果排序关键字。
- LIMIT:限制返回条数。
- SKIP:跳过前N条,实现分页。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 创建会话,指定使用的数据库为"first"
with driver.session(database="first") as session:
result1 = session.run(
"""
// 查询朋友数最多的前5个用户
MATCH (u:User)-[:FRIEND]->(f:User)
RETURN u.name, count(f) AS 朋友数
ORDER BY 朋友数 DESC
LIMIT 5
"""
)
print(result1.data())
driver.close()
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 创建会话,指定使用的数据库为"first"
with driver.session(database="first") as session:
result1 = session.run(
"""
// 分页查询(每页5条,第2页)
MATCH (u:User)-[:FRIEND]->(f:User)
RETURN u.name, count(f) AS 朋友数
ORDER BY 朋友数 DESC
SKIP 5 LIMIT 5
"""
)
print(result1.data())
driver.close()
ORDER BY排序,LIMIT限制返回条数,SKIP跳过前N条实现分页。
12.5 字符串匹配与正则表达式 #
- CONTAINS:判断字符串是否包含子串。
- STARTS WITH / ENDS WITH:判断字符串是否以某子串开头/结尾。
- =~:正则表达式匹配。
// 查找名字中包含“张”的用户
MATCH (u:User)
WHERE u.name CONTAINS '张'
RETURN u.name
// 查找名字以“王”开头的用户
MATCH (u:User)
WHERE u.name STARTS WITH '王'
RETURN u.name
// 查找名字以“明”结尾的用户
MATCH (u:User)
WHERE u.name ENDS WITH '明'
RETURN u.name
// 正则匹配:名字为2-3个汉字的用户
MATCH (u:User)
WHERE u.name =~ '^[\u4e00-\u9fa5]{2,3}$'
RETURN u.name12.6 IN 关键字 #
- IN:判断某个值是否在列表中,类似SQL的IN。
// 查找名字为“张三”或“李四”的用户
MATCH (u:User)
WHERE u.name IN ['张三', '李四']
RETURN u.name12.7 exists 子查询与EXISTS函数 #
- exists():判断属性或关系是否存在。
- EXISTS 子查询:Cypher 4.x+ 支持子查询。
// 查找有email属性的用户
MATCH (u:User)
WHERE u.email IS NOT NULL
RETURN u.name, u.email
// EXISTS子查询:查找有朋友的用户
MATCH (u:User)
WHERE EXISTS { MATCH (u)-[:FRIEND]->(:User) }
RETURN u.name12.8 OPTIONAL MATCH(可选匹配) #
- OPTIONAL MATCH:类似SQL的左外连接,匹配不到时返回null。
// 查询所有用户及其邮箱(有的可能没有邮箱)
MATCH (u:User)
OPTIONAL MATCH (u)-[:HAS_EMAIL]->(e:Email)
RETURN u.name, e.address12.9 toUpper、coalesce 等常用函数 #
- toUpper():转为大写。
- coalesce():返回第一个非null值。
// 查询所有用户姓名(大写显示)
MATCH (u:User)
RETURN toUpper(u.name) AS 姓名大写
// 查询用户邮箱,若无则显示“无邮箱”
MATCH (u:User)
OPTIONAL MATCH (u)-[:HAS_EMAIL]->(e:Email)
RETURN u.name, coalesce(e.address, '无邮箱') AS 邮箱12.10 collect、unwind、size #
- collect():聚合为列表。
- unwind:将列表展开为多行。
- size():计算列表长度。
// 查询每个用户的所有朋友姓名(聚合为列表)
MATCH (u:User)-[:FRIEND]->(f:User)
RETURN u.name, collect(f.name) AS 朋友列表
// 将列表展开为多行
WITH ['张三', '李四', '王五'] AS names
UNWIND names AS name
RETURN name
// 查询每个用户的朋友数量
MATCH (u:User)-[:FRIEND]->(f:User)
RETURN u.name, size(collect(f)) AS 朋友数12.11 REMOVE 删除属性/标签 #
- REMOVE:删除节点/关系的属性或标签。
// 删除张三的email属性
MATCH (u:User {name: '张三'})
REMOVE u.email
RETURN u
// 删除VIP标签
MATCH (u:User:VIP)
REMOVE u:VIP
RETURN u12.12 ON CREATE / ON MATCH #
- ON CREATE SET:MERGE新建时设置属性。
- ON MATCH SET:MERGE匹配到已有时设置属性。
