1. RAG系统评估 #
在AI产品开发过程中,通常会先实现一个基础版本(baseline),随后根据实际测试和反馈不断迭代优化。对于RAG(Retrieval-Augmented Generation)系统而言,科学的评估机制不仅是衡量系统优劣的关键,更是后续改进和升级的方向指引。因此,如何系统性地评估RAG模型的表现,成为项目落地过程中的核心环节。
2. RAG 系统评估的核心维度与方法 #
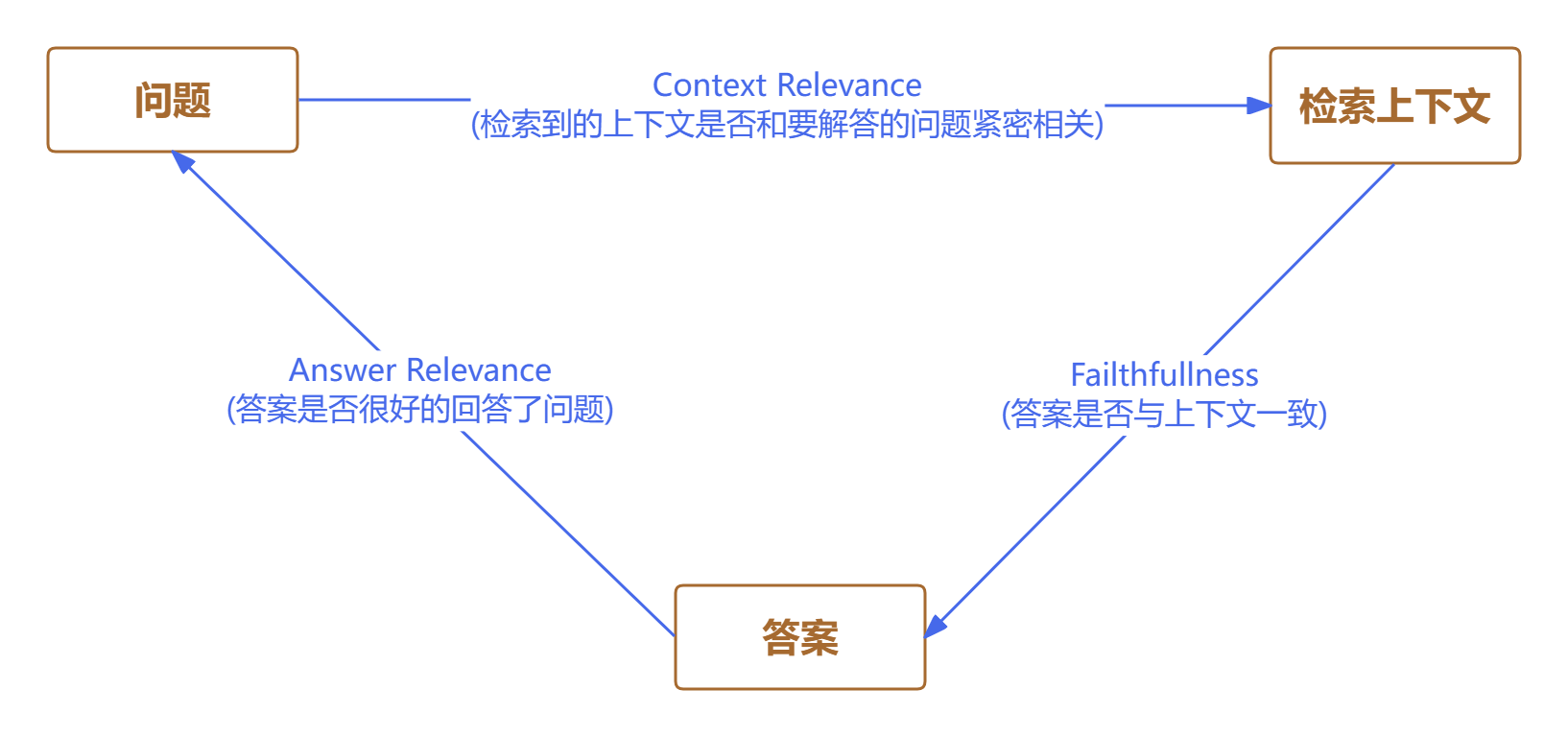
在本节中,我们将探讨如何科学地评判一个基于检索增强生成(RAG, Retrieval-Augmented Generation)系统的表现。首先,简要回顾一下 RAG 的基本流程:用户提出问题,系统检索相关资料作为参考,然后大语言模型结合这些资料生成最终答案。整个过程可以抽象为“提问—检索—生成”三步走。RAG 的评估,正是围绕这三者之间的内在联系展开。
2.1. 检索内容的相关性 #
首先要考察的是,系统检索到的参考资料是否真正贴合用户的问题。理想情况下,检索结果应当紧密围绕提问展开,涵盖解答所需的关键信息。例如,假如用户询问“如何预防高血压?”,系统检索到的内容应包括饮食、运动等预防措施,而不是泛泛而谈的健康常识。这个维度主要衡量检索内容的针对性和实用性。
2.2. 生成答案的事实一致性 #
其次,需要评估生成的答案是否忠实于检索到的资料。换句话说,答案中的事实是否能够在参考资料中找到依据,避免凭空捏造。例如,若检索内容提到“高血压患者应减少盐分摄入”,而生成的答案却建议“多吃甜食”,这就属于事实不一致。事实一致性是确保系统输出可靠性的关键标准。
2.3. 答案与问题的直接相关性 #
最后,还要判断生成的答案是否直接回应了用户的问题,并且内容是否完整、无遗漏。与此同时,还要避免答案中夹杂无关或冗余的信息。例如,用户问“高血压的常见症状有哪些?”,理想答案应列举具体症状,而不是展开高血压的成因或治疗方法。这个维度关注答案的针对性和精炼度。