// 新建用户时设置注册时间,已存在则更新时间
MERGE (u:User {name: '赵六'})
ON CREATE SET u.created = date()
ON MATCH SET u.lastLogin = date()
RETURN u12.13 UNION 合并多查询结果 #
- UNION:合并多条查询结果,去重。
- UNION ALL:合并多条查询结果,不去重。
// 查询所有User和Book节点的名字/标题
MATCH (u:User) RETURN u.name AS 名称
UNION
MATCH (b:Book) RETURN b.title AS 名称12.14 WITH 变量传递与分组 #
- WITH:用于分步处理、变量传递、分组聚合。
// 查询朋友数大于1的用户
MATCH (u:User)-[:FRIEND]->(f:User)
WITH u, count(f) AS 朋友数
WHERE 朋友数 > 1
RETURN u.name, 朋友数12.15 COUNT 计数 #
- count():统计数量。
// 统计用户总数
MATCH (u:User)
RETURN count(u) AS 用户总数12.16 CALL 调用过程/子查询 #
- CALL:调用APOC等过程,或执行子查询。
// 子查询:统计每个用户的朋友数
MATCH (u:User)
CALL {
WITH u
MATCH (u)-[:FRIEND]->(f:User)
RETURN count(f) AS 朋友数
}
RETURN u.name, 朋友数12.17 Python调用Cypher高级查询示例 #
# 导入neo4j驱动包
from neo4j import GraphDatabase
# 设置数据库连接的URI
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 打开名为"first"的数据库会话
with driver.session(database="first") as session:
# 执行Cypher查询,查找名字中包含“张”的用户
result = session.run(
"""
MATCH (u:User) WHERE u.name CONTAINS '张' RETURN u.name
"""
)
# 打印查询结果
print(result.data())
# 执行Cypher查询,查找每个用户的所有朋友,并统计朋友数量
result = session.run(
"""
MATCH (u:User)-[:FRIEND]->(f:User)
RETURN u.name, collect(f.name) AS 朋友列表, size(collect(f)) AS 朋友数
"""
)
# 打印查询结果
print(result.data())
# 执行Cypher查询,合并名为“赵六”的用户节点
# 如果节点不存在则创建,并设置created属性为当前日期
# 如果节点已存在,则更新lastLogin属性为当前日期
result = session.run(
"""
MERGE (u:User {name: '赵六'})
ON CREATE SET u.created = date()
ON MATCH SET u.lastLogin = date()
RETURN u
"""
)
# 打印查询结果
print(result.data())
# 关闭数据库驱动连接
driver.close()13. 数据更新和删除 #
掌握Cypher的节点属性更新、删除、合并与批量操作
13.1 更新节点属性:SET语句 #
SET语句用于修改节点或关系的属性。
- SET:Cypher中的关键字,用于新增或修改节点/关系的属性。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 创建会话,指定使用的数据库为"first"
with driver.session(database="first") as session:
result1 = session.run(
"""
// 修改张三的年龄为30
MATCH (p:User {name: '张三'})
SET p.age = 30
RETURN p
"""
)
print(result1.data())
# [{'path': [{'name': '张三3'}, 'FRIEND', {'name': '王五3'}], 'weight': 1.0}]
driver.close()# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 创建会话,指定使用的数据库为"first"
with driver.session(database="first") as session:
result1 = session.run(
"""
// 增加或修改多个属性
MATCH (p:User {name: '张三'})
SET p.city = '北京', p.email = 'zhangsan@email.com'
RETURN p
"""
)
print(result1.data())
driver.close()
SET 可用于新增、修改属性,多个属性用逗号分隔。
13.2 删除节点和关系:DELETE语句 #
DELETE语句用于删除节点或关系。
- DELETE:Cypher中的关键字,用于删除节点或关系。
- DETACH DELETE:强制删除节点及其所有关系。
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 创建会话,指定使用的数据库为"first"
with driver.session(database="first") as session:
result1 = session.run(
"""
// 删除张三节点(前提:没有任何关系)
MATCH (p:User {name: '张三'})
DELETE p
// 删除张三与李四之间的好友关系
MATCH (a:User {name: '张三'})-[r:FRIEND]->(b:User {name: '李四'})
DELETE r
// 强制删除张三及其所有关系
MATCH (p:User {name: '张三'})
DETACH DELETE p
"""
)
print(result1.data())
driver.close()
DELETE 只能删除无关系的节点,DETACH DELETE 可强制删除节点及其所有关系。
13.3 合并操作:MERGE语句 #
MERGE语句用于“查找或创建”节点或关系,避免重复。
- MERGE:Cypher中的关键字,查找或创建节点/关系,防止重复。
// 查找或创建用户节点
MERGE (p:User {name: '王五'})
RETURN p
// 查找或创建好友关系
MATCH (a:User {name: '张三'}), (b:User {name: '李四'})
MERGE (a)-[:FRIEND]->(b)MERGE 适合批量导入和防止重复数据。
13.4 批量操作:提高效率 #
Cypher支持批量更新、删除和合并,适合大数据量操作。
- 批量操作:一次性对多条数据进行更新、删除或合并。
// 批量修改所有用户的城市为“北京”
MATCH (u:User)
SET u.city = '北京'
// 批量删除所有没有朋友的用户
MATCH (u:User)
WHERE NOT (u)-[:FRIEND]-()
DETACH DELETE u批量操作可大幅提升数据处理效率,注意操作前备份重要数据。
14. 数据导入导出 #
掌握Neo4j的CSV、JSON数据导入导出与备份技巧
14.1 CSV文件导入:批量导入数据 #
Neo4j支持通过LOAD CSV语句批量导入数据,适合大规模节点和关系的创建。
- LOAD CSV:Cypher中的批量数据导入命令,支持本地和远程CSV文件。
- WITH HEADERS:指定CSV文件首行为表头。
toInteger():类型转换函数,将字符串转为整数。
// 假设有users.csv文件,内容如下:
// name,age,city
// 张三,25,北京
// 李四,30,上海
// 导入本地用户节点
// 需要把users.csv文件放在NEO4J_HOME/import目录下
LOAD CSV WITH HEADERS FROM 'file:///users.csv' AS row
CREATE (:User {name: row.name, age: toInteger(row.age), city: row.city})
// 导入远程用户节点
LOAD CSV WITH HEADERS FROM 'https://static.docs-hub.com/users_1753115663538.csv' AS row
CREATE (:User {name: row.name, age: toInteger(row.age), city: row.city})
LOAD CSV支持本地和远程文件,WITH HEADERS表示首行为表头,toInteger()用于类型转换。
14.1.1 如何找到Neo4j的安装目录 #
which neo4j # Linux/macOS
where neo4j # Windows
C:\Users\Administrator\.Neo4jDesktop2\Data\dbmss\dbms-d0096b5c-7748-4043-a013-709f9bf9e9b6\bin\neo4j.bat14.1.2 如何找到Neo4j的配置文件 #
C:\Users\Administrator.Neo4jDesktop2\Data\dbmss\dbms-d0096b5c-7748-4043-a013-709f9bf9e9b6\conf\neo4j.conf
# 定义 Neo4j 导入文件(如 CSV)的默认目录
# 默认情况下,Neo4j 只允许从该目录(或子目录)导入文件,以增强安全性
# 默认路径:/import
# users.csv 必须放在 /import 目录下,否则会报错。
server.directories.import=import
# 控制是否允许从 任意本地文件路径 导入 CSV(而不仅限于 import 目录)
# 默认关闭(false),出于安全考虑,防止恶意文件读取。
dbms.security.allow_csv_import_from_file_urls=true 14.2 JSON数据处理:处理复杂数据结构 #
Neo4j可通过APOC插件处理JSON数据,适合导入复杂结构或与外部系统集成。
- APOC:Neo4j的扩展库,提供丰富的数据处理和算法能力。
- apoc.load.json:APOC中的过程,用于加载本地或远程JSON数据。
- UNWIND:Cypher中的关键字,用于将列表展开为多行。
// 导入远程JSON数据
CALL apoc.load.json('https://static.docs-hub.com/data_1753115997917.json') YIELD value
RETURN value
// 解析JSON并创建用户节点
CALL apoc.load.json('https://static.docs-hub.com/data_1753115997917.json') YIELD value
UNWIND value.users AS user
CREATE (:User {name: user.name, age: user.age})
apoc.load.json可加载本地或远程JSON,UNWIND用于展开数组。