2.4 案例分析 #
假设用户提问:“请简述地球自转的影响。”
- 检索到的资料A:“地球自转导致昼夜交替,并影响全球风系分布。”
- 检索到的资料B:“太阳系中有八大行星,地球是其中之一。”
生成答案1:“地球自转使得地球表面出现昼夜变化,还影响了风的流向。”
生成答案2:“地球是太阳系的第三颗行星。”
分析:
- 答案1与资料A事实一致,且直接回应了问题,属于高质量输出。
- 答案2虽然与资料B内容一致,但没有回答自转的影响,相关性较差。
- 资料A与问题高度相关,资料B则无关。
2.5 评估方式 #
在实际操作中,相关性和一致性的判断往往需要较强的语义理解能力。人工评估虽然精确,但耗时且成本较高。近年来,借助大语言模型自动化评估相关性和事实一致性,已成为一种高效的替代方案,能够在保证准确性的同时大幅提升评估效率。
3. 评估流程 #
在明确了RAG系统的评测标准后,完整的评估流程通常可以分为三个主要阶段。
首先,需要准备一套专门用于评测RAG系统的测试集。这一数据集应包含一系列具有代表性的问题,以及每个问题对应的权威参考答案。例如,在医疗问答场景下,测试集可以由常见的健康咨询问题及其标准医学解答组成。
第二步,需明确具体的评估指标。这些指标可以是前文提到的RAG评测通用标准,也可以根据实际业务需求进行细化和扩展。常见的评估维度包括答案的准确率、相关性、覆盖度等。
最后,进入评测执行阶段。此时,将测试集中的问题逐一输入到RAG系统中,系统会返回检索到的上下文和生成的答案。评测工具会自动对比系统输出与标准答案,计算各项指标的得分。整个流程的核心在于如何科学、客观地量化系统的表现,从而为后续优化提供数据支撑。
通过这三步,开发者能够系统性地评估RAG系统在特定场景下的实际效果,并据此持续迭代提升模型性能。
4. RAG评测工具 #
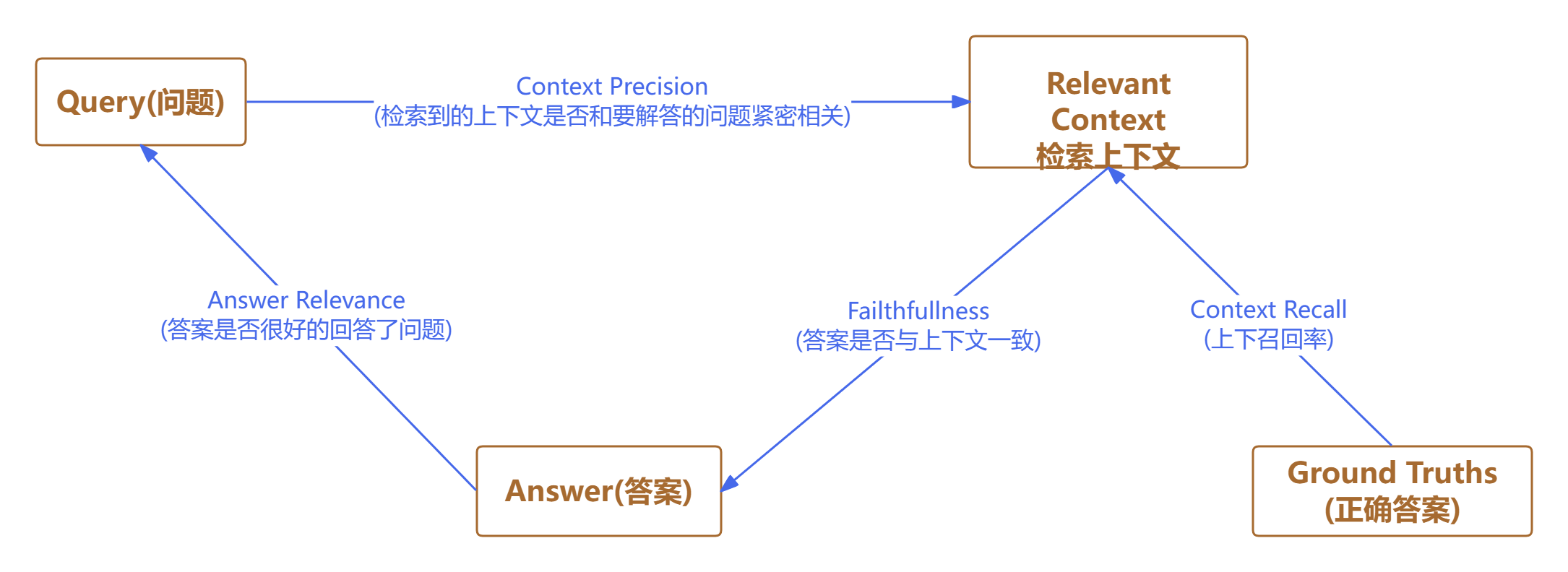