14.2.1. CALL apoc.load.json() #
- 使用 APOC 库的
apoc.load.json过程从指定 URL 加载 JSON 数据 YIELD value表示将加载的 JSON 数据赋值给变量value
14.2.2. UNWIND #
UNWIND是 Cypher 中用于"展开"列表的操作- 这里将
value.users数组展开,为数组中的每个元素创建一行 - 每行赋值给变量 `user
执行 UNWIND 后,相当于生成了以下数据流:
user = {"name": "张三", "age": 30}
user = {"name": "李四", "age": 25}
user = {"name": "王五", "age": 35}14.2.3. CREATE (:User {name: user.name, age: user.age}) #
- 为
UNWIND生成的每一行数据创建一个User节点 - 节点属性从
user变量中提取
14.3 数据导出:保存查询结果 #
Neo4j可通过APOC或导出工具将查询结果保存为CSV、JSON等格式。
- apoc.export.csv.query:APOC中的过程,将查询结果导出为CSV文件。
- apoc.export.json.all:APOC中的过程,将整个数据库导出为JSON文件。
// 导出查询结果为CSV(需APOC插件)
CALL apoc.export.csv.query(
'MATCH (u:User)-[:FRIEND]->(f:User) RETURN u.name, f.name',
'users_friends.csv',
{})
// 导出整个数据库为JSON
CALL apoc.export.json.all('alldb.json', {})
apoc.export.*系列支持多种格式导出,文件路径需在Neo4j允许的导出目录下。
14.3.1. 默认存储位置 #
文件会保存到 Neo4j 的 import 目录中,具体路径取决于:
- Neo4j 安装目录下的
import文件夹(如/var/lib/neo4j/import) - 通过
dbms.directories.import配置项指定的自定义路径
14.3.2. APOC 配置文件 #
C:\Users\Administrator.Neo4jDesktop2\Data\dbmss\dbms-d0096b5c-7748-4043-a013-709f9bf9e9b6\conf\apoc.conf
dbms-d0096b5c-7748-4043-a013-709f9bf9e9b6是数据库实例的唯一标识符conf目录包含所有配置文件apoc.conf专门用于 APOC 插件的配置,用于配置 APOC 插件的导出和导入功能
# 启用APOC文件导出功能
apoc.export.file.enabled=true
# 让 APOC 继承 Neo4j 主配置文件的安全设置,使用 neo4j.conf 中定义的 dbms.directories.import 路径
apoc.import.file.use_neo4j_config=true15. 性能优化基础 #
掌握Neo4j数据库的索引、查询优化、内存管理与监控工具,提升系统性能
15.1 索引创建:提高查询速度 #
索引(Index)可以极大提升查询效率,尤其是在数据量较大时。Neo4j支持为节点的属性创建索引,使得查找特定属性值的节点变得更快。
- 索引(Index):加速节点或关系属性查找的数据结构。
- SHOW INDEXES:显示当前所有索引。
- DROP INDEX:删除指定索引。
创建索引
// 为Person标签的name属性创建索引
CREATE INDEX FOR (n:Person) ON (n.name);上述语句为Person标签的name属性创建索引。
查看索引
// 查看所有已创建的索引
SHOW INDEXES;删除索引
// 删除指定索引(index_f7700477为索引名,实际以SHOW INDEXES结果为准)
DROP INDEX index_f7700477;建议:为经常作为查询条件的属性建立索引,但不要为所有属性都建索引,否则会影响写入性能。
15.2 查询优化:编写高效的查询 #
高效的Cypher查询可以显著提升数据库性能。常见优化方法包括:
- 优先使用索引属性进行筛选
- 减少不必要的节点和关系遍历
- 只返回需要的字段,避免
RETURN * - 合理使用
LIMIT和ORDER BY
- EXPLAIN:分析查询计划,不实际执行查询。
- 查询复杂度:衡量查询消耗的资源和时间,常用大O符号表示。
示例:高效查询
// 不推荐:返回所有Person节点,消耗大
MATCH (n:Person) RETURN n;
// 推荐:只查找name为'张三'的节点,并只返回需要的字段
MATCH (n:Person) WHERE n.name = '张三' RETURN n.name, n.age;查询计划分析
// 查看查询的执行计划,不实际执行
EXPLAIN MATCH (n:Person) WHERE n.name = '张三' RETURN n;查询复杂度可用大O符号表示:
$$ O(n) < O(n^2) $$
优化目标是让查询复杂度尽量低。
15.3 内存管理:合理使用资源 #
Neo4j运行时会消耗大量内存,合理配置内存参数可以提升性能并避免崩溃。
- 堆内存(heap):JVM用于对象分配和垃圾回收的内存区域。
- 页面缓存(pagecache):用于缓存磁盘数据页,加速数据访问。
- neo4j.conf:Neo4j的主配置文件。
常用内存参数
dbms.memory.heap.initial_size:堆内存初始值dbms.memory.heap.max_size:堆内存最大值dbms.memory.pagecache.size:页面缓存大小
这些参数可在neo4j.conf文件中设置。例如:
# 设置JVM堆内存初始值为2G
# 设置JVM堆内存最大值为4G
# 设置页面缓存为2G
dbms.memory.heap.initial_size=2G
dbms.memory.heap.max_size=4G
dbms.memory.pagecache.size=2G内存分配建议:
$$ \text{总内存} = \text{堆内存} + \text{页面缓存} + \text{系统预留} $$
注意:不要将所有内存分配给Neo4j,需为操作系统和其他进程预留空间。
16. 图书管理系统 #
16.1 项目需求分析 #
- 用户可以借阅和归还图书
- 系统记录每本书的借阅情况
- 支持图书推荐功能(如:基于借阅历史推荐)
- 管理员可以添加、删除图书
16.2 数据模型设计 #
主要实体与关系:
- 用户(User):有姓名、账号等属性
- 图书(Book):有书名、作者、ISBN等属性
- 借阅(BORROWED):用户与图书之间的关系,包含借阅时间、归还时间等属性
- BORROWED关系:表示用户与图书之间的借阅关系,可包含借阅时间、归还时间等属性。
- ISBN:国际标准书号,唯一标识一本书。
图模型示意:
User --[BORROWED]--> BookCypher建模示例
// 创建用户节点
CREATE (u:User {name: '张三', account: 'zhangsan'})
// 创建图书节点
CREATE (b:Book {title: '数据结构', author: '王五', isbn: '9781234567890'})
// 创建借阅关系,设置借阅日期
MATCH (u:User {account: 'zhangsan'}), (b:Book {isbn: '9781234567890'})
CREATE (u)-[:BORROWED {borrow_date: date('2024-06-01')}]->(b);16.3 Python后端开发 #
使用neo4j官方驱动连接数据库,实现基本的增删查改操作。
- driver:Neo4j官方Python驱动的连接对象。
- session:数据库会话对象,管理一次数据库操作。
16.3.1 安装驱动 #
# 使用pip安装Neo4j官方Python驱动
pip install neo4j16.3.2 连接数据库示例 #
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 使用with语句创建一个数据库会话,确保会话用完后自动关闭
with driver.session() as session:
# 执行Cypher查询,查找前5本图书的标题
result = session.run("MATCH (b:Book) RETURN b.title LIMIT 5")
# 遍历查询结果中的每一条记录
for record in result:
# 打印每本书的标题
print(record["b.title"])
16.4 功能实现:借书、还书、推荐 #
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 从one.py中导入借书、还书、推荐函数
from one import borrow_book, return_book, recommend_books
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 初始化数据库,创建测试用户和图书
def initialize_db():
"""初始化数据库,创建测试用户和图书"""
# 定义需要依次执行的Cypher语句列表
cyphers = [
# 删除所有节点及其关系
"MATCH (n) DETACH DELETE n",
# 创建4个用户节点
"""
CREATE
(u1:User {account: 'user001', name: '张三'}),
(u2:User {account: 'user002', name: '李四'}),
(u3:User {account: 'user003', name: '王五'}),
(u4:User {account: 'user004', name: '赵六'})
""",
# 创建6本图书节点
"""
CREATE
(b1:Book {isbn: 'isbn1', title: 'isbn1'}),
(b2:Book {isbn: 'isbn2', title: 'isbn2'}),
(b3:Book {isbn: 'isbn3', title: 'isbn3'}),
(b4:Book {isbn: 'isbn4', title: 'isbn4'}),
(b5:Book {isbn: 'isbn5', title: 'isbn5'}),
(b6:Book {isbn: 'isbn6', title: 'isbn6'})
""",
# 创建初始借阅记录(user001、user002各借isbn1、isbn2)
"""
MATCH (u:User), (b:Book)
WHERE u.account IN ['user001', 'user002']
AND b.isbn IN ['isbn1', 'isbn2']
CREATE (u)-[:BORROWED {borrow_date: date()}]->(b)
""",
]
# 打开数据库会话,指定数据库为books
with driver.session(database="books") as session:
# 依次执行每条Cypher语句
for cypher in cyphers:
session.run(cypher)
# 打印初始化完成提示
print("数据库初始化完成!")