RAGAs于2023年发布,旨在实现自动化的RAG系统评测。其初衷是打造一个无需人工参考答案的无监督评估体系,从而大幅降低人工标注的工作量。不过,随着版本的迭代,部分最新指标已引入了人工标准答案,以提升评测的准确性。显然,拥有标准答案有助于获得更为可靠的评估结果。
RAGAs的另一大亮点在于充分利用大语言模型(LLM)的推理能力,综合考察问题、答案与上下文三者之间的关联性,并据此计算各项评测指标。
4.1 忠实性指标 #
Faithfulness:
衡量生成答案与给定上下文之间的事实一致性。忠实度得分是基于答案和检索到的上下文计算出来的,答案的评分范围在0到1之间,分数越高越好。
4.1.1 公式说明 #
忠实度得分计算公式:
$$ \text{Faithfulness score} = \frac{\text{生成答案中能从上下文推断出的事实数量}}{\text{生成答案中的事实总数}} $$
计算步骤
拆分生成答案中的事实
首先,将生成的答案拆分成若干个独立的事实(通常是句子或陈述)。每个事实都被视为一个需要验证的点。逐条验证事实
对于生成答案中的每一个事实,判断它是否能够从检索到的上下文中推断出来。也就是说,看看上下文中是否有足够的信息来支持这个事实。统计可推断的事实数量
统计有多少个事实是可以被上下文支持或推断出来的。计算总事实数
统计生成答案中一共包含了多少个事实。代入公式计算得分
用“可被推断的事实数量”除以“事实总数”,得到忠实度分数。分数范围在0到1之间,分数越高,说明生成答案与上下文的一致性越好。
举例说明
假设生成的答案有3个事实:
- 事实1:A
- 事实2:B
- 事实3:C
经过验证,发现A和C可以从上下文中找到依据,B找不到依据。
那么:
- 能被推断出的事实数量 = 2
- 事实总数 = 3
代入公式: $$ \text{Faithfulness score} = \frac{2}{3} \approx 0.67 $$
总结:
该分数反映了生成答案与上下文之间的事实一致性,分数越高,说明答案越忠实于上下文。
4.1.2 例子说明 #
提示(Hint):
- 问题(Question): 爱因斯坦何时何地出生?