# 借书:为指定用户和图书创建BORROWED关系,记录借阅日期
def borrow_book(account, isbn):
# 定义Cypher语句,查找用户和图书节点并创建借阅关系
cypher = """
MATCH (u:User {account: $account}), (b:Book {isbn: $isbn})
CREATE (u)-[:BORROWED {borrow_date: date()}]->(b)
"""
# 打开数据库会话,指定数据库为books
with driver.session(database="books") as session:
# 执行Cypher语句,传入参数
session.run(cypher, account=account, isbn=isbn)
# 还书:为指定用户和图书的BORROWED关系设置归还日期
def return_book(account, isbn):
# 定义Cypher语句,查找借阅关系并设置归还日期
cypher = """
MATCH (u:User {account: $account})-[r:BORROWED]->(b:Book {isbn: $isbn})
SET r.return_date = date()
"""
# 打开数据库会话,指定数据库为books
with driver.session(database="books") as session:
# 执行Cypher语句,传入参数
session.run(cypher, account=account, isbn=isbn)
# 推荐:基于协同过滤,推荐与目标用户兴趣相似的其他用户借阅过的图书
def recommend_books(account):
# 定义Cypher语句,查找推荐图书及推荐理由
cypher = """
MATCH (u1:User {account: $account})-[:BORROWED]->(b:Book)<-[:BORROWED]-(u2:User),
(u2)-[:BORROWED]->(rec:Book)
WHERE NOT (u1)-[:BORROWED]->(rec)
RETURN rec.title AS 推荐书籍, count(*) AS 推荐理由
ORDER BY 推荐理由 DESC LIMIT 5
"""
# 打开数据库会话,指定数据库为books
with driver.session(database="books") as session:
# 执行Cypher语句,传入参数
result = session.run(cypher, account=account)
# 遍历结果,打印推荐书籍及推荐理由
for record in result:
print(record["推荐书籍"], record["推荐理由"])
# 显示当前借阅状态
def show_borrowing_status():
"""显示当前借阅状态"""
# 定义Cypher语句,查找所有未归还的借阅关系
cypher = """
MATCH (u:User)-[r:BORROWED]->(b:Book)
WHERE r.return_date IS NULL
RETURN u.account AS 用户账号, u.name AS 姓名,
b.title AS 图书, r.borrow_date AS 借阅日期
ORDER BY 借阅日期
"""
# 打开数据库会话,指定数据库为books
with driver.session(database="books") as session:
# 执行Cypher语句
result = session.run(cypher)
# 打印标题
print("\n当前借阅状态:")
print("-" * 50)
# 遍历结果,逐条打印借阅信息
for record in result:
print(
f"{record['姓名']}({record['用户账号']}) 正在借阅《{record['图书']}》"
f"(借于 {record['借阅日期']})"
)
# 主程序入口
if __name__ == "__main__":
try:
# 1. 初始化数据库
initialize_db()
# 2. 借书操作
borrow_book("user003", "isbn3") # 王五借阅《isbn3》
borrow_book("user004", "isbn4") # 赵六借阅《isbn4》
# 3. 还书操作
return_book("user001", "isbn1") # 张三归还《isbn1》
# 4. 推荐系统
print("\n=== 第一次推荐 ===")
recommend_books("user001")
# 5. 更多借阅
borrow_book("user001", "isbn5") # 张三借阅《isbn5》
borrow_book("user002", "isbn6") # 李四借阅《isbn6》
# 6. 查看最终状态
show_borrowing_status()
# 7. 最终推荐
print("\n=== 最终推荐 ===")
recommend_books("user003")
finally:
# 关闭驱动连接
driver.close()
print("\n数据库连接已关闭")17. 知识图谱构建 #
掌握知识图谱的基本原理、实体关系抽取、构建与查询应用
17.1 什么是知识图谱 #
知识图谱(Knowledge Graph)是一种以图结构存储和表达知识的方式,将现实世界中的实体(如人物、地点、事件)及其关系以节点和边的形式组织起来。它广泛应用于搜索引擎、智能问答、推荐系统等领域。
- 知识图谱(Knowledge Graph):用图结构表达实体及其关系的知识库。
- 三元组(Triple):实体-关系-实体的结构,如(爱因斯坦,出生于,德国)。
- 实体(Entity):现实世界中的对象,如人物、地点、机构等。
- 关系(Relation):实体之间的联系,如“出生于”“就读于”。
知识图谱示意:
[人物] --出生于--> [地点]
[人物] --就读于--> [学校]知识图谱的核心是“实体-关系-实体”三元组(Triple)。
17.2 实体关系抽取 #
实体关系抽取是从文本或结构化数据中识别出实体及其之间的关系。常用方法包括:
- 基于规则的抽取(如正则表达式)
- 基于机器学习的抽取(如命名实体识别NER)
- 实体关系抽取:从文本中识别出实体及其关系的过程。
- 正则表达式:用于文本模式匹配的工具。
- NER(命名实体识别):自动识别文本中的专有名词。
示例:正则抽取三元组
import re
# 定义待抽取的文本
text = "爱因斯坦出生于德国。"
# 定义正则表达式,匹配“某人出生于某地”
pattern = r"(\w+)出生于(\w+)"
# 在文本中查找匹配
match = re.search(pattern, text)
if match:
print("实体1:", match.group(1)) # 输出:爱因斯坦
print("关系: 出生于")
print("实体2:", match.group(2)) # 输出:德国实际项目中可结合NLP工具(如spaCy、HanLP)提升抽取效果。
17.3 构建知识图谱 #
将抽取到的三元组导入Neo4j,构建知识图谱。
- MERGE:Cypher中的关键字,查找或创建节点/关系,防止重复。
Cypher导入三元组示例
// 假设三元组为(爱因斯坦,出生于,德国)
MERGE (e1:Person {name: '爱因斯坦'})
MERGE (e2:Place {name: '德国'})
MERGE (e1)-[:BORN_IN]->(e2);Python批量导入示例
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 从one.py中导入借书、还书、推荐函数
from one import borrow_book, return_book, recommend_books
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
# 定义三元组列表,每个三元组包含(头实体,关系,尾实体)
triples = [("爱因斯坦", "出生于", "德国"), ("爱因斯坦", "就读于", "苏黎世联邦理工学院")]
# 遍历三元组列表
for h, r, t in triples:
# 构建Cypher语句,MERGE用于查找或创建节点和关系,防止重复
cypher = f"""
MERGE (h:Entity {{name: '{h}'}})
MERGE (t:Entity {{name: '{t}'}})
MERGE (h)-[:{r.replace(' ', '_').upper()}]->(t)
"""
# 打开数据库会话,指定数据库为books
with driver.session(database="books") as session:
# 执行Cypher语句,将三元组导入Neo4j
session.run(cypher)
建议为不同类型的实体(如人物、地点、机构)设置不同的标签。
17.4 知识查询应用 #
知识图谱支持灵活的查询和推理,常见应用包括:
- 查询某实体的属性或关系
- 查找实体之间的路径
智能问答与推荐
shortestPath:Cypher中的最短路径查询函数。
示例:查询某人出生地
// 查询名为“爱因斯坦”的人物的出生地
MATCH (p:Person)-[:BORN_IN]->(c:Place) WHERE p.name = '爱因斯坦' RETURN c.name;示例:查找两实体间的最短路径
// 查询“爱因斯坦”与“苏黎世联邦理工学院”之间的最短路径
MATCH p=shortestPath((a:Entity {name:'爱因斯坦'})-[*]-(b:Entity {name:'苏黎世联邦理工学院'}))
RETURN p;知识图谱可与自然语言处理、推荐系统等结合,发挥更大价值。
18. Neo4j 日期时间处理指南 #
本章全面讲解Neo4j中处理日期时间的现代方法,涵盖原生函数和APOC扩展的最佳实践。
18.1 日期时间处理概述 #
现代Neo4j(5.x+版本)提供了两种时间处理方式:
原生日期时间函数(推荐优先使用)
- 内置于Cypher,无需额外安装
- 支持时区、格式化等高级特性
- 性能更优
APOC扩展函数
- 提供补充功能
- 需要安装APOC插件
- 部分旧函数已弃用
18.2 原生日期时间函数 #
18.2.1 时间点创建 #
// 创建带时区的日期时间