上下文(Context): 阿尔伯特·爱因斯坦(生于1879年3月14日)是一位德国出生的理论物理学家,被广泛认为是有史以来最伟大、最有影响力的科学家之一。
高忠实度答案(High faithfulness answer):
爱因斯坦于1879年3月14日出生在德国。
(与上下文完全一致,事实准确)低忠实度答案(Low faithfulness answer):
爱因斯坦于1879年3月20日出生在德国。
(日期与上下文不符,事实有误)
总结:
忠实度分数越高,说明生成的答案与上下文的事实越一致,系统的表现越好。
4.2 回答相关性 #
Answer relevance:
答案相关性的评估指标旨在评价生成的答案与给定提示(问题)的相关程度。如果答案不完整或者包含无关信息,则会被赋予较低的分数。这个指标是通过问题和答案来计算的,分值范围在0到1之间,得分越高说明答案与问题的相关性越好。
4.2.1 公式内容 #
$$ AR = \frac{1}{n} \sum_{i=1}^{n} \text{sim}(q, q_i) $$
其中,
- $ q $:原始问题
- $ q_i $:由生成答案反推得到的第 $i$ 个潜在问题
- $\text{sim}(q, q_i)$:原始问题与第 $i$ 个潜在问题之间的语义相似度(通常用向量余弦相似度等方法计算)
- $ n $:潜在问题的总数
计算步骤
生成潜在问题
首先,根据生成的答案,利用大语言模型等方法,反向生成出若干个与答案相关的潜在问题($ q_1, q_2, ..., q_n $)。这些问题应该覆盖答案中的所有关键信息点。计算语义相似度
对每一个潜在问题 $ q_i $,计算它与原始问题 $ q $ 之间的语义相似度 $\text{sim}(q, q_i)$。
语义相似度可以用 embedding 向量的余弦相似度等方式衡量,分数一般在0到1之间,越高表示越相似。求平均值
将所有潜在问题与原始问题的相似度分数相加,然后除以潜在问题的数量 $ n $,得到最终的答案相关性分数 $ AR $。
4.2.2 举例说明 #
假设根据答案反推得到了3个潜在问题,分别与原始问题的相似度为0.8、0.7、0.9。
则: $$ AR = \frac{1}{3} (0.8 + 0.7 + 0.9) = \frac{2.4}{3} = 0.8 $$
总结:
该分数反映了生成答案与原始问题的相关性,分数越高,说明答案对原始问题的覆盖和匹配程度越好。
例子说明
提示(Hint):
- 问题(Question): 法国在哪里?它的首都是什么?
低相关性答案(Low relevance answer): 法国位于西欧。
(只回答了部分问题,遗漏了首都信息,相关性较低)高相关性答案(High relevance answer): 法国位于西欧,巴黎是它的首都。
(完整回答了所有问题,相关性高)
总结:
答案相关性分数越高,说明生成的答案对原始问题的覆盖和匹配程度越好,系统的表现也越优。
4.3 上下文精度 #
Context Precision:
上下文精度衡量上下文中所有相关的真实信息是否被排在了较高的位置。理想情况下,所有相关的信息块都应该出现在排名的最前面。这个指标是根据问题和上下文来计算的,数值范围在0到1之间,分数越高表示精确度越好。
4.3.1 公式内容 #
$$ \text{Context Precision@k} = \frac{\sum \text{precision@k}}{\text{top K 结果中相关信息块的总数}} $$
$$ \text{Precision@k} = \frac{\text{前k个中真正相关的信息块数(true positives@k)}}{\text{前k个中所有信息块数(true positives@k + false positives@k)}} $$
其中,k 是上下文信息块的总数。
计算步骤
确定上下文信息块的总数 $k$
检索系统返回的上下文信息块总数为 $k$。依次计算每个位置的 Precision@k
- 对于每个位置 $k$(从1到总数),计算前 $k$ 个信息块中有多少是真正相关的(true positives),有多少是不相关的(false positives)。
- 计算公式:
$$ \text{Precision@k} = \frac{\text{前k个中真正相关的信息块数}}{\text{前k个中所有信息块数}} $$
将所有位置的 Precision@k 相加
- 把每个 $k$ 位置的 Precision@k 累加起来。
归一化(取平均)
- 用上面累加的和除以相关信息块的总数,得到最终的 Context Precision@k。
假设检索返回了3个上下文信息块,相关性如下:
| 位置 | 是否相关(True/False) |
|---|---|
| 1 | True |
| 2 | False |
| 3 | True |
计算每个位置的 Precision@k:
- Precision@1 = 1/1 = 1.0
- Precision@2 = 1/2 = 0.5
- Precision@3 = 2/3 ≈ 0.67
假设有2个相关信息块(第1和第3个),则 Context Precision@k 计算为: $$ \text{Context Precision@k} = \frac{1.0 + 0.67}{2} = 0.835 $$
总结:
Context Precision@k 衡量的是相关信息块在检索结果中的排序情况。分数越高,说明相关信息块越集中在前面,检索系统的精度越高。
4.3.2 例子说明 #
问题: 法国在哪里,它的首都是什么?
高上下文精度示例:
- 「法国位于西欧,其首都是巴黎,巴黎以其埃菲尔铁塔、卢浮宫等著名地标而闻名于世。」
- 「法国拥有多样的地貌,包括阿尔卑斯山、比利牛斯山、地中海海岸线以及广阔的葡萄园。巴黎不仅是法国的政治中心,也是世界著名的文化和艺术之都。」
- 这些与问题高度相关的信息都排在了前面,精度高。
低上下文精度示例:
- 「法国的地理环境多样,有高山、平原和海岸线,是欧洲重要的农业和旅游国家。」
- 「巴黎是法国的首都,以其丰富的历史和文化遗产吸引着全球游客。」
- 相关信息分散在后面,精度较低。
总结:
上下文精度分数越高,说明与问题最相关的信息越靠前,检索系统的表现越好。
4.4 上下文召回率 #
Context Recall:
上下文召回率用来衡量检索到的上下文与被标注为事实真相的标准答案之间的一致性。它根据标准答案和检索到的上下文来计算,数值范围在0到1之间,数值越高表示性能越好。
为了从事实真相的答案中估计上下文召回率,需要分析答案中的每个句子是否可以归因于检索到的上下文。在理想情况下,事实真相答案中的所有句子都应该能够对应到检索到的上下文中。
4.4.1 上下文召回率的计算公式 #
$$ \text{context recall} = \frac{\text{可以归因于上下文的标准答案句子数}}{\text{标准答案中的句子总数}} $$
公式内容
$$ \text{context recall} = \frac{\text{可以归因于上下文的标准答案句子数}}{\text{标准答案中的句子总数}} $$
计算步骤
拆分标准答案
首先,将标准答案(通常是人工标注的正确答案)拆分成若干个独立的句子或事实点。判断每个句子是否能在上下文中找到依据
对于标准答案中的每一个句子,检查检索到的上下文信息,判断该句子是否可以从上下文中推断出来(即上下文中有足够的信息支持该句子)。统计可归因于上下文的句子数量
统计有多少个标准答案中的句子能够在上下文中找到依据。计算标准答案中的句子总数
统计标准答案一共包含多少个句子。代入公式计算召回率
用“可以归因于上下文的标准答案句子数”除以“标准答案中的句子总数”,得到上下文召回率。分数范围在0到1之间,分数越高,说明检索到的上下文对标准答案的覆盖越全面。
举例说明
假设标准答案有3个句子:
- 句子1:A
- 句子2:B
- 句子3:C
经过检查,发现A和C可以在上下文中找到依据,B找不到。
那么:
- 可以归因于上下文的标准答案句子数 = 2
- 标准答案中的句子总数 = 3
代入公式: $$ \text{context recall} = \frac{2}{3} \approx 0.67 $$
总结:
上下文召回率反映了检索到的上下文对标准答案的覆盖程度,分数越高,说明检索系统越能找到与标准答案相关的信息。
4.4.2 例子说明 #
问题: 法国的首都是什么?