RETURN datetime('2024-06-01T12:00:00[Asia/Shanghai]') AS zonedDateTime
// 通过组件创建
RETURN datetime({year:2024, month:6, day:1, hour:12,
timezone:'Asia/Shanghai'}) AS customDateTime18.2.2 时间戳转换 #
// 获取当前时间戳(毫秒)
RETURN timestamp() AS currentTimestamp
// 时间戳转日期时间
RETURN datetime({epochmillis:1717214400000}) AS fromTimestamp
// 日期时间转时间戳
RETURN datetime().epochMillis AS toTimestamp18.2.3 时间计算 #
// 时间加减
RETURN datetime() + duration({days:3}) AS futureDate
// 时间差计算
WITH datetime() AS now, datetime() + duration({hours:2}) AS later
RETURN duration.between(now, later) AS duration18.3 APOC日期函数(现代用法) #
18.3.1 时间格式化 #
// 格式化输出(替代旧的apoc.date.format)
RETURN apoc.temporal.format(datetime(), 'yyyy-MM-dd HH:mm:ss') AS formatted18.3.2 字符串解析 #
RETURN datetime('2024-06-01T12:00:00') AS parsedDateTime18.4 跨语言调用示例 #
from neo4j import GraphDatabase
# 导入neo4j官方驱动包
from neo4j import GraphDatabase
# 设置Neo4j数据库的连接地址
uri = "bolt://localhost:7687"
# 设置认证信息(用户名和密码)
auth = ("neo4j", "12345678")
# 创建数据库驱动对象
driver = GraphDatabase.driver(uri, auth=auth)
def query_events(driver):
with driver.session(database="first") as session:
# 查询今日事件(使用原生函数)
result = session.run(
"""
MATCH (e:Event)
WHERE date(e.time) = date()
RETURN e.name, e.time
"""
)
for record in result:
print(f"{record['e.name']} at {record['e.time']}")
# 使用APOC格式化输出
result = session.run(
"""
MATCH (e:Event)
RETURN e.name,
apoc.temporal.format(e.time, 'yyyy-MM-dd HH:mm') AS time
LIMIT 5
"""
)
for record in result:
print(f"{record['e.name']} at {record['time']}")
query_events(driver)
测试数据
// 插入今天的事件
CREATE (:Event {name: '会议', time: datetime()});
// 插入昨天的事件
CREATE (:Event {name: '昨日回顾', time: datetime() - duration({days:1})});
// 插入明天的事件
CREATE (:Event {name: '明日计划', time: datetime() + duration({days:1})});
// 插入指定时间的事件
CREATE (:Event {name: '发布会', time: datetime('2024-06-01T09:00:00')});
// 插入带时区的事件
CREATE (:Event {name: '全球同步', time: datetime('2024-06-01T20:00:00+08:00[Asia/Shanghai]')});18.6 最佳实践建议 #
- 优先使用原生函数:性能更好,兼容性更强
- 明确指定时区:避免时区混淆问题
- ISO 8601格式:使用
YYYY-MM-DDTHH:MM:SS格式最可靠 - APOC用于补充:仅当原生函数无法满足需求时使用
- 测试边界情况:特别注意跨日、跨月、闰秒等情况
18.7 版本兼容说明 #
| 功能类型 | Neo4j 4.x | Neo4j 5.x | 备注 |
|---|---|---|---|
| 原生日期函数 | ✓ | ✓ | 推荐使用 |
| apoc.date.* | ✓ | 部分弃用 | 逐渐被替代 |
| apoc.temporal.* | ❌ | ✓ | 现代APOC时间处理 |
提示:运行
RETURN apoc.version()可查看APOC版本,建议使用APOC 5.x+版本