标准答案: 巴黎是法国的首都。
高上下文召回率示例:
- “法国是欧洲的一个国家。巴黎是法国的首都。”
- 这些上下文能够完整覆盖标准答案的所有关键信息,召回率高。
低上下文召回率示例:
- “法国是欧洲的一个国家,以其丰富的历史和文化著称。”
- 这些上下文没有包含“巴黎是法国的首都”这一关键信息,召回率较低。
总结:
上下文召回率分数越高,说明检索到的上下文对标准答案的覆盖越全面,系统的表现也越好。
4.5 系统评估 #
检索器(Retriever)
Context Precision(上下文精度)
- 作用:评估检索到的上下文信息的质量。
- 说明:如果相关信息都排在检索结果的前面,精度就高,说明检索器能把最有用的信息优先提供给生成器。
Context Recall(上下文召回率)
- 作用:衡量检索到的上下文信息的完整性。
- 说明:如果所有应该被检索到的相关信息都被找到了,召回率就高,说明检索器没有遗漏重要内容。
生成器(Generator)
Faithfulness(忠实度)
- 作用:衡量生成答案中是否存在“幻觉”或虚假内容。
- 说明:忠实度高,说明生成的答案与检索到的上下文事实一致,没有编造内容。
Answer Relevance(答案相关性)
- 作用:衡量生成答案对问题的直接性和紧扣程度。
- 说明:相关性高,说明答案紧扣问题核心,没有跑题或答非所问。
综合评分
- 最终的 RAGAS 得分 是以上各项指标得分的加权或平均值。
- 简单来说,这些指标共同用来综合评价一个RAG系统整体的性能,既考察检索环节,也考察生成环节,帮助开发者发现系统的优势和不足。
总结:
通过这四个核心指标,RAGAS 能够全面、系统地评估RAG系统的检索和生成能力,为系统优化和迭代提供科学依据。
评测结束后,需根据结果采取相应措施。若得分理想,可直接上线部署;若存在不足,则需分析bad case,针对性优化。例如,若检索效果不佳,可尝试更换embedding模型或调整检索策略;若生成答案有误,可优化提示词或更换大模型。每次调整后都应重新评测,持续迭代,直至系统表现达到预期,最终实现系统升级与部署。
5. 代码实现 #
# 导入LangChain的基础LLM类
# `LLM` 是 LangChain 框架中所有大语言模型 (Large Language Model) 的基类,定义了与各种语言模型交互的统一接口和基础功能。
from langchain.llms.base import LLM
# 导入OpenAI客户端
from openai import OpenAI
# 导入HuggingFace的Embedding封装
# `HuggingFaceEmbeddings` 是 LangChain 中封装 Hugging Face 预训练模型的嵌入生成工具,用于将文本转换为向量表示
from langchain_huggingface import HuggingFaceEmbeddings
# 导入Chroma向量数据库相关类
from langchain_chroma import Chroma
# 导入ChromaDB客户端
import chromadb
# 导入HuggingFace的Dataset
# `Dataset` 是 Hugging Face `datasets` 库中的核心类,提供了一个高效、内存优化的容器,用于存储和操作结构化数据(如文本、图像等)
from datasets import Dataset
# 导入ragas评测指标
from ragas.metrics import (
faithfulness, # 忠实度
answer_relevancy, # 答案相关性
context_recall, # 上下文召回率
context_precision, # 上下文精确率
)
# 导入ragas评测主方法和配置
from ragas import evaluate, RunConfig
# 导入pydantic的PrivateAttr用于私有属性
from pydantic import PrivateAttr
# 定义本地LLM推理类,继承自LangChain的LLM
class LangchainLLM(LLM):
# 定义私有属性_client和_model用于存储OpenAI客户端和模型名
_client = PrivateAttr() # 存储OpenAI客户端
_model = PrivateAttr() # 存储模型名称
# 初始化方法,设置API地址、密钥和模型名
def __init__(
self,
base_url="http://localhost:11434/v1/", # 本地API地址
api_key="llama2", # 本地API密钥
model="llama2", # 本地模型名称
):
# 调用父类初始化方法
super().__init__()
# 创建OpenAI客户端 本地API地址和密钥
self._client = OpenAI(base_url=base_url, api_key=api_key)
# 保存模型名称
self._model = model
# 实现LLM的调用方法
# **kwargs 是 "keyword arguments" 的缩写,它允许函数接收任意数量的关键字参数,这些参数会被收集到一个字典中
def _call(self, prompt, stop=None, run_manager=None, **kwargs):
# 打印推理请求日志,显示前50个字符
print(f"[LLM] 推理请求: {prompt[:50]}...")
# 调用OpenAI客户端生成completion
completion = self._client.completions.create(
model=self._model, # 模型名称
prompt=prompt, # 提示词
temperature=kwargs.get("temperature", 0.1), # 温度
top_p=kwargs.get("top_p", 0.9), # 上采样
max_tokens=kwargs.get("max_tokens", 4096), # 最大令牌数
stream=kwargs.get("stream", False), # 流式输出 是否流式输出
)
# 打印推理结果日志,显示前50个字符
print(f"[LLM] 推理结果: {completion.choices[0].text[:50]}...")
# 返回生成的文本
return completion.choices[0].text
# 返回模型类型属性
@property
def _llm_type(self):
# 返回模型名称
return self._model
# 本地Embedding封装类
class LocalEmbedding:
# 初始化方法,加载HuggingFace的句向量模型
def __init__(self, model_name="all-MiniLM-L6-v2"):
# 创建HuggingFaceEmbeddings对象
self.embedding = HuggingFaceEmbeddings(
model_name=model_name, # 模型名称
model_kwargs={"device": "cpu"}, # 设备
encode_kwargs={"normalize_embeddings": True}, # 归一化
)
# 获取embedding对象
def get(self):
# 返回embedding对象
return self.embedding
# RAG主流程封装类
class Rag:
# 初始化方法,设置数据库名、embedding、llm、prompt模板、chroma客户端
def __init__(
self,
db_name="product_db", # 数据库名称
embedding_model=None, # 嵌入模型
llm=None, # 语言模型
prompt_template=None, # 提示词模板
chroma_client=None, # 数据库客户端
):
# 打印初始化RAG流程日志
print(f"[RAG] 初始化,数据库名: {db_name}")
# 设置embedding模型,若未传入则使用默认
self.embedding_model = embedding_model or LocalEmbedding().get()
# 设置llm,若未传入则使用默认
self.llm = llm or LangchainLLM()
# 设置chroma客户端,若未传入则使用默认
self.chroma_client = chroma_client or chromadb.PersistentClient(
path="./chroma_db" # 数据库路径
)
# 创建Chroma数据库对象 数据库名称、嵌入模型、数据库客户端
self.db = Chroma(db_name, self.embedding_model, client=self.chroma_client)
# 设置售后场景的prompt模板,若未传入则使用默认
self.prompt_template = prompt_template or (
"你是电子产品售后服务助手,熟悉手机、电脑等产品的保修、维修、退换货等政策。"
"请根据提供的上下文信息context,专业、简明地回答用户的售后相关问题。"
"如果上下文没有相关信息,请回答[请联系品牌官方售后或客服]。\n"
'问题:{question}\n"{context}"\n答复:'
)
# 构建prompt方法
def build_prompt(self, question, context):
# 用实际问题和上下文替换模板中的占位符
return self.prompt_template.replace("{question}", question).replace(
"{context}", context
) # 替换上下文
# 检索相关上下文方法
def retrieve_context(self, query, top_k=3):
# 打印检索上下文日志
print(f"[RAG] 检索上下文: {query}")
# 从数据库中检索相似文档
docs = self.db.similarity_search(query, k=top_k)
# 构建上下文列表,每条前面加编号
context_list = [
f"上下文{i+1}: {doc.page_content} \n" for i, doc in enumerate(docs)
]
# 打印检索到的上下文数量日志
print(f"[RAG] 检索到{len(context_list)}条上下文")
# 返回拼接后的上下文字符串和上下文列表
return "\n".join(context_list), context_list
# 生成答案方法
def answer(self, question, top_k=3):
# 检索相关上下文
context_str, context_list = self.retrieve_context(question, top_k)
# 构建prompt
prompt = self.build_prompt(question, context_str)
# 打印最终prompt日志,显示前80个字符
print(f"[RAG] 构建的prompt: {prompt[:80]}...")
# 用invoke方法替换__call__,消除弃用警告
response = self.llm.invoke(prompt, stream=False)
# 打印生成的答案日志,显示前50个字符
print(f"[RAG] 生成答案: {response[:50]}...")
# 返回答案和上下文列表
return response, context_list
# 主流程入口函数
def main():
# 定义电子产品售后类型的问题列表
questions = [
"如何申请手机保修服务?",
"笔记本电脑电池鼓包怎么办?",
]
# 定义每个问题的标准答案
ground_truths = [
"您可携带购机发票和保修卡前往品牌授权售后服务中心,工程师检测后符合保修政策即可免费维修。",
"如发现笔记本电脑电池鼓包,请立即停止使用并联系品牌售后服务中心进行更换,切勿自行拆卸或继续充电。",
]
# 打印初始化RAG对象日志
print("[MAIN] 初始化RAG对象")
# 创建Rag对象
rag = Rag()
# 初始化答案和上下文列表
answers, contexts = [], []
# 遍历每个问题,生成答案和上下文
for q in questions:
# 打印当前处理的问题日志
print(f"[MAIN] 处理问题: {q}")
# 调用Rag对象生成答案和上下文
answer, context_list = rag.answer(q, top_k=3)
# 将答案添加到答案列表
answers.append(answer)
# 将上下文添加到上下文列表
contexts.append(context_list)
# 构建评测数据集字典
data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truth": ground_truths,
}
# 通过字典创建HuggingFace数据集对象
dataset = Dataset.from_dict(data)
# 打印ragas评测开始日志
print("[MAIN] 开始ragas评测...")
# 创建评测用的LLM对象
eval_llm = LangchainLLM()
# 创建评测用的embedding对象
eval_embedding = LocalEmbedding().get()
# 配置ragas评测参数 超时时间1200秒,记录重试次数
config = RunConfig(timeout=1200, log_tenacity=True)
# 调用ragas的evaluate方法进行评测
result = evaluate(
dataset=dataset, # 评测数据集
llm=eval_llm, # 评测用的LLM对象
embeddings=eval_embedding, # 评测用的embedding对象
metrics=[
context_precision, # 上下文精确率
context_recall, # 上下文召回率
faithfulness, # 忠实度
answer_relevancy, # 答案相关性
], # 评测指标
raise_exceptions=True, # 是否抛出异常
run_config=config, # 评测配置
)
# 将评测结果转为pandas DataFrame
df = result.to_pandas()
# 打印ragas评测结果日志
print("[MAIN] ragas评测结果:")
# 打印DataFrame结果
print(df)
# 插入测试数据到Chroma数据库的函数
def insert_test_data():
# 打印初始化Chroma数据库日志
print("[DB] 初始化Chroma数据库 product_db")
# 创建Chroma数据库对象
chromaClient = Chroma(
"product_db", # 数据库名称
LocalEmbedding().get(), # 嵌入模型
client=chromadb.PersistentClient(path="./chroma_db"), # 数据库客户端
)
# 定义测试数据列表,每条包含内容和元数据
test_docs = [
{
"content": "如需申请手机保修服务,请携带购机发票和保修卡前往品牌授权售后服务中心,工程师检测后符合保修政策即可免费维修。",
"meta": {"category": "手机保修"},
},
{
"content": "笔记本电脑电池出现鼓包属于安全隐患,请立即停止使用并联系品牌售后服务中心进行更换,切勿自行拆卸或继续充电。",
"meta": {"category": "电脑电池"},
},
{
"content": "电子产品自购买之日起享受7天无理由退货,15天内可换货,一年内享受免费保修服务,具体以品牌政策为准。",
"meta": {"category": "售后政策"},
},
{
"content": "如遇产品无法开机、屏幕碎裂等问题,请及时联系官方售后或客服,部分问题可能不在保修范围内。",
"meta": {"category": "常见问题"},
},
]
# 遍历每条测试数据,插入到Chroma数据库
for i, doc in enumerate(test_docs):
# 打印插入测试数据日志
print(f"[DB] 插入测试数据: {doc['meta']['category']}")
# 调用add_texts方法插入文本、元数据和ID
chromaClient.add_texts(
texts=[doc["content"]], metadatas=[doc["meta"]], ids=[f"test_doc_{i}"]
)
# 打印测试数据插入完成日志
print("[DB] 测试数据已插入 product_db。")
# 程序入口
if __name__ == "__main__":
# 运行主流程
main